
So verwenden Sie Proxys für Web Scraping, ohne blockiert zu werden
Werfen Sie einen kurzen Blick
Der rationale und effektive Einsatz von Proxys hilft Ihnen beim Web-Scraping, Blockierungen zu vermeiden. Entdecken Sie Tipps, wie Sie Ihre Anonymität wahren und Daten reibungslos extrahieren können. Sind Sie bereit, Ihren Scraping-Prozess zu optimieren? Lesen Sie unseren Leitfaden und scrapen Sie noch heute intelligenter!
Web Scraping ist eine Technik zum Extrahieren von Daten aus Webseiten. Dabei werden Anfragen an Zielwebsites gesendet, ähnlich wie bei einem Browser. Dies ermöglicht den Abruf verschiedener Informationen wie Texte, Bilder und Links.
Web Scraping hat verschiedene Anwendungsgebiete:
-
E-Commerce: Erleichtert die Preisüberwachung und hilft Unternehmen und Verbrauchern, bessere Kaufentscheidungen zu treffen und wettbewerbsfähige Preise festzulegen.
-
Nachrichten: Ermöglicht die Aggregation verschiedener Quellen und bietet einen umfassenden Nachrichtenüberblick auf einer Plattform.
-
Lead-Generierung: Unterstützt Unternehmen bei der Gewinnung potenzieller Kunden durch die Extraktion relevanter Daten und die Optimierung des Marketings. Effektivität.
-
SEO: Dient zur Überwachung von Suchmaschinen-Ergebnisseiten und zur Optimierung von Website-Inhalten und -Strategien.
-
Finanzen: In Anwendungen wie Mint (USA) und Bankin' (Europa) ermöglicht es die Aggregation von Bankkonten für eine optimierte Verwaltung der persönlichen Finanzen.
-
Forschung: Hilft Einzelpersonen und Forschern, Datensätze zu erstellen, die sonst nicht zugänglich sind, und fördert so die akademische Forschung und datenbasierte Projekte.
Viele haben es jedoch satt, dass Web-Scraping-Projekte blockiert oder auf die schwarze Liste gesetzt werden. Tatsächlich genügt es, möglichst viele Best Practices zu befolgen, um einen erfolglosen Webdatenextraktionsprozess zu vermeiden.
Der Trick für erfolgreiches Web Scraping besteht darin, zu vermeiden, wie ein Roboter behandelt zu werden und die Anti-Bot-Systeme der Website zu umgehen. Dies liegt daran, dass die überwiegende Mehrheit der Websites Data Scraping nicht begrüßt und versucht, den Prozess zu blockieren.
Dieser Beitrag hilft Ihnen zu verstehen, welche verschiedenen Informationen Websites verwenden, um das Crawlen von Informationen zu verhindern, und welche Strategien Sie implementieren können, um diese Anti-Bot-Barrieren erfolgreich zu überwinden.
Die richtigen Proxys wählen
Websites erkennen Web Scraper in erster Linie durch die Überprüfung ihrer IP-Adressen und die Verfolgung ihres Verhaltens.
Wenn der Server ein ungewöhnliches Verhalten oder eine unwahrscheinliche Häufigkeit von Anfragen usw. von einem Benutzer feststellt, blockiert er diese IP-Adresse für den weiteren Zugriff auf die Website.
Hier kommt der Einsatz von ein Proxyserver kommt ins Spiel. Proxys ermöglichen Ihnen die Verwendung verschiedener IP-Adressen, um den Anschein zu erwecken, dass Ihre Anfragen aus der ganzen Welt kommen. Dies hilft, Erkennung und Blockierung zu vermeiden.
Um zu vermeiden, dass alle Anfragen von derselben IP-Adresse gesendet werden, wird die Verwendung eines IP-Rotationsdienstes empfohlen, der die tatsächliche IP-Adresse beim Crawlen der Daten verbirgt.
Um die Erfolgsquote zu erhöhen, sollte außerdem der richtige Proxy gewählt werden. Für anspruchsvollere Websites mit Anti-Crawl-Mechanismen eignen sich beispielsweise Residential Proxies besser.
Die Qualität Ihres Proxyservers kann den Erfolg Ihres Daten-Crawls stark beeinflussen. Daher lohnt es sich, in einen guten Proxyserver zu investieren.
Die Proxys von IPOasis unterstützen Unternehmen dabei, Web Scraping durchzuführen, ohne erkannt oder blockiert zu werden. Die Proxys von IPOasis überwinden geografische Beschränkungen, rotieren IP-Adressen und führen Scraping in großem Umfang durch, ohne den normalen Betrieb der Zielwebsite zu stören.
Mit über 80 Millionen realen Residential-IPs aus 195 Ländern bieten die Scraping-Proxys von IPOasis die nötige Flexibilität und Skalierbarkeit für jedes Web-Scraping-Projekt. Sie müssen sich nie wieder Sorgen machen, beim Sammeln öffentlicher Webdaten blockiert zu werden.
Darüber hinaus sind die Proxys von IPOasis auch zu Spitzenzeiten und in großem Umfang leistungsstark und stellen sicher, dass Kunden jederzeit die benötigten Proxys zur Verfügung haben. Vermeiden Sie Markierungen, indem Sie unbegrenzte Sitzungen nutzen und IP-Standorte so oft wie nötig ändern. Vertrauen Sie bei der Datenerfassung auf die Zuverlässigkeit und Effektivität von Scraping-Proxys.
Anfrageraten verwalten
-
Anfragen verlangsamen: Da Sie das Verhalten normaler Nutzer nachahmen müssen, vermeiden Sie es, eine große Anzahl von Anfragen in sehr kurzer Zeit zu senden. Kein echter Nutzer besucht eine Website auf diese Weise, und dieses Verhalten wird durch Anti-Crawling-Techniken leicht erkannt. Wenn menschliche Nutzer beispielsweise typischerweise einige Sekunden zwischen den Seitenladevorgängen warten, sollten Sie die Anfragen entsprechend verteilen. Eine gute Faustregel ist, die Anzahl der Anfragen pro Minute je nach Website-Art zu begrenzen.
-
Randomisieren Sie das Anfrageintervall: Fügen Sie zufällige Verzögerungen zwischen den Anfragen ein, die von einigen Sekunden bis zu einigen Minuten reichen, um die Zufälligkeit zu erhöhen und eine Erkennung zu vermeiden. Dadurch ähneln Ihre Verkehrsmuster eher denen echter Nutzer, die möglicherweise unterschiedlich lange zwischen den Aktionen auf der Website verbringen. Sie können eine Programmierfunktion verwenden, um Zufallszahlen innerhalb eines Bereichs zu generieren und so die Zeitverzögerung zwischen den Anfragen festzulegen.
Spezielle Header festlegen
-
User-Agent-String: Der User-Agent-Header teilt der Website mit, auf welchen Browser und welches Betriebssystem der Nutzer zugreift. Eine Möglichkeit, diese Strategie flexibel anzuwenden, um Ihre Anfragen so aussehen zu lassen, als kämen sie von verschiedenen Browsern und Geräten, ist die Verwendung mehrerer User-Agent-Strings. Sie können beispielsweise die User-Agent-Strings für Chrome unter Windows, Firefox unter Mac und Safari unter iOS rotieren.
-
Der Referrer-Header: Der Referrer-Header ist Teil des HTTP-Headers. Er dient zur Identifizierung der Webseite, von der eine Anfrage ausgeht. Vereinfacht ausgedrückt: Wenn ein Browser von einer Webseite zu einer anderen navigiert, dient er zur Identifizierung der Webseite, von der die Anfrage ausgeht. Wenn ein Browser von einer Webseite (der Quellseite) zu einer anderen Webseite (der Zielseite) navigiert und eine Anfrage sendet, teilt der Referrer-Header der Zielseite mit, woher die Anfrage stammt. Durch die Einrichtung eines gültigen Referrers wirken Ihre Anfragen legitimer. Wenn Sie auf einer E-Commerce-Website nach einer Produktseite suchen, können Sie den Referrer so einstellen, dass er auf die Kategorieseite der Produktseite verweist. Diese Strategien helfen, Ihre Crawling-Aktivitäten zu verschleiern und eine stärkere menschliche Interaktion mit der Website zu ermöglichen. Dadurch wird das Risiko einer Auslösung von Anti-Bot-Systemen minimiert.
Verwenden Sie einen Headless-Browser
Ein Headless-Browser ist ein leistungsstarkes Tool für Web Scraping, ohne Anti-Bot-Systeme auszulösen. Im Gegensatz zu herkömmlichen Web-Scraping-Bibliotheken replizieren Headless-Browser wie Puppeteer oder Selenium das menschliche Surfverhalten, indem sie komplette Webseiten inklusive JavaScript und dynamischen Inhalten laden.
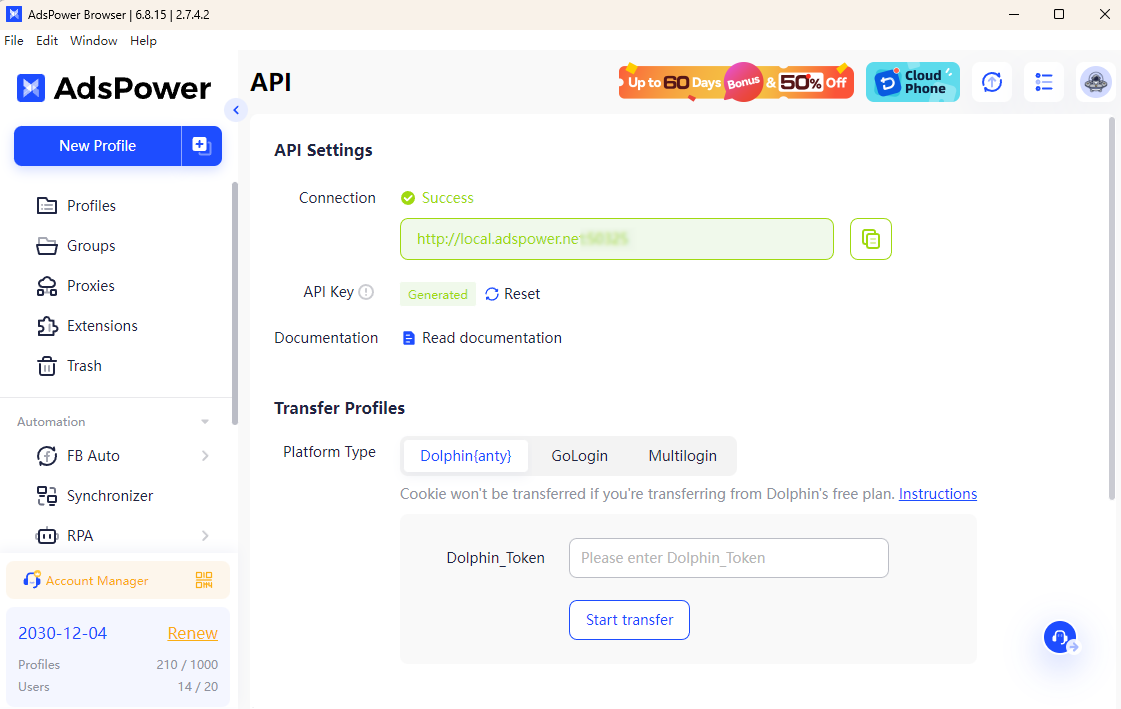
In Kombination mit dem AdsPower-Browserwird Ihr Scraping-Prozess noch effizienter. AdsPower ermöglicht Ihnen den Starten des Headless-Modusmit Headless und API-Schlüssel. Damit können Sie einzigartige Browser-Fingerabdrücke konfigurieren und Proxys nahtlos integrieren, wodurch es für Websites schwieriger wird, automatisierte Aktivitäten zu erkennen. Diese Kombination bietet erhöhte Anonymität und reduziert das Risiko, blockiert zu werden.
Mit AdsPower können Sie authentisches Surfverhalten simulieren, IPs rotieren und mehrere Konten mühelos verwalten. Dies gewährleistet reibungsloses Scraping, selbst auf Websites mit strengen Anti-Crawling-Mechanismen, und macht Ihre Web-Scraping-Projekte relativ erfolgreich und sicher.
Mit den oben genannten praktischen Methoden können Sie Website-Daten scrapen, ohne blockiert zu werden. Sind Sie bereit, Ihre Web-Scraping-Strategie zu verbessern? Setzen Sie diese Best Practices noch heute um und entdecken Sie, wie AdsPower und der IPOasis-Proxy Ihre Bemühungen optimieren können.

Leute lesen auch
- Die 7 besten Tools zum Lösen von Captchas im Jahr 2026 im Vergleich (Vor- und Nachteile)
")
Die 7 besten Tools zum Lösen von Captchas im Jahr 2026 im Vergleich (Vor- und Nachteile)
CAPTCHA-Löser im Vergleich (2026): Web-Scraping, Geschwindigkeit, Genauigkeit und Preis. Finden Sie das beste Tool für reCAPTCHA- und Cloudflare-Herausforderungen.
- CAPTCHA-Lösungsautomatisierung: Ein Vergleich von CAPTCHA-Lösungsdiensten für Entwickler

CAPTCHA-Lösungsautomatisierung: Ein Vergleich von CAPTCHA-Lösungsdiensten für Entwickler
Vergleichen Sie führende CAPTCHA-Lösungsdienste für die Automatisierung. Berücksichtigen Sie Geschwindigkeit, Genauigkeit, Preise und APIs, um die beste CAPTCHA-Lösung auszuwählen.
- Die 11 besten Proxy-Dienste für Geschwindigkeit, Anonymität und Effizienz (Update 2026)

Die 11 besten Proxy-Dienste für Geschwindigkeit, Anonymität und Effizienz (Update 2026)
Dieser Artikel bietet einen umfassenden Überblick über die 11 schnellsten Proxy-Dienste, die im Jahr 2026 verfügbar sein werden.
- So funktioniert die Anmietung von Facebook-Werbekonten: Ein praktischer Leitfaden für wachsende Werbetreibende

So funktioniert die Anmietung von Facebook-Werbekonten: Ein praktischer Leitfaden für wachsende Werbetreibende
Dieser Leitfaden erklärt die Anmietung von Facebook-Werbekonten und wie man mit Meta-Whitelist-Konten mithilfe von GDT Agency und AdsPower sicher skalieren kann.
- So maximieren Sie Ihre Klickrate mit AdsPower × Traffic Bot

So maximieren Sie Ihre Klickrate mit AdsPower × Traffic Bot
Maximieren Sie Ihre Klickrate im Jahr 2025 mit AdsPower × Traffic Bot. Steigern Sie Ihr SEO-Ranking mit sicherem, menschenähnlichem Traffic und fortschrittlicher Anti-Erkennung des Browser-Fingerabdrucks
