
¿Cómo hacer scraping en Instagram? 3 maneras de sacarle el máximo provecho
El procedimiento no es sencillo y presenta muchas complejidades, ya sea debido a las políticas de Instagram o a ambigüedades técnicas.
Esta guía explica cómo extraer contenido de Instagram presentando tres maneras que incluyen métodos con poco código, con mucho código y un método sin código.
¿Es legal el scraping de Instagram?
La respuesta a la pregunta "¿Es legal el scraping de Instagram?" es sí y no al mismo tiempo, a medida que se cae. Según el tipo de datos que estás recopilando. Si quieres recopilar datos públicos de Instagram, la respuesta es sí.
Pero si estás recopilando datos privados de Instagram que requieren iniciar sesión en Instagram, entonces eso está explícitamente prohibido y puedes ht se enfrenta a la suspensión de la cuenta y, en el peor de los casos, a acciones legales. Pero incluso en el caso de datos públicos, debe asegurarse de utilizar un método legal de extracción de datos.
Para extraer datos legales de Instagram, puedes usar las API proporcionadas por Instagram. Estas incluyen la API Graph de Instagram y la API Basic Display de Instagram.
La API Graph le permite administrar y extraer datos sobre cuentas comerciales y de creadores. Mientras que la API Basic Display le brinda acceso de solo lectura Acceso a información básica del usuario. Ambas API cumplen con las políticas de Instagram sobre scraping, por lo que usarlas para scraping en Instagram es totalmente legal.
Sin embargo, si utiliza API no públicas o medios ilícitos que accedan a la plataforma sin permiso previo y a menudo desautoricen Si el raspador aparece como un usuario común, eso se considera raspado no autorizado e infringe las Términos de servicio.
Así que, antes de empezar a rastrear Instagram, da un paso atrás y piensa: "¿Instagram permite el rastreo?" y asegúrate de hacerlo con cuidado.
¿Qué datos de Instagram puedes extraer fácilmente?
Antes de mostrarte cómo extraer datos de Instagram, descubramos qué datos se pueden extraer legalmente de la plataforma. El extracción legal de datos web en Instagram puede darte acceso a estas tres categorías de datos:
-
Hashtags: Puedes ver las fotos y vídeos más recientes o de mejor rendimiento etiquetados con un hashtag específico en su descripción.
-
Perfiles: Puedes obtener datos de perfil como publicaciones, recuento de contenido multimedia y número de seguidores/seguidos.
-
Publicaciones: Puedes obtener métricas como el número de comentarios, el número de "Me gusta", el ID del perfil, la fecha de publicación y la URL.
Tres maneras de extraer contenido de Instagram
Aquí tienes tres maneras de extraer información de Instagram. Elige la que mejor se adapte a tus necesidades y recursos:
Extracción de datos de Instagram mediante la API de Instagram
Aquí tienes una guía paso a paso sobre cómo extraer datos de Instagram, pero asegúrate primero de cumplir con los siguientes requisitos:
-
Una cuenta de Instagram de empresa/creador
-
Una página de Facebook vinculada a la cuenta de Instagram de empresa/creador
-
Una cuenta de desarrollador de Facebook para usar la API de Instagram Graph
-
Una configuración de aplicación de Facebook registrada con ajustes mínimos
Una vez completados estos prerrequisitos, las siguientes etapas se verán así:
Añadir la función de inicio de sesión con Facebook:
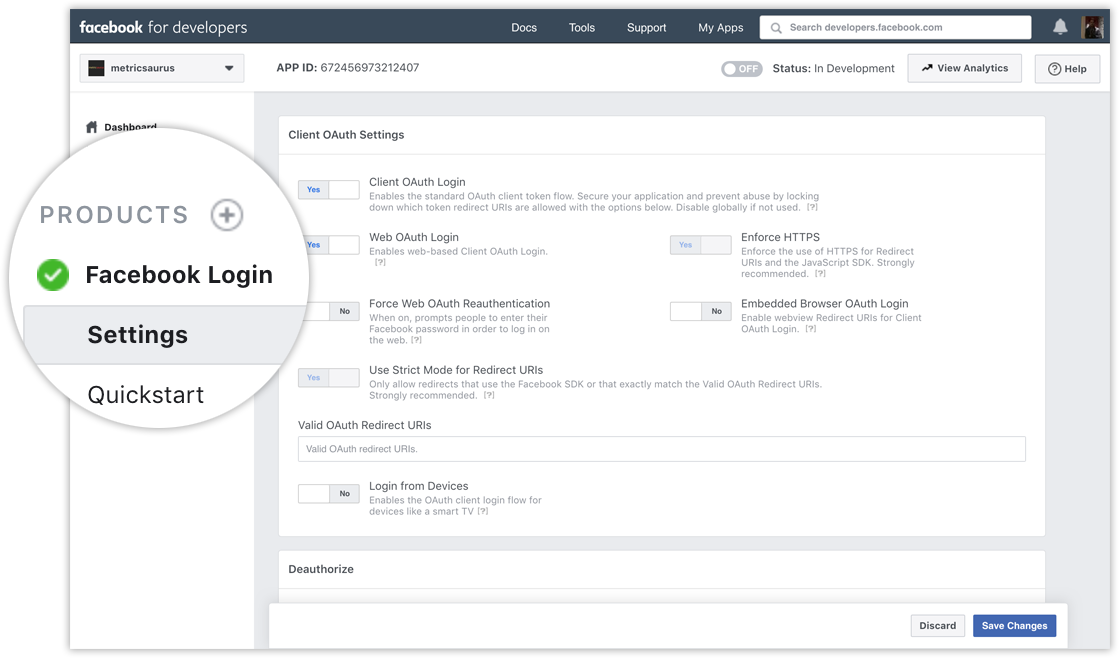
Navega hasta el panel de tu aplicación de Facebook y haz clic en el botón "Producto +" del panel del lado izquierdo de la aplicación. ;la ventana. Desde allí, agregue el producto de inicio de sesión de Facebook. Por ahora, no cambie la configuración de este producto y déjela en los valores predeterminados.
A continuación, tendrás que implementar el inicio de sesión de Facebook en tu aplicación con la ayuda de Documentación de inicio de sesión de Facebook y asegúrese de que su procedimiento de inicio de sesión solicite estos dos permisos básicos:
Generar token de acceso:
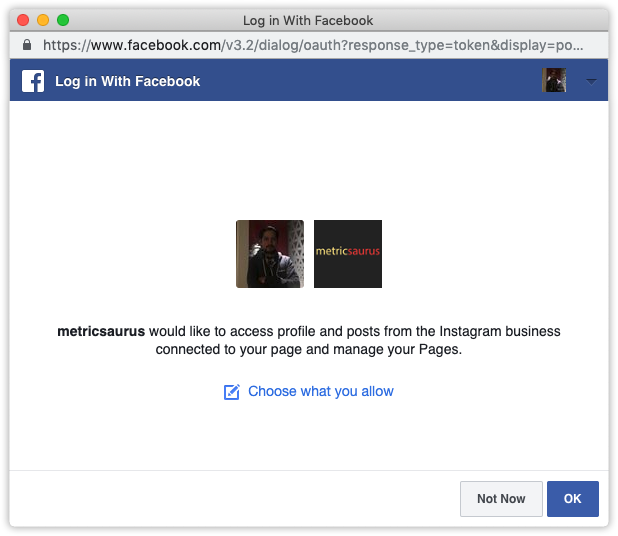
Realizar acciones desde el panel de la aplicación en la cuenta de Instagram requiere un token de acceso de usuario. En el lado derecho de la página del panel, abre
Aparecerá una ventana emergente informando que una aplicación (en este caso, su aplicación) está solicitando los permisos mencionados anteriormente. Simplemente presione el botón Continuar o Aceptar y obtendrá el Token de acceso de usuario en el campo Token de acceso de su panel.
Ahora, usando el token de acceso de usuario, ejecutaremos algunas consultas básicas en la cuenta de Instagram.
1. Obtener el ID de la página de Facebook:
Primero, necesitamos el ID de la página de Facebook conectada a la cuenta de Instagram Business. Para ello, ejecuta la siguiente consulta "Obtener" en el panel.
Esto devolverá el nombre y el ID de las páginas de Facebook pertenecientes al usuario de Facebook. El resultado tendrá este aspecto.
Copia el ID de la página conectada a la cuenta de Instagram Business.
2. Obtener el ID de la cuenta de Instagram para empresas:
Usando el ID de Facebook, escribe el siguiente script en la barra de comandos y pulsa "Enviar".
Obtendrá el siguiente resultado.
3. Obtener objetos multimedia de la cuenta de Instagram:
Copia el ID de Instagram de la salida y ejecuta el siguiente script para obtener los ID de todas las historias publicadas actualmente en la cuenta de Instagram Business.
|
17841405822304914/historias |
La salida contendrá un ID para cada historia.
Este es solo un ejemplo. Con la API de Instagram Graph, también puedes obtener otra información, como los metadatos de un usuario de Instagram, y realizar búsquedas de hashtags.
Ahora pasemos a otra forma de extraer datos de Instagram.
Extracción de datos de Instagram con un programa de extracción de datos en la nube sin código
Para quienes no tienen experiencia en codificación, el método anterior puede ser difícil de entender, y mucho menos de ejecutar. Pero no se preocupen. Hay raspadores de Instagram que hacen el trabajo sin requerir ningún código.
Aquí te mostramos cómo raspar Instagram con una de esas herramientas llamadas Apify.
Vaya a la página del raspador de Instagram de Apify:
Abra la página del raspador de Instagram de Apify y haga clic en Pruébalo gratis.

Regístrate en Apify con tu correo electrónico, tu cuenta de Google o tu cuenta de Github. Esto te llevará a la consola de Apify, donde se realiza el scraping de Instagram.
Recopilar URL de Instagram de destino:
Usando la aplicación o el sitio web de Instagram, recopila todas las URL de perfil de las cuentas de Instagram que quieras extraer. En la consola de Apify, bsp;pegue todas estas URL en los campos de entrada dados, una a la vez. Para ingresarlas todas a la vez, puede hacer clic en el botón Editar en masa.
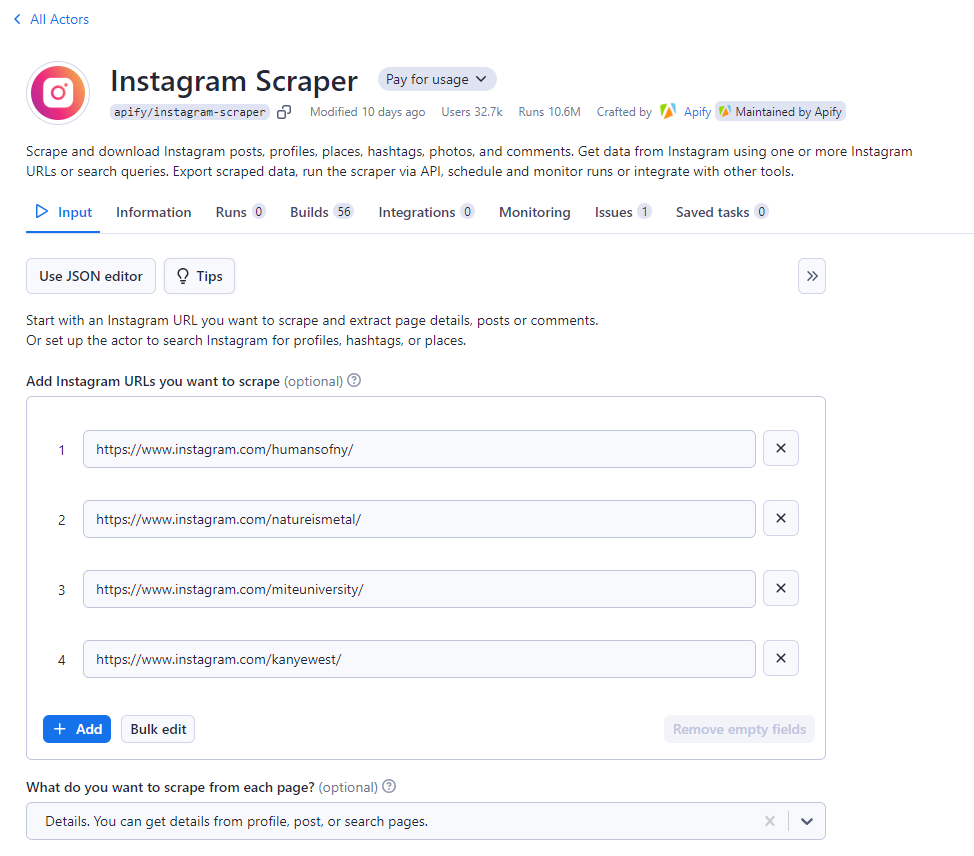
Apify ofrece tres opciones de extracción de contenido para las URL proporcionadas. Puedes extraer contenido de publicaciones y comentarios, o bien obtener diferentes detalles de los perfiles.
Haga clic en Guardar e iniciar:
Deje el resto de la configuración sin cambios y presione Guardar e Iniciar para ejecutar el raspador. El resultado tendrá el formato de una tabla que contiene filas iguales al número nbsp;de URLs de perfil que proporcionaste con varias columnas que contienen metadatos de perfil como biografía, conteo de seguidores, conteo de publicaciones, conteo de reels, ID de cuenta y estado de verificación a nombrar algunos.

Almacenar resultados:
Ahora presione el botón Exportar resultados y seleccione el formato de archivo deseado en la ventana emergente. También puede limpiar los datos seleccionando o omitiendo los campos que no necesita. Después, puede descargar los resultados, verlos en una nueva pestaña o compartirlos a través de un enlace. />

Extracción de datos de Instagram mediante un lenguaje de programación
Crear tu propio raspador de datos de Instagram puede ser la solución más eficiente si tus requisitos no son típicos y tienes un buen programa Conocimientos de programación o contar con un desarrollador en tu equipo. Puedes lograrlo usando cualquier lenguaje de programación junto con un framework de raspado web.
Esta guía muestra cómo extraer datos de Instagram con Python y Selenium, un framework de automatización de navegadores.
Importar bibliotecas esenciales:
Para comenzar, importe las bibliotecas básicas, incluyendo Selenium, su controlador web y Selenium-Stealth, para evitar su detección.
La biblioteca pprint nos ayudará a imprimir el resultado de forma ordenada para una mayor legibilidad.
Recopilar nombres de usuario de Instagram:
Crea una lista y añade los nombres de usuario de los perfiles de Instagram que te interesan.
La variable de salida es un diccionario que usaremos para almacenar los resultados.
Define la función principal:
La función principal recorrerá la lista de nombres de usuario uno a la vez y llamará a la función de raspado en cada nombre de usuario.
Define una función para administrar la configuración del navegador:
Esta función ajustará la configuración del navegador antes de cada solicitud de raspado para agregar anonimato y evitar la detección de Instagram. Estos cambios incluyen la rotación de servidores proxy, la configuración de Selenium-Stealth y la creación de un agente de usuario artificial.
Define una función para el raspado:
La función scrape() llamada en la función principal toma un único nombre de usuario de Instagram como argumento y crea un Punto final del perfil que usaremos para enviar una solicitud mediante el navegador Chrome realizada mediante la función prepare_browser().
También comprobaremos el estado de la solicitud. Si su solicitud fue redirigida a la página de inicio de sesión, esto significa que la solicitud falló. Mientras que si la re no login string, la solicitud fue exitosa y el resultado se analizará como JSON y se enviará a la función parse_data() junto con el nombre de usuario.
Define la función parse_data():
Esta función analiza los datos JSON del argumento user_data para obtener el campo de datos deseado. En este ejemplo, buscamos el nombre completo del usuario, la categoría de la cuenta, la cantidad de seguidores y los títulos de las publicaciones.
Escribe el código del controlador:
El código del controlador inicia el proceso de raspado, extrae los datos en la variable de salida y llama a la función pprint() para mostrarlos de forma atractiva.
|
si __nombre__ == '__principal__': |
Omitir la detección con el navegador AdsPower Antidetect
Aquí es donde AdsPower resulta útil, ya que te ayuda a mantener un perfil bajo al extraer datos de Instagram que podrían infringir las políticas de Instagram.AdsPower utiliza técnicas antidetección como la rotación de IP y la limitación de velocidad para evadir las medidas antirrastreo.
Así que la próxima vez que uses una herramienta sin código o API de Instagram no oficiales, asegúrate de Use el navegador antidetección de AdsPower para evitar la detección.
Conclusión
Instagram solo permite el scraping de los datos disponibles públicamente en su plataforma, para la cual proporciona dos API. Sin embargo, Estas API ofrecen un nivel muy básico de scraping sin permitirte extraer datos de Instagram que sean realmente relevantes.
Esto nos deja con raspadores web de terceros o con la posibilidad de crear su propio raspador utilizando lenguajes de programación. Sin embargo, raspar Instagram nos Usar estos métodos no oficiales tiene posibilidades de ser detectado, así que asegúrate de usar el navegador antidetección AdsPower para mayor protección.

La gente también leyó
- ¿Instagram bloqueado y luego baneado? Cómo recuperarlo

¿Instagram bloqueado y luego baneado? Cómo recuperarlo
¿Instagram bloqueó tu cuenta y luego la suspendió? Esta guía explica qué hacer y cómo recuperar una cuenta bloqueada o desactivada temporalmente.
- ¿Cómo ganar dinero en Kwai en 2026?

¿Cómo ganar dinero en Kwai en 2026?
Aprende a monetizar Kwai en 2026 a través de programas para creadores, transmisiones en vivo, marketing de afiliados, patrocinios y consejos para escalar con AdsPower.
- ¿Te han suspendido tu cuenta de Avakin Life? Esto es lo que debes hacer.

¿Te han suspendido tu cuenta de Avakin Life? Esto es lo que debes hacer.
¿Te preguntas por qué tu cuenta de Avakin Life fue suspendida en 2026? Descubre las posibles causas, desde problemas de inicio de sesión y recuperación hasta infracciones de las reglas, además de qué
- ¿Cómo ver TikTok sin restricciones en la escuela?

¿Cómo ver TikTok sin restricciones en la escuela?
Aprende cómo ver TikTok sin restricciones en la escuela usando VPN, proxies, cambios de DNS o el navegador AdsPower: formas seguras, legales y efectivas de sortear las limitaciones.
- Desbloqueo de Discord en 2026: 7 métodos comprobados para cualquier dispositivo.

Desbloqueo de Discord en 2026: 7 métodos comprobados para cualquier dispositivo.
No te preocupes si Discord está bloqueado. Esta guía te explica cómo desbloquearlo. Aprende a sortear las restricciones más comunes fácilmente y desbloquea tu cuenta hoy mismo.
