
Isang Detalyadong Gabay sa Paggamit ng Amazon Scraper
Web scraping Amazon maaaring maging lubos kapaki-pakinabang para sa busi nesses kung tapos matalino. Huwag’t maniwala sa amin? Isaalang-alang
Hindi namin maipapangako na kikita ka ng isang toneladang pera sa magdamag, ngunit maaari naming ituro sa iyo kung paano mag-scrape ng Amazon upang subukang makarating doon.
Kaya basahin ang blog na ito upang matutunan ang dalawang paraan sa pag-scrape ng Amazon: ang isa ay gumagamit ng isang walang code na Amazon Scraper at isa pa kung saan kami ay gumagawa ng isang Amazon na Scraper na code at isa pa kung saan kami ay gumagawa ng Amazon na Scraper
Ngunit una, alamin muna natin kung okay lang na mag-scrape ng Amazon.
Ito ba ay Legal Para Scrape Amazon?
Pagdating sa pag-scrap sa Amazon, medyo malabo ang mga panuntunan. Amazon's robots.txt file delineates pinahihintulutang scraping parameter sa isang mahabang list na tumutukoy ano ang nawawakas at kung saan mga lugar mahigpit ipinagbabawal. Sa kabila ng mga teknikal na hamon, madaling i-scrape ang Amazon. Maraming code at no-code na tool sa pag-scrape ng Amazon na may mga solusyon para sa pagharap sa mga hakbang na anti-bot ng Amazon. Madali mong masisira ang mga review, produkto, at presyo ng Amazon sa iba pang data gamit ang mga tool na ito. Maging tapat tayo, mataas ang na ang ;kasalukuyang nagbabasa nagbabasa ito ay walang coding kasanayan. Ngunit iyon’walang isyu. hindi mo hindi kailangan coding& nbsp;kaalaman kapag no-code Amazon Scraper ay magagamit. I-access ang Amazon Product Scraper sa ang Apify Store at hit ang ‘Subukan para sa Libre’ button. p;scrape Amazon data kabilang ang mga presyo, review, mga paglalarawan produkto, mga larawan, at ilang higit pang /> Kung bago ka, mag-sign up para sa isang Apify account nang libre. Nag-aalok ang platform ng mga opsyon sa pag-sign-up sa pamamagitan ng email, Google, o GitHub. Sa Apify Console, ipasok ang URL ng produkto o kategorya ng Amazon na gusto mong i-scrape. Ginamit namin ang Video Game Consoles & Accessories at ang Muwebles
Gayunpaman, ang robots.txt file ay nagsisilbi lamang bilang isang etikal na patnubay at hindi legal na may bisa. Kaya, maaaring ma-access ng iyong Amazon Scraper ang mga lugar na hindi limitado nang hindi kinakailangang nahaharap sa anumang mga isyu.
Gayunpaman, hindi humihinto ang Amazon dito. Ito ay higit pa sa pamamagitan ng pagpapatupad ng mga teknikal na hadlang upang pigilan ang mga bot na ma-overload ang mga server nito.
Halimbawa, gumagamit ito ng mga hakbang na anti-scraping tulad ng mga pagsubok sa CAPTCHA at paglilimita sa rate. Upang malampasan ang mga hadlang na ito, ang iyong Amazon scraper ay dapat magkaroon ng advanced techniques like user agent spoofing,
Bilang matagal bilang pag-scrape ay hindi kasangkot hindi awtorisado access, hal., data sa likod ng a login, o mapuspos ang&n bsp;imprastraktura ng site, ito karaniwang nahuhulog sa loob sa ligtas kategorya. Ang Kataas-taasang Korte defended din class="forecolor" style="color: #1e4dff;">a Data Analytics firm na ay idemanda ng LinkedIn under CFAA, citing hindi awtorisadong web scraping.
Higit pa rito, dapat mo ring tiyakin na ang iyong paggamit ng na-scrap na data ay legal, o hindi mo ito muling ire-replika. repercussions.
Ngayon ang milyon-dollar na tanong, paano i-scrape ang Amazon?Paano Mag-scrape Amazon?
Kaya't magsimula muna tayo sa walang code na Amazon Scraper. No-Code Amazon Scraper:
Gamit ang mga tool na ito, ibibigay mo lang ang mga URL ng pahina ng produkto o kategorya at makukuha ka ng scraper ng lahat ng data ng produkto ng Amazon mula sa pahinang iyon. Kapag tapos na ang mga ito sa web scraping Amazon, binibigyan ka rin ng maraming opsyon sa pag-save ng file.
Pinili namin ang Amazon Scraper ng Apify para sa demo na ito. Ang Apify ay may hiwalay na mga tool para sa pag-scrap ng iba't ibang bahagi ng Amazon kabilang ang Amazon Product Scraper, Amazon Review Scraper, at Amazon Bestsellers Scraper.
Sa gabay na ito, gagamitin namin ang Amazon Product Scraper ng Apify. Ang Amazon Product Scraper ay may mga feature para lutasin ang mga CAPTCHA at magtakda ng mga proxy para makatulong sa pag-iwas sa mga anti-bot na hakbang.
Kaya simulan na natin ang demo. Hakbang 1: Bisitahin ang Amazon Product Scraper Page
 width=""> lapad />
width=""> lapad />
>Hakbang 2: Gumawa ng Iyong Apify Account

Hakbang 3: I-paste ang Mga URL ng Amazon ng Target na Nilalaman
Gayundin, magpasya sa maximum na bilang ng mga item na nilalayon mong simutin sa pamamagitan ng pagtatakda ng limitasyon sa field na 'Max item'. Itinakda namin ito sa 15 ngunit maaari mo itong itakda hangga't gusto mo.
Hakbang 4: Paganahin ang CAPTCHA Solver
Hindi mo ma-scrape ang Amazon nang walang CAPTCHA solver. Ang Amazon ay kilala na napakahusay sa pag-detect ng mga bot. Sa sandaling pinaghihinalaan nito ang aktibidad ng bot, naghagis ito ng CAPTCHA sa bot. Ang paggamit ng proxy ay mahalaga para sa pag-bypass ng mga hakbang laban sa pag-scrape. Ang Amazon scraper ay nag-aalok ng iba't ibang mga opsyon sa proxy, kabilang ang Residential, Datacenter, o sa iyo, upang i-mask ang mga aktibidad sa pag-scrape at mag-navigate sa paligid ng mga paghihigpit. Basahin ang tungkol sa mga pagkakaiba sa pagitan ng Residential at Datacenter proxies
Kaya para matiyak na ang iyong Amazon Scraper ay gumagana nang walang problema, paganahin ang paglutas ng CAPTCHA.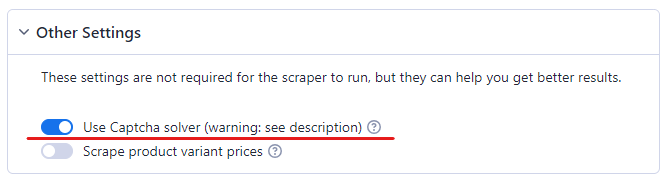
Hakbang 5: I-configure ang Proxy
type ng data residential proxy option ay pinili bilang default dahil ito ang pinakamahusay para sa mga anti-scraping system.
Hakbang 6: Ilunsad ang Scraper
Sa iyong mga parameter na nakatakda, simulan ang Amazon Product Scraper sa pamamagitan ng pagpindot sa ‘Start’ button sa ibaba ng page.
Magbabago ang status mula sa 'Tumatakbo' patungong 'Nagtagumpay' kapag nakumpleto.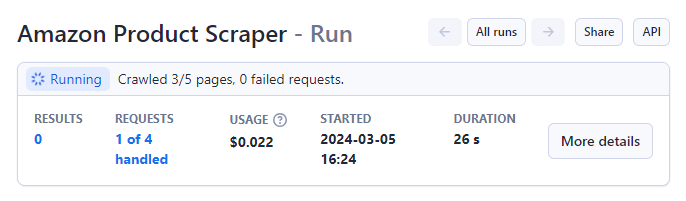 taas="201" />ikaw tingnan ang preview ng data sa iyong screen.
taas="201" />ikaw tingnan ang preview ng data sa iyong screen. 
Hakbang 7: I-export Iyong File
Pindutin ang button na 'I-export ang mga resulta' upang i-download ang iyong nakolektang data. Sinusuportahan ng platform ang maraming format, kabilang ang CSV, JSON, at Excel.
Python Amazon Scraper Paggamit Programming
Sa walang code na Amazon Scraper na ginamit namin sa itaas, kung titingnan mong mabuti ang naunang nabanggit na hakbang 6, nabigo ang 69 sa 173 na kahilingan. Ito ay dahil hinaharangan ng Amazon ang mga kahilingang iyon.
Upang i-bypass ang isyung ito, kakailanganin mong i-program ang iyong sariling scraping script. Sa gabay na ito, gumagawa kami ng Python Amazon Product Scraper.
Kaya magsimula na tayo.
Hakbang 1: I-install Python
Upang ma-code ang aming Python Amazon scraper, mahalagang magkaroon ng Python na naka-install sa iyong computer. Inirerekomenda na i-download ang pinakabagong o kamakailang mga bersyon para sa compatibility sa ang kinakailangan /> Ang pinakabuod ng anumang Amazon scraper ay kinabibilangan ng pagkuha at pag-parse ng nilalaman ng web. Para dito, gumagamit kami ng kumbinasyon ng mga library ng Python. Bago i-import ang mga ito kailangan mong i-install ang mga ito gamit ang sumusunod na command: Ngayon ay ii-import namin ang mga ito sa loob ng aming Amazon scraper Python script: Ang isang karaniwang hadlang sa pag-scrape ng web sa Amazon ay ang mga pagtatanggol na hakbang ng Amazon laban sa awtomatikong pag-access. Upang maiwasan ito, ang aming Amazon scraper Python script ay ginagaya ang kahilingan ng isang web browser sa pamamagitan ng pagsasama ng mga custom na HTTP header, gaya ng 'User-Agent' and 'Accept-Language'. Hakbang 2: Pag-import Kinakailangan Mga Aklatan
Hakbang 3: Pag-configure ng HTTP Mga Header
Ito ay isang mas mahusay na kasanayan upang magdagdag ng higit pang mga header.
Upang kunin mga header na ito para sa iyong browser,
-
pindutin ang F12 sa isang Amazon pahina upang buksan ang developer tools, >Buksan ang Networks tab at Piliin HeadersI-reload ang pahinaPiliin ang unang kahilinganSa the Headers tab, scroll down upang Humiling Headers& nbsp;seksyon at kopyahin ang mga halaga ng header nabanggit sa itaas
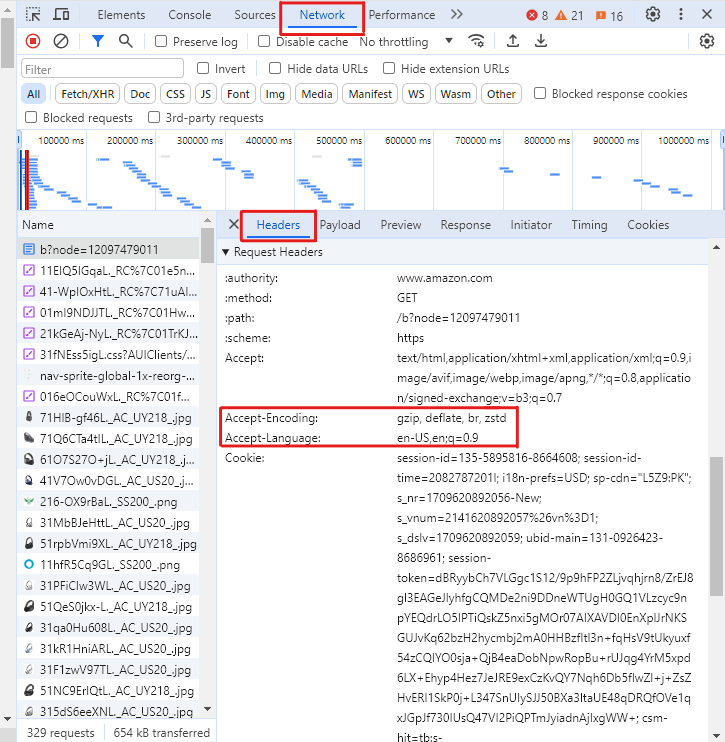
Kung wala ang mga header na ito, malaki ang posibilidad na ma-block ng Amazon ang mga kahilingan sa pagkuha at magbalik ng tugon tulad ng sumusunod na may status_code 503 (error) sa halip na 200 (tagumpay).
Hakbang 4: Pagkuha ng Impormasyon ng ProduktoAng aming Amazon Product Scraper kasama ang function scrape_amazon_product na nagsasagawa ang kritikal gawain ng pagkuha ng mga detalye produkto. Ang function kukuha ang e kategorya pahina URL bilang isang input at nagbabalik isang diksyonaryo na may ang &nbsquo&nbsquo;produkto />
Ang paraan pagkatapos nagpapadala isang humihiling sa Amazon gamit ang&n bsp;URL at ang custom header variable nilikha namin sa itaas.
Pagkatapos nito, gamit ang mga CSS selector ng BeautifulSoup, kukunin namin ang pamagat, presyo, URL ng larawan, at paglalarawan ng produkto mula sa mga indibidwal na pahina ng produkto.
Hakbang 5: Pagharap sa Mga Listahan ng Produkto & Pagbilang ng pahinaPara sa aming Amazon scraper Python script upang mangolekta malawak data sa pamamagitan ng paglipat sa pamamagitan ng kategorya mga pahina at paghawak sa pagination, ang script na-navigate sa mga pahina sa listahan ng produkto ng Amazon.
Tinutukoy nito ang mga link ng produkto gamit ang mga tagapili ng CSS at sinusundan ang pagination sa pamamagitan ng pagtukoy sa link ng 'Next' page.
Hakbang 6: Pag-save ng Na-scrap na DataSa wakas, ang na-scrap na data ay pinagsama-sama sa isang listahan ng mga diksyunaryo, na pagkatapos ay iko-convert sa Pandas DataFrame. Ang DataFrame na ito ay na-export bilang isang CSV file.
Gamitin ang Amazon Scraper nang patagoAng pag-scrape Amazon ay kadalasang direkta. Gayunpaman, ikaw maaaring harapin ang maramihang mga hamon tulad ng CAPTCHA, humiling ng mga pag-block, at mga limitasyon sa rate. />
Kaya mag-sign up para sa libre ngayon at simulan scraping less.
Upang maiwasang mabangga ang mga isyung ito, dapat kang gumamit ng browser na anti-detect tulad ng AdsPower
Binabasa din ng mga tao
- Nangungunang 12 Laro na Hindi Naharangan ng Paaralan (+ Madaling Pag-ayos)
")
Nangungunang 12 Laro na Hindi Naharangan ng Paaralan (+ Madaling Pag-ayos)
Tuklasin ang 12 sikat na naka-block na laro para sa paaralan, alamin ang mga praktikal na paraan para ma-access ang mga naka-block na site ng laro, at tingnan kung paano nakakatulong ang AdsPower na mapanatili ang iyong gaming browser
- Paano Ligtas na Pamahalaan ang Maramihang Apple Account sa 2026

Paano Ligtas na Pamahalaan ang Maramihang Apple Account sa 2026
Alamin kung paano ligtas na pamahalaan ang maraming Apple account gamit ang mga praktikal na tip
- Paano Kumita ng Pera sa Substack 2026: Mga Istratehiya sa Kita para sa mga Lumikha

Paano Kumita ng Pera sa Substack 2026: Mga Istratehiya sa Kita para sa mga Lumikha
Gusto mo bang kumita ng pera sa Substack? Tatalakayin sa gabay na ito ang mga napatunayang paraan ng pag-monetize, mga tip sa paglago, at kung paano ginagawang kita ng mga creator ang content.
- Hindi Nakontak o Hindi Makontak si Claude? Paano Mag-diagnose at Ayusin ang mga Karaniwang Isyu

Hindi Nakontak o Hindi Makontak si Claude? Paano Mag-diagnose at Ayusin ang mga Karaniwang Isyu
Hindi ba gumagana si Claude, o nakakakita ka ba ng mga error na "Hindi makontak si Claude"? Alamin kung paano ayusin ang mga login loop, mga error sa pagpapatotoo, mga isyu sa network, at higit pa.
- Naka-lock ang Instagram Pagkatapos ay Na-ban? Paano Ito Maibabalik

Naka-lock ang Instagram Pagkatapos ay Na-ban? Paano Ito Maibabalik
Ni-lock ng Instagram ang iyong account at pagkatapos ay pinagbawalan ito? Sinasaklaw ng gabay na ito ang dapat gawin at kung paano i-recover ang isang pansamantalang naka-lock o hindi pinaganang account.
