
ការណែនាំលម្អិតដើម្បីប្រើ Amazon Scraper
Web scraping Amazon អាច បាន ខ្ពស់ ចំណេញ សម្រាប់ អាជីវកម្ម ប្រសិនបើ ធ្វើបាន ឆ្លាតវៃ។ Don’t span;believe class="forecolor" style="color: #1e4dff;">រឿងនេះ នៃ a គេហទំព័រ ដែលផលិត a ធ្លាក់ចុះថ្គាម $800k ក្នុង គ្រាន់តែ ពីរ ខែ ខណៈពេលដែល ទាំងអស់ ពួកគេ បាន ត្រូវបាន ពិនិត្យ Amazon ប្រចាំថ្ងៃ។ ត្រជាក់, ហ៎?
យើងមិនអាចសន្យាថាអ្នកនឹងរកលុយបានច្រើនមួយយប់នោះទេ ប៉ុន្តែយើងអាចបង្រៀនអ្នកពីរបៀបកោស Amazon ដើម្បីព្យាយាម និងទៅដល់ទីនោះ។
ដូច្នេះសូមអានប្លក់នេះដើម្បីស្វែងយល់ពីវិធីពីរយ៉ាងក្នុងការលុប Amazon៖ មួយដោយប្រើគ្មានលេខកូដ Amazon Scraper និងមួយទៀតដែលយើងបង្កើតកូដ Python Scraper ។
Amazon data-type="text">
ប៉ុន្តែជាដំបូង សូមរកមើលថាតើវាមិនអីទេក្នុងការកម្ទេច Amazon ។
តើវា ស្របច្បាប់ ដើម្បី កោស Amazon ដែរឬទេ?
នៅពេលនិយាយអំពីការលុបបំបាត់ក្រុមហ៊ុន Amazon ច្បាប់មានភាពស្រពិចស្រពិលបន្តិច។ របស់ Amazon robots.txt ឯកសារ កំណត់ អនុញ្ញាត ការបំបែក ប៉ារ៉ាម៉ែត្រ ក្នុង a បញ្ជី វែង ដែល បញ្ជាក់ អ្វីដែល គឺ អាចបំបែកបាន និង ដែល តំបន់ យ៉ាងតឹងរ៉ឹង។ />
ទោះយ៉ាងណា ឯកសារ robots.txt គ្រាន់តែជាគោលការណ៍ណែនាំប្រកបដោយក្រមសីលធម៌ប៉ុណ្ណោះ ហើយមិនមានកាតព្វកិច្ចស្របច្បាប់ទេ។ ដូច្នេះ Amazon Scraper របស់អ្នកអាចចូលទៅកាន់តំបន់គ្មានដែនកំណត់ដោយមិនចាំបាច់ប្រឈមមុខនឹងបញ្ហាណាមួយឡើយ។
ទោះជាយ៉ាងណាក៏ដោយ Amazon មិនឈប់នៅទីនេះទេ។ វាដំណើរការបន្ថែមទៀតដោយការអនុវត្តរបាំងបច្ចេកទេសដើម្បីការពារ bots ពីការផ្ទុកលើសចំណុះ servers របស់វា។
ឧទាហរណ៍ វាប្រើវិធានការប្រឆាំងនឹងការកោសដូចជាការធ្វើតេស្ត CAPTCHA និងការកំណត់អត្រា។ ដើម្បីជម្នះឧបសគ្គទាំងនេះ អ្នកកោស Amazon របស់អ្នកត្រូវតែមាន បច្ចេកទេស កម្រិតខ្ពស់ ដូច អ្នកប្រើប្រាស់ ភ្នាក់ងារ ការក្លែងបន្លំ, CAPTCHA ការដោះស្រាយ ឬ ពន្យារពេល ការស្នើសុំ; បើមិនដូច្នេះទេ Amazon scraping endeavor would remain a data />ដូច្នេះដើម្បីឆ្លើយយ៉ាងខ្លី “តើ Amazon អនុញ្ញាត web scraping?”៖ ភាពស្របច្បាប់នៃគេហទំព័រដែល scraping ទិន្នន័យ Amazon មិនមានភាពច្បាស់លាស់ និងអាស្រ័យលើកត្តាជាច្រើនរួមទាំង
-
ប្រភេទ នៃ ទិន្នន័យ ត្រូវបានដកចេញ
-
វិធីសាស្ត្រ បានប្រើ សម្រាប់ ការឆ្លាក់
-
និងគោលបំណងនៃទិន្នន័យដែលបានបន្សល់ទុក
ដូចដែល យូរ ដូចជា scraping ធ្វើ មិនពាក់ព័ន្ធ ការចូលប្រើដោយគ្មានការអនុញ្ញាត, ឧ, ទិន្នន័យ នៅពីក្រោយ a ចូល ឬ គ្របដណ្តប់ the&n ហេដ្ឋារចនាសម្ព័ន្ធរបស់គេហទំព័រ bsp; ជាទូទៅ ធ្លាក់ក្នុង ប្រភេទ សុវត្ថិភាព តុលាការកំពូល ក៏ ការពារ a Data Analytics firm ដែល ត្រូវបាន ប្តឹង ដោយ LinkedIn CFAA, citing unauthorized web datatype="scraping"> />ជាងនេះទៅទៀត អ្នកក៏គួរតែធានាថា ការប្រើប្រាស់ទិន្នន័យដែលលួចបន្លំរបស់អ្នកគឺស្របច្បាប់ ពោលគឺ អ្នកមិនលក់ ឬចម្លងវាឡើងវិញទេ ព្រោះវាអាចមានផលប៉ះពាល់ផ្នែកច្បាប់យ៉ាងធ្ងន់ធ្ងរ។
ឥឡូវនេះ សំណួររាប់លានដុល្លារ តើធ្វើដូចម្តេចដើម្បីកម្ទេច Amazon?
របៀប ដើម្បី កោសក្រុមហ៊ុន Amazon?
ទោះបីជាមានការប្រឈមផ្នែកបច្ចេកទេសក៏ដោយ វាជាការងាយស្រួលក្នុងការកំចាត់ Amazon ។ មានឧបករណ៍កូដ និងគ្មានកូដជាច្រើននៅលើ Amazon scraping ជាមួយនឹងដំណោះស្រាយសម្រាប់ដោះស្រាយវិធានការប្រឆាំង bot របស់ Amazon ។ អ្នកអាចបំបែកការពិនិត្យ Amazon ផលិតផល និងតម្លៃបានយ៉ាងងាយស្រួលក្នុងចំណោមទិន្នន័យផ្សេងទៀតដោយប្រើឧបករណ៍ទាំងនេះ។
ដូច្នេះសូមចាប់ផ្តើមជាមួយ Amazon Scraper គ្មានលេខកូដជាមុនសិន។
No-Code Amazon Scraper៖
តោះ ស្មោះត្រង់ ហាងឆេង ខ្ពស់ ដែល អ្នកអាន បច្ចុប្បន្ន អាន នេះ មិន មាន ជំនាញសរសេរកូដ ។ ប៉ុន្តែ នោះ គ្មាន បញ្ហាទេ។ អ្នក មិន មិនត្រូវការ ការសរសេរកូដ ចំណេះដឹង នៅពេលដែល គ្មានកូដ Amazon Scrapers អាចរកបាន។
ជាមួយឧបករណ៍ទាំងនេះ អ្នកគ្រាន់តែផ្តល់ផលិតផល ឬប្រភេទ URLs ទំព័រ ហើយ scraper នឹងទទួលបានអ្នកនូវទិន្នន័យផលិតផល Amazon ទាំងអស់ពីទំព័រនោះ។ នៅពេលដែលពួកវារួចរាល់ជាមួយនឹងការ scraping គេហទំព័រ Amazon អ្នកក៏ត្រូវបានផ្តល់ជម្រើសរក្សាទុកឯកសារជាច្រើនផងដែរ។
យើងបានជ្រើសរើស Apify’s Amazon Scraper សម្រាប់ការបង្ហាញនេះ។ Apify មានឧបករណ៍ដាច់ដោយឡែកសម្រាប់កម្ទេចតំបន់ផ្សេងៗរបស់ Amazon រួមមាន Amazon Product Scraper, Amazon Review Scraper និង Amazon Bestsellers Scraper ។
នៅក្នុងការណែនាំនេះ យើងនឹងប្រើប្រាស់ Apify’s Amazon Product Scraper ។ Amazon Product Scraper មានមុខងារដោះស្រាយ CAPTCHAs និងកំណត់ប្រូកស៊ី ដើម្បីជួយគេចពីវិធានការប្រឆាំង bot។
ដូច្នេះតោះចាប់ផ្តើមការសាកល្បង។
ជំហាន 1: ទស្សនា ទំព័រ ផលិតផល Amazon Scraper ទំព័រ
ចូលប្រើ ផលិតផល Amazon Scraper នៅលើ Apify Store និង ចុច the ‘សាកល្បង សម្រាប់ ប៊ូតុង ឥតគិតថ្លៃ’ ឧបករណ៍ នេះ អនុញ្ញាតឱ្យអ្នក p;scrape Amazon ផលិតផល ទិន្នន័យ រួមទាំង តម្លៃ ការពិនិត្យ ផលិតផល ការពិពណ៌នា រូបភាព និង លក្ខណៈ ច្រើនទៀត ជាច្រើនទៀត។ ប្រសិនបើអ្នកថ្មី ចុះឈ្មោះគណនី Apify ដោយឥតគិតថ្លៃ។ វេទិកានេះផ្តល់នូវជម្រើសចុះឈ្មោះតាមរយៈអ៊ីមែល Google ឬ GitHub ។ នៅក្នុង Apify Console សូមបញ្ចូល URL នៃផលិតផល Amazon ឬប្រភេទដែលអ្នកចង់បំបែក។ យើងបានប្រើ វីដេអូ&ហ្គេម កុងសូល & គ្រឿងបន្លាស់ និង the គ្រឿងសង្ហារឹម ប្រភេទ នៅក្នុង នេះ ឧទាហរណ៍។ អ្នកមិនអាចលុប Amazon ដោយគ្មានឧបករណ៍ដោះស្រាយ CAPTCHA បានទេ។ Amazon ត្រូវបានគេដឹងថាមានប្រសិទ្ធភាពខ្ពស់ក្នុងការស្វែងរក bots ។ ដរាបណាវាសង្ស័យថាមានសកម្មភាព bot វានឹងបោះ CAPTCHA ទៅកាន់ bot។ src="https://img.adspower.net/top-browser/a2/f11f0a058ffced4b4d6b3d6e1bed38.png?x-oss-process=image/resize,w_694,m_lfit" alt="" width="669" height="181" /> ការប្រើប្រូកស៊ីគឺចាំបាច់សម្រាប់ការរំលងវិធានការប្រឆាំងការកោស។ Amazon scraper ផ្តល់ជម្រើសប្រូកស៊ីជាច្រើន រួមទាំងលំនៅដ្ឋាន មជ្ឈមណ្ឌលទិន្នន័យ ឬរបស់អ្នកផ្ទាល់ ដើម្បីបិទបាំងសកម្មភាពសំណល់អេតចាយ និងរុករកជុំវិញការរឹតបន្តឹង។ អានអំពី ភាពខុសគ្នា រវាង លំនៅដ្ឋាន និង Datacenter ប្រូកស៊ី ដោយកំណត់ប៉ារ៉ាម៉ែត្ររបស់អ្នក សូមចាប់ផ្តើមផលិតផលរបស់ Amazon ដោយចុចប៊ូតុង ‘Start’ ប៊ូតុងនៅខាងក្រោមទំព័រ។ ចុចប៊ូតុង 'នាំចេញលទ្ធផល' ដើម្បីទាញយកទិន្នន័យដែលបានប្រមូលរបស់អ្នក។ វេទិកានេះគាំទ្រទម្រង់ជាច្រើន រួមទាំង CSV, JSON, និង Excel។ ក្នុងគ្មានកូដ Amazon Scraper ដែលយើងបានប្រើខាងលើ បើអ្នកមើលឲ្យដិតដល់នៅជំហានទី 6 ដែលបានរៀបរាប់ពីមុន សំណើ 69 ក្នុងចំណោម 173 បានបរាជ័យ។ នេះគឺដោយសារតែ Amazon កំពុងរារាំងសំណើទាំងនោះ។ ដើម្បីសរសេរកូដ Python Amazon scraper របស់យើង វាចាំបាច់ណាស់ក្នុងការដំឡើង Python នៅលើកុំព្យូទ័ររបស់អ្នក។ វាត្រូវបានផ្ដល់អនុសាសន៍ឱ្យ ទាញយក ចុងក្រោយបំផុត ឬ កំណែ ថ្មីៗ សម្រាប់ ភាពឆបគ្នា ជាមួយ បណ្ណាល័យ ដែលត្រូវការ។ ចំណុចសំខាន់នៃកម្មវិធីអេតចាយរបស់ Amazon ពាក់ព័ន្ធនឹងការទៅយក និងញែកមាតិកាបណ្ដាញ។ សម្រាប់បញ្ហានេះ យើងប្រើការរួមបញ្ចូលគ្នានៃបណ្ណាល័យ Python។ មុនពេលនាំចូលពួកវា អ្នកនឹងត្រូវដំឡើងពួកវាដោយប្រើពាក្យបញ្ជាខាងក្រោម៖ ឥឡូវនេះ យើងនឹងនាំចូលពួកវានៅក្នុងស្គ្រីប Amazon scraper Python របស់យើង៖ ឧបសគ្គទូទៅក្នុងការលុបគេហទំព័រ Amazon គឺវិធានការការពាររបស់ Amazon ប្រឆាំងនឹងការចូលដំណើរការដោយស្វ័យប្រវត្តិ។ ដើម្បីជៀសវាងបញ្ហានេះ ស្គ្រីប Amazon scraper Python របស់យើងធ្វើត្រាប់តាមសំណើរបស់កម្មវិធីរុករកតាមអ៊ីនធឺណិត ដោយរួមបញ្ចូលបឋមកថា HTTP ផ្ទាល់ខ្លួន ដូចជា 'User-Agent' and 'Accept-Language'
ដើម្បី ទទួលបាន ទាំងនេះ បឋមកថា សម្រាប់ កម្មវិធីរុករកតាមអ៊ីនធឺណិតរបស់អ្នក,
ផលិតផល Amazon Scraper របស់យើងរួមបញ្ចូល the function scrape_amazon_product ដែល អនុវត្ត ភារកិច្ច សំខាន់ នៃ ព័ត៌មានលម្អិតអំពីផលិតផល មុខងារ ត្រូវការ ទី e Amazon ប្រភេទ ទំព័រ URL ជា ការបញ្ចូល និង ត្រឡប់ a វចនានុក្រម ជាមួយ ផលិតផល ព័ត៌មាន របស់ ។ សម្រាប់ Amazon scraper Python script ដើម្បី ប្រមូលទិន្នន័យ ទូលំទូលាយ ដោយ ផ្លាស់ទី តាមរយៈ ប្រភេទ ទំព័រ និង ការគ្រប់គ្រង ការសរសេរទំព័រ អក្សរ រុករក តាមរយៈ ទំព័រ ផលិតផល ការរាយបញ្ជី ទំព័ររបស់ Amazon។ ជាចុងក្រោយ ទិន្នន័យដែលបានលុបចោលត្រូវបានប្រមូលផ្តុំទៅក្នុងបញ្ជីវចនានុក្រម ដែលបន្ទាប់មកត្រូវបានបំប្លែងទៅជា Pandas DataFrame។ បន្ទាប់មក DataFrame នេះត្រូវបាននាំចេញជាឯកសារ CSV។ ការរើសអេតចាយ Amazon គឺ ជាធម្មតា និយាយត្រង់។ ទោះជាយ៉ាងណាក៏ដោយ អ្នកអាចប្រឈមមុខនឹងបញ្ហាប្រឈមជាច្រើន ដូចជា CAPTCHAs សំណើរ blocks data-type="text">ដើម្បីជៀសវាងបញ្ហាទាំងនេះ អ្នកគួរប្រើកម្មវិធីរុករកតាមអ៊ីនធឺណិតដូចជា AdsPower។ AdsPower ធ្វើឱ្យ ប្រាកដថា Amazon scraper របស់អ្នកនៅតែ មិនអាចរកឃើញ ដោយ ផ្តល់ជូន លក្ខណៈពិសេស ដូច ស្នាមម្រាមដៃ ការក្លែងបន្លំ 
ជំហាន 2: បង្កើត គណនី Apify របស់អ្នក

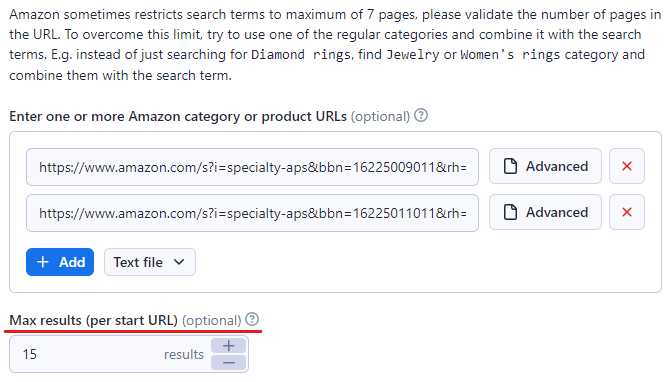
ជំហានទី 3៖ បិទភ្ជាប់ Amazon URLs នៃមាតិកាគោលដៅ
ដោយចុចបន្ថែម
តំណ ‘+ បន្ថែម’ ប៊ូតុង។ ឬប្រសិនបើមានតំណភ្ជាប់ច្រើន អ្នកគ្រាន់តែអាចបន្ថែមវាទាំងអស់ទៅក្នុងឯកសារអត្ថបទ ហើយបង្ហោះវាទៅ Amazon Scraper ។
ក៏សម្រេចចិត្តលើចំនួនអតិបរមានៃធាតុដែលអ្នកមានបំណងចង់បំបែកដោយកំណត់ដែនកំណត់នៅក្នុងវាល 'Max items' ។ យើងបានកំណត់វាដល់ 15 ប៉ុន្តែអ្នកអាចកំណត់វាឱ្យខ្ពស់តាមការចង់បាន។ជំហាន 4៖ បើកដំណើរការ CAPTCHA ដំណោះស្រាយ
ជំហានទី 5៖ កំណត់រចនាសម្ព័ន្ធប្រូកស៊ី
ជម្រើសប្រូកស៊ីលំនៅដ្ឋានត្រូវបានជ្រើសរើសដោយជម្រើសលំនាំដើមល្អបំផុត។ />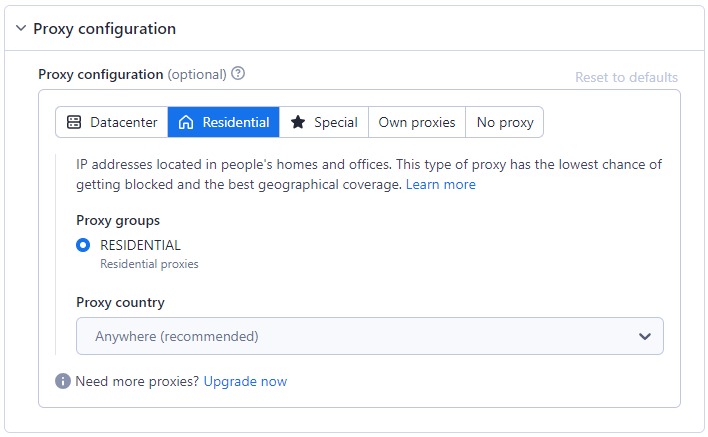
ជំហាន 6: បើកដំណើរការ ម៉ាស៊ីនកោស
ស្ថានភាពនឹងផ្លាស់ប្តូរពី 'កំពុងដំណើរការ' ទៅ 'ជោគជ័យ' នៅពេលបញ្ចប់។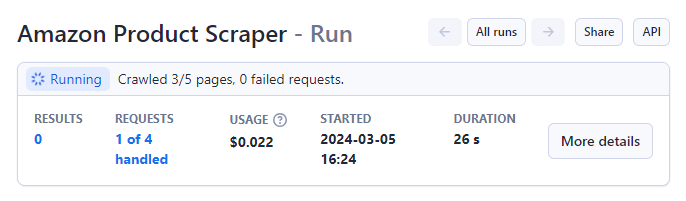 {1} {/1}href=""the
{1} {/1}href=""the
"{1} } ការមើលជាមុននៃទិន្នន័យនៅលើអេក្រង់របស់អ្នក។ />ជំហាន 7: នាំចេញ ឯកសាររបស់អ្នក

Python Amazon Scraper ការប្រើប្រាស់ ការសរសេរកម្មវិធី
ដើម្បីជៀសផុតពីបញ្ហានេះ អ្នកនឹងត្រូវរៀបចំកម្មវិធីស្គ្រីប scraping ផ្ទាល់ខ្លួនរបស់អ្នក។ នៅក្នុងការណែនាំនេះ យើងកំពុងបង្កើត Python Amazon Product Scraper។
ដូច្នេះសូមចាប់ផ្តើម។ជំហាន 1: ដំឡើង Python
ជំហាន 2: ការនាំចូល បណ្ណាល័យចាំបាច់
ជំហាន 3: ការកំណត់រចនាសម្ព័ន្ធ HTTP បឋមកថា
ជំហានទី 4៖ ស្រង់ព័ត៌មានផលិតផល
វិធីសាស្រ្ត បន្ទាប់មក ផ្ញើ a សំណើ ទៅ Amazon ដោយប្រើ the URL និង the custom headers variable we បង្កើត
។ data-type="text">
បន្ទាប់ពីនោះ ដោយប្រើឧបករណ៍ជ្រើសរើស CSS របស់ BeautifulSoup យើងនឹងទាញយកចំណងជើង ផលិតផល URL រូបភាព និងការពិពណ៌នាពីទំព័រផលិតផលនីមួយៗ។
ជំហានទី 5៖ ដោះស្រាយជាមួយការចុះបញ្ជីផលិតផល & ទំព័រដើម
វាកំណត់អត្តសញ្ញាណតំណផលិតផលដោយប្រើឧបករណ៍ជ្រើស CSS និងតាមដានទំព័រដោយរកឃើញតំណទំព័រ 'បន្ទាប់'។
ជំហានទី 6៖ ការរក្សាទុកទិន្នន័យដែលបន្សល់ទុក
ប្រើ Amazon Scraper ដោយលួចលាក់
data-type="text">ដូច្នេះ ចុះឈ្មោះ ដោយឥតគិតថ្លៃ ឥឡូវនេះ និង ចាប់ផ្តើម scraping Amazon យ៉ាងរលូន។

មនុស្សក៏អានដែរ។
- ហ្គេមកំពូលទាំង 12 ដែលមិនត្រូវបានរារាំងដោយសាលារៀន (+ ការជួសជុលងាយៗ)
")
ហ្គេមកំពូលទាំង 12 ដែលមិនត្រូវបានរារាំងដោយសាលារៀន (+ ការជួសជុលងាយៗ)
ស្វែងរកហ្គេមពេញនិយមចំនួន 12 ដែលមិនត្រូវបានរារាំងសម្រាប់សាលារៀន រៀនវិធីជាក់ស្តែងដើម្បីចូលទៅកាន់គេហទំព័រហ្គេមដែលត្រូវបានរារាំង និងមើលពីរបៀបដែល AdsPower ជួយរក្សាកម្មវិធីរុករកហ្គេមរបស់អ្នក
- របៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពនៅឆ្នាំ 2026

របៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពនៅឆ្នាំ 2026
ស្វែងយល់ពីរបៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពជាមួយនឹងគន្លឹះជាក់ស្តែង
- របៀបរកលុយលើ Substack ឆ្នាំ ២០២៦៖ យុទ្ធសាស្ត្ររកចំណូលសម្រាប់អ្នកបង្កើត

របៀបរកលុយលើ Substack ឆ្នាំ ២០២៦៖ យុទ្ធសាស្ត្ររកចំណូលសម្រាប់អ្នកបង្កើត
ចង់រកលុយលើ Substack ទេ? ការណែនាំនេះបំបែកវិធីសាស្រ្តរកប្រាក់ដែលបានបង្ហាញឱ្យឃើញ គន្លឹះក្នុងការរីកចម្រើន និងរបៀបដែលអ្នកបង្កើតប្រែក្លាយខ្លឹមសារទៅជាប្រាក់ចំណូល។
- ក្លូដចុះខ្សោយ ឬមិនអាចទាក់ទងក្លូដបាន? របៀបវិនិច្ឆ័យ និងជួសជុលបញ្ហាទូទៅ

ក្លូដចុះខ្សោយ ឬមិនអាចទាក់ទងក្លូដបាន? របៀបវិនិច្ឆ័យ និងជួសជុលបញ្ហាទូទៅ
តើ Claude មិនដំណើរការទេ ឬអ្នកកំពុងឃើញកំហុស "មិនអាចទាក់ទង Claude បាន"? ស្វែងយល់ពីរបៀបជួសជុលរង្វិលជុំចូល កំហុសផ្ទៀងផ្ទាត់ បញ្ហាបណ្តាញ និងច្រើនទៀត។
- Instagram ត្រូវបានចាក់សោរ ហើយត្រូវបានហាមឃាត់? តើធ្វើដូចម្តេចដើម្បីយកវាមកវិញ?

Instagram ត្រូវបានចាក់សោរ ហើយត្រូវបានហាមឃាត់? តើធ្វើដូចម្តេចដើម្បីយកវាមកវិញ?
Instagram បានចាក់សោគណនីរបស់អ្នក ហើយបន្ទាប់មកបានហាមឃាត់វា? ការណែនាំនេះគ្របដណ្តប់លើអ្វីដែលត្រូវធ្វើ និងរបៀបស្តារគណនីដែលត្រូវបានចាក់សោ ឬបិទជាបណ្ដោះអាសន្ន។
