
6 Técnicas para Realizar Web Scraping em Websites de E-commerce com Eficiência
A extração de dados de e-commerce é uma ferramenta poderosa para empresas que desejam entender o mercado e melhorar seu desempenho. No entanto, ela também apresenta alguns desafios, que podem dificultar o processo de coleta de dados.
Além disso, alguns sites estão tomando medidas para impedir que seus dados sejam extraídos, o que adiciona outra camada de complexidade à tarefa. Nesse mundo cada vez mais data-driven, saber superar esses obstáculos é fundamental para se manter competitivo e lucrativo.
Este blog post oferece cinco dicas essenciais para garantir uma extração de dados de e-commerce sem problemas. Essas estratégias ajudarão você a superar desafios comuns e coletar os dados necessários de forma eficiente.
Então, continue lendo e aprenda como fazer web scraping em e-commerce como um profissional. Mas antes de pular para as dicas, vamos entender rapidamente a importância da extração de dados para o e-commerce.
O e-commerce é o setor que mais utiliza web scraping!
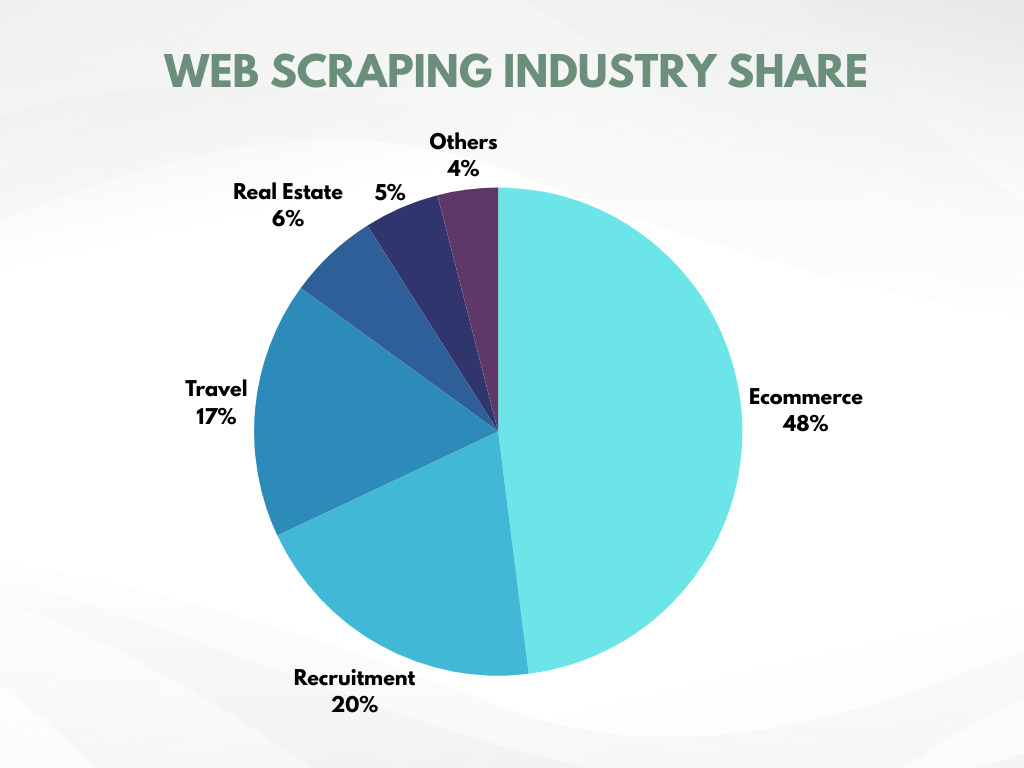
Um estudo recente revelou que o e-commerce realiza 48% de todas as atividades de web scraping na internet. Esse número por si só já revela a importância crucial do web scraping na coleta de dados.
Pesquisas adicionais mostram que empresas que adotam estratégias baseadas em dados superam seus concorrentes. Essas empresas dependem fortemente do web scraping, pois é o único método capaz de coletar automaticamente grandes volumes de dados da internet de forma rápida e com mínimo esforço.
5 Dicas para Extração de Dados E-commerce sem Imprevistos + Bônus Exclusivo
Na última vez, orientamos você sobre como raspar sites de e-commerce. Mas antes de iniciar sua jornada de extração de dados em e-commerce, é vital seguir algumas dicas para maximizar sua eficácia e obter os melhores resultados.

Utilize Geotargeting
O geotargeting deve ser sua estratégia principal se você busca insights de dados específicos para diferentes regiões. Ele não apenas ajudará a desenvolver produtos de acordo com os problemas de clientes regionais, mas também permitirá:
- Identificar oportunidades de mercado
- Analisar a concorrência
- Criar estratégias de marketing ou preços direcionados
No entanto, ao raspar grandes quantidades de dados repetidamente, você enfrentará desafios. Essa atividade pode sinalizar o web scraper como um bot e levar ao bloqueio. Muitos sites restringem o acesso a usuários dentro de sua localização geográfica, detectando e bloqueando endereços IP externos.
A solução mais fácil para esse problema é a rotação de IP. Os web scrapers podem mascarar seus endereços IP e parecer acessar o site de vários locais, como usuários reais usando proxies. Este método também disfarça o comportamento de bot do scraper e evita o bloqueio.
Mas se o site que você está lidando possui medidas anti-scraping avançadas, é necessário usar IPs residenciais. Fornecidos por provedores de internet na região-alvo, eles têm menor probabilidade de serem detectados. Proxies gratuitos não são recomendados, pois os sites geralmente possuem listas de IPs conhecidos e os bloqueiam ativamente.
Reduza a Velocidade de Scraping
Sites de e-commerce costumam limitar o número de requisições que um usuário pode enviar em um determinado período. Isso se torna um desafio para o scraping, pois normalmente ele envia várias requisições em pouco tempo. Essa alta frequência de requisições é anormal comparada ao comportamento de navegação humana e pode fazer com que os servidores identifiquem o scraper como um bot e bloqueiem seu IP.
Para evitar a detecção e o bloqueio, a chave é reduzir a velocidade do scraping. O scraper pode imitar o comportamento humano de navegação implementando pausas aleatórias entre as requisições ou adicionando comandos de espera. Essa abordagem reduz o risco de acionar o sistema anti-bot do site e permite o scraping de e-commerce sem bloqueios.
Drible os CAPTCHAs
Websites geralmente geram CAPTCHAs em resposta a atividades que identificam como suspeitas. Isso interrompe o scraping de e-commerce, pois os scrapers normalmente não possuem mecanismos para resolver CAPTCHAs, e a automatização desses testes é complexa.
Uma solução potencial é utilizar serviços de resolução de CAPTCHAs, que contam com pessoas reais para resolvê-los por uma taxa. No entanto, depender exclusivamente desses serviços pode se tornar financeiramente inviável. Ferramentas para automatizar a resolução de CAPTCHAs também existem, mas podem sofrer de problemas de confiabilidade, principalmente porque os sites atualizam constantemente seus mecanismos para torná-los mais complexos.
Diante desse cenário, a solução mais eficaz é atacar a raiz que gera a necessidade dos CAPTCHAs. O segredo é configurar seu web scraper para imitar o comportamento de um usuário real. Isso inclui estratégias como evitar armadilhas ocultas, usar proxies e rodar IPs e cabeçalhos, além de eliminar pistas de automação.
Evite sistemas anti-bot
Sites usam informações do cabeçalho HTTP para criar uma impressão digital do usuário. Isso ajuda a identificar e monitorar usuários, diferenciando bots de humanos.
O cabeçalho contém uma cadeia de caracteres User-Agent que os sites coletam quando você acessa o servidor deles. Essa sequência geralmente inclui detalhes sobre o navegador e dispositivo em uso. Isso não é um problema para usuários comuns, que usam navegadores, dispositivos e sistemas operacionais comuns. No entanto, como os scrapers geralmente não acessam por meio de um navegador padrão, a cadeia User-Agent deles revela sua identidade de bot.
Uma solução para esse problema é editar manualmente a cadeia User-Agent por meio de scripts. Para isso, basta substituir elementos comuns no lugar do nome do navegador, versão e sistema operacional.
Veja como fazer isso;
Mas ainda há risco de ser detectado se você fizer várias solicitações usando a mesma sequência UA. Então, para aumentar a segurança, você pode usar uma lista de diferentes sequências UA em seu script e alternar entre elas aleatoriamente para não ativar o sistema anti-bot.
Para uma solução mais infalível, você pode usar ferramentas de automação de navegador como Selenium ou Puppeteer para coletar dados usando um navegador anti-detect como o AdsPower. Esses navegadores possuem medidas integradas para se proteger contra a impressão digital usando diversas técnicas, como mascaramento, modificação e rotação da impressão digital do usuário.
Cuidado com sites dinâmicos
Sites dinâmicos alteram o conteúdo e o layout das páginas com base nos visitantes. Mesmo para o mesmo visitante, eles podem mostrar páginas diferentes em visitas separadas devido a fatores como:
- Localização
- Configurações
- Fuso horário
- Ou ações do usuário, como hábitos de compra
Em contraste, sites estáticos exibem o mesmo conteúdo para todos os usuários. Isso representa um desafio para o web scraping de e-commerce, pois as páginas dos sites dinâmicos que você precisa extrair não existem até serem carregadas em um navegador.
Você pode superar esse desafio automatizando o Selenium para carregar as páginas da web dinâmicas em um navegador visível (headless) e depois extrair o conteúdo delas. Mas esperar que todas as páginas carreguem totalmente em um navegador real pode levar uma eternidade, pois o Selenium não suporta clientes assíncronos.
Como alternativa, você pode usar o Puppeteer ou o Playwright, que permitem o web scraping assíncrono, onde o scraper pode solicitar outras páginas da web enquanto as páginas solicitadas carregam. Dessa forma, o scraper não precisa esperar pela resposta de uma página, e o processo se torna muito mais rápido.
Bônus: use AdsPower para Web Scraping de E-commerce sem Riscos
Embora essas dicas possam ajudar até certo ponto com os desafios de extrair dados de sites de e-commerce, elas não são totalmente à prova de falhas. Por exemplo, mesmo extraindo em velocidades mais lentas ou durante horários de pico, pode não evitar a detecção por sites com mecanismos avançados anti-scraping. Da mesma forma, a rotação de IP e proxies ainda podem deixar os scrapers vulneráveis à detecção. Todas essas limitações destacam a necessidade de uma solução à prova de falhas para garantir uma experiência de web scraping de e-commerce perfeita. É exatamente para isso que o AdsPower foi criado. O AdsPower possui todas as técnicas para disfarçar seu scraper como um usuário real, mantendo-o oculto e evitando a detecção.
Ele consegue isso mascarando as impressões digitais do seu scraper, o que impede que os sites o sinalizem e gerem CAPTCHAs como obstáculos. Além disso, o AdsPower combina as vantagens de navegadores headless e headful para enfrentar os desafios impostos por sites dinâmicos.
Além desses recursos, o AdsPower também permite a criação de vários perfis em paralelo para ampliar o processo de extração de dados. Ele também auxilia na automação da raspagem de dados de comércio eletrônico para economizar tempo e recursos.
Domine o Poder dos Dados!
Embora o web scraping de e-commerce venha com uma boa dose de desafios, desde sistemas anti-bot avançados até as complexidades de sites dinâmicos, esses obstáculos podem ser superados.
Você pode aprimorar o web scraping de e-commerce usando dicas eficazes como:
- Segmentação geográfica: direcionar sua captura de dados para regiões específicas.
- Controle de velocidade: diminuir a velocidade do scraping para não levantar suspeitas.
- Burlar sistemas anti-bot: aprender a contornar esses mecanismos de defesa.
- Adaptação a sites dinâmicos: ser ágil para lidar com sites que mudam sua estrutura constantemente.
- Prevenção de CAPTCHAs: implementar técnicas para evitar a geração desses testes anti-bots.
E para tornar tudo ainda mais completo, não há melhor plataforma do que o navegador anti-detect da AdsPower para manter seu scraper invisível aos sites.
Com essas dicas em prática, você estará pronto para aproveitar o poder dos dados!

As pessoas também leem
- Melhores sites de música desbloqueados para escola e trabalho (2026)

Melhores sites de música desbloqueados para escola e trabalho (2026)
Descubra os melhores sites de música desbloqueados para escola e trabalho.
- Melhores ideias de renda passiva no Reddit para iniciantes (Guia de 2026)

Melhores ideias de renda passiva no Reddit para iniciantes (Guia de 2026)
Procurando ideias para renda passiva? Descubra 5 maneiras comprovadas pelas quais usuários do Reddit ganharão dinheiro em 2026.
- É possível visualizar Stories do Instagram anonimamente? Um guia completo para 2026.

É possível visualizar Stories do Instagram anonimamente? Um guia completo para 2026.
Aprenda como visualizar Stories do Instagram anonimamente em 2026 e descubra o melhor método para suas necessidades de privacidade e navegação.
- É possível ter várias contas Polymarket? Regras, riscos e melhores práticas (2026)

É possível ter várias contas Polymarket? Regras, riscos e melhores práticas (2026)
Este guia explica as regras da Polymarket sobre múltiplas contas, os riscos potenciais envolvidos e as melhores práticas para gerenciá-las com segurança e eficiência.
- Os 12 melhores jogos que não são bloqueados pela escola (e soluções fáceis)

Os 12 melhores jogos que não são bloqueados pela escola (e soluções fáceis)
Descubra 12 jogos gratuitos desbloqueados para a escola e aprenda maneiras práticas de acessar sites de jogos bloqueados.
