
Cum să folosești proxy-uri pentru scraping web fără a fi blocat
Aruncă o privire rapidă
Utilizarea rațională și eficientă a proxy-urilor vă va ajuta să extrageți date web fără a fi blocați. Descoperiți sfaturi pentru a menține anonimatul și a extrage date fără probleme. Sunteți gata să vă optimizați procesul de extragere? Explorați ghidul nostru și începeți să extrageți date mai inteligent astăzi!
Web Scraping este o tehnică utilizată pentru extragerea datelor din paginile web. Funcționează prin trimiterea de solicitări către site-uri web țintă similar cu modul în care o face un browser. Acest lucru permite recuperarea diverselor informații, cum ar fi text, imagini și linkuri.
Web scraping-ul are mai multe aplicații:
-
Comerț electronic: Facilitează monitorizarea prețurilor, ajutând companiile și consumatorii să ia decizii de cumpărare mai bune și să stabilească prețuri competitive.
-
Știri: Permite agregarea din diverse surse, oferind o prezentare generală cuprinzătoare a știrilor pe o singură platformă.
-
Generarea de clienți potențiali: Ajută companiile să găsească clienți potențiali prin extragerea datelor relevante și prin îmbunătățirea eficienței marketingului.
-
SEO: Folosit pentru monitorizarea paginilor cu rezultatele motoarelor de căutare și optimizarea conținutului și strategiilor site-ului web.
-
Finanțe: În aplicații precum Mint (SUA) și Bankin' (Europa), permite agregarea conturilor bancare pentru o gestionare eficientă a finanțelor personale.
-
Cercetare: Ajută persoanele fizice și cercetătorii să creeze seturi de date care altfel ar fi inaccesibile, promovând cercetarea academică și proiectele bazate pe date.
Dar mulți s-au săturat să aibă proiecte de scraping web blocate sau incluse pe lista neagră. De fapt, este suficient să urmați cât mai multe bune practici pentru a evita un proces nereușit de extragere a datelor web.
Secretul pentru a efectua cu succes extragerea datelor web este să evitați să fiți tratat ca un robot și să ocoliți sistemele anti-boți ale site-ului. Acest lucru se datorează faptului că marea majoritate a site-urilor web nu acceptă extragerea de date și vor face eforturi pentru a bloca procesul.
Această postare vă va ajuta să înțelegeți diversele informații pe care site-urile web le utilizează pentru a împiedica accesarea informațiilor cu crawlere și ce strategii puteți implementa pentru a depăși cu succes aceste bariere anti-boți.
Alegeți proxy-urile potrivite
Principala modalitate prin care site-urile web detectează extractoarele web este prin verificarea adreselor lor IP și urmărirea modului în care se comportă.
Dacă serverul detectează un comportament ciudat sau o frecvență improbabilă a solicitărilor etc. de la un utilizator, serverul blochează acea adresă IP să acceseze din nou site-ul.
Aici intervine utilizarea intervine un server proxy. Proxy-urile vă permit să utilizați adrese IP diferite pentru a crea impresia că solicitările dvs. provin din întreaga lume. Acest lucru ajută la evitarea detectării și blocării.
Pentru a evita trimiterea tuturor solicitărilor de la aceeași adresă IP, vă recomandăm să utilizați un serviciu de rotație IP, care ascunde adresa IP reală la accesarea datelor cu crawlere.
De asemenea, pentru a crește rata de succes, ar trebui să alegeți proxy-ul potrivit. De exemplu, pentru site-uri mai avansate cu mecanisme anti-crawl, proxy-urile rezidențiale sunt mai potrivite.
Merită menționat faptul că calitatea serverului proxy poate afecta foarte mult succesul crawling-ului de date, așa că merită să investești într-un server proxy bun.
Proxy-urile IPOasis pot ajuta companiile să efectueze scraping web fără a fi detectate sau blocate. Proxy-urile lor depășesc restricțiile geografice, rotesc adresele IP și efectuează scraping la scară largă fără a perturba funcționarea normală a site-ului web țintă.
Cu peste 80 de milioane de IP-uri rezidențiale reale din 195 de țări, proxy-urile IPOasis oferă flexibilitatea și scalabilitatea necesare pentru orice proiect de scraping web. Nu va trebui să vă faceți griji niciodată că veți fi blocat din nou în timp ce colectați date web publice.
În plus, proxy-urile IPOasis funcționează în orele de vârf și la scară largă, asigurându-se că clienții au întotdeauna proxy-urile de care au nevoie în orice moment. Evitați să fiți semnalați utilizând sesiuni nelimitate și schimbând locațiile IP ori de câte ori este nevoie. Ai încredere în fiabilitatea și eficacitatea proxy-urilor de scraping pentru nevoile de colectare a datelor.
Gestionați ratele de solicitare
-
Încetiniți solicitările: Deoarece trebuie să imitați comportamentul utilizatorilor obișnuiți, evitați trimiterea unui număr mare de solicitări într-o perioadă foarte scurtă de timp. Niciun utilizator real nu navighează pe un site web în acest fel, iar acest comportament este ușor detectat de tehnicile anti-crawling. De exemplu, dacă utilizatorii umani așteaptă de obicei câteva secunde între încărcările paginilor, atunci ar trebui să spațiați solicitările în mod corespunzător. O regulă generală bună este limitarea numărului de solicitări pe minut în funcție de natura site-ului.
-
Randomizarea intervalului de solicitări: introduceți întârzieri aleatorii între solicitări, de la câteva secunde la câteva minute, pentru a crește caracterul aleatoriu și a evita detectarea. Acest lucru va face ca modelele de trafic să semene mai mult cu cele ale utilizatorilor reali, care pot petrece intervale de timp diferite între acțiunile pe site. Puteți utiliza o funcție de programare pentru a genera numere aleatorii într-un interval pentru a seta întârzierea dintre solicitări.
Setați anteturi adecvate
-
Șir User-Agent: Antetul User-Agent îi spune site-ului ce browser și sistem de operare accesează utilizatorul. O modalitate de a aplica flexibil această strategie pentru a face ca solicitările să pară că provin din browsere și dispozitive diferite este utilizarea mai multor șiruri User-Agent. De exemplu, puteți roti șirurile Utilizator - Agent pentru Chrome pe Windows, Firefox pe Mac și Safari pe iOS.
-
Antetul Referrer: Antetul Referrer face parte din antetul HTTP. Este utilizat pentru a identifica pagina web de pe care este inițiată o solicitare. În termeni simpli, atunci când un browser navighează de la o pagină web la alta, este utilizat pentru a identifica pagina web de pe care a fost inițiată solicitarea. În timp ce browserul navighează de la o pagină web (pagina sursă) la o altă pagină web (pagina de destinație) și trimite o solicitare, antetul Referrer indică paginii de destinație de unde provine solicitarea. Configurarea unui Referrer valid poate face ca solicitările dvs. să pară mai legitime. Dacă căutați o pagină de produs pe un site de comerț electronic, puteți seta Referrer să facă legătura către pagina de categorie a paginii de produs. Aceste strategii ajută la mascarea activității de crawling și la crearea unei interacțiuni umane mai intense cu site-ul, reducând astfel la minimum șansele de declanșare a apărării anti-boți.
Utilizați un browser headless
Un browser headless este un instrument puternic pentru web scraping fără a declanșa sisteme anti-boți. Spre deosebire de bibliotecile standard de scraping web, browserele headless precum Puppeteer sau Selenium reproduc navigarea umană prin încărcarea paginilor web complete, inclusiv JavaScript și conținut dinamic.
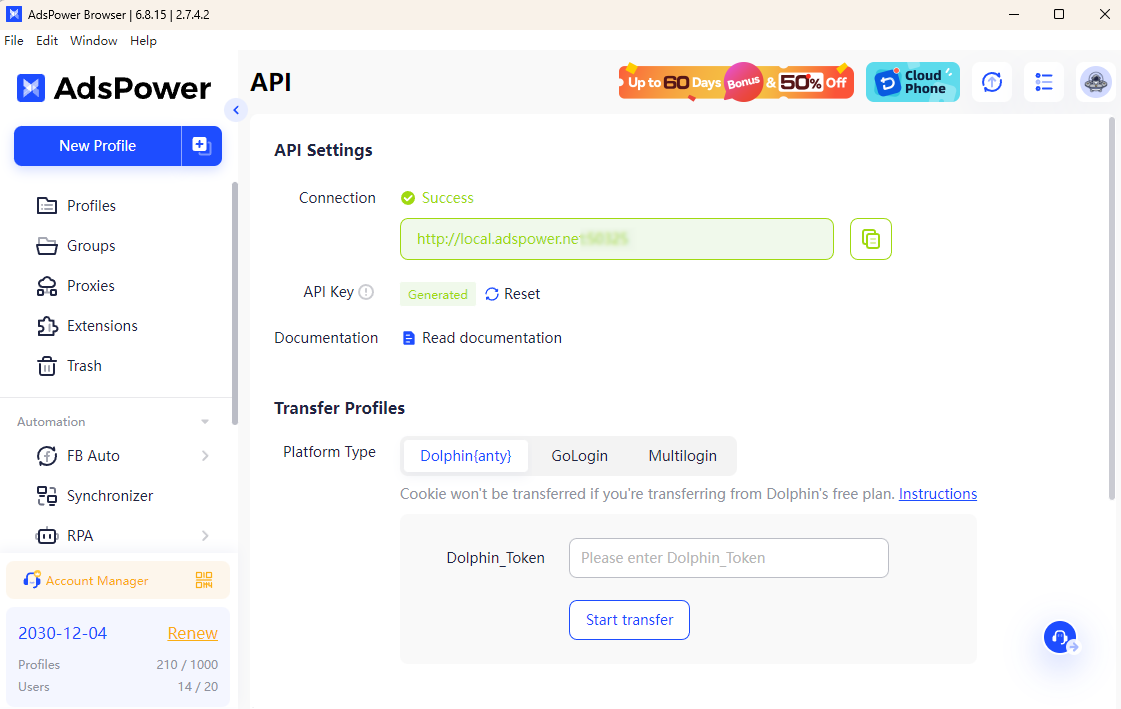
În combinație cu browserul AdsPower, procesul de scraping devine și mai eficient. AdsPower vă permite să porniți modul headlesscu headless și cheie API. Cu acesta, puteți configura amprente digitale unice ale browserului și puteți integra perfect proxy-uri, ceea ce face dificilă detectarea activității automate de către site-urile web. Această combinație oferă un anonimat îmbunătățit și reduce riscul de blocare.
Cu AdsPower, puteți simula un comportament autentic de navigare în timp ce rotiți IP-urile și gestionați mai multe conturi fără efort. Acest lucru asigură o extragere lină a datelor, chiar și pe site-uri cu mecanisme stricte anti-crawling, ceea ce face ca proiectele dvs. de extragere a datelor web să fie relativ reușite și sigure.
Cu metodele practice de mai sus, puteți extrage date de pe site fără a fi blocat. Sunteți gata să vă îmbunătățiți strategia de extragere a datelor web? Începeți să implementați aceste bune practici astăzi și explorați cum AdsPower și proxy-ul IPOasis vă pot eficientiza eforturile.

Oamenii citesc și
- 7 cele mai bune instrumente pentru rezolvarea Captcha în 2026 comparativ (avantaje și dezavantaje)
")
7 cele mai bune instrumente pentru rezolvarea Captcha în 2026 comparativ (avantaje și dezavantaje)
Rezolvatori CAPTCHA 2026 comparați pentru extragerea de date web, viteză, precizie și preț. Găsiți cel mai bun instrument pentru provocările reCAPTCHA și Cloudflare.
- Automatizarea rezolvării CAPTCHA: O comparație a serviciilor de rezolvare CAPTCHA pentru dezvoltatori

Automatizarea rezolvării CAPTCHA: O comparație a serviciilor de rezolvare CAPTCHA pentru dezvoltatori
Compară serviciile de top pentru rezolvarea CAPTCHA în domeniul automatizării. Evaluează viteza, precizia, prețurile și API-urile pentru a alege cea mai bună soluție de rezolvare CAPTCHA.
- Top 11 servicii proxy pentru viteză, anonimat și eficiență (actualizare 2026)

Top 11 servicii proxy pentru viteză, anonimat și eficiență (actualizare 2026)
Acest articol oferă o analiză cuprinzătoare a celor mai rapide 11 servicii proxy disponibile în 2026.
- Cum funcționează închirierea unui cont de publicitate pe Facebook: Un ghid practic pentru agenții de publicitate în creștere

Cum funcționează închirierea unui cont de publicitate pe Facebook: Un ghid practic pentru agenții de publicitate în creștere
Acest ghid explică închirierea unui cont de publicitate Facebook și cum să scalezi în siguranță conturile incluse pe lista albă Meta folosind GDT Agency și AdsPower.
- Cum să maximizezi CTR-ul cu AdsPower × Traffic Bot

Cum să maximizezi CTR-ul cu AdsPower × Traffic Bot
Maximizează-ți CTR-ul în 2025 folosind AdsPower × Traffic Bot. Îmbunătățește clasamentul SEO cu trafic sigur, similar celui uman, și un sistem avansat de detectare a amprentei digitale a browserului.
