
Как парсить в Instagram? 3 способа получить максимальный результат
С учетом более чем 1,3 миллиарда пользователей, Instagram представляет собой ценный источник данных для бизнеса, который можно использовать для исследований рынка, генерации потенциальных клиентов и мониторинга производительности. Однако собирать эти данные с Instagram довольно сложно.
Процесс имеет множество сложностей, возникающих из-за политики Instagram или технических непоняток.
Эта статья отвечает на вопрос, как получать данные с Instagram 3-мя способами, включающих методы с использованием кода, а также без него.
Законен ли парсинг Instagram?
Ответ на вопрос "Является ли сбор данных с Instagram законным?" является как да, так и нет, и это зависит от типа данных, которые вы собираете. Если вы хотите собирать данные из Instagram, которые доступные публично, то ответ - да.
Но если вы собираете данные из Instagram, которые требуют авторизации в учетную запись Instagram, то это явно запрещено, и вы можете столкнуться с блокировкой аккаунта и в худшем случае - с юридическими последствиями. Но даже для общедоступных данных вам следует обеспечить легитимный способ парсинга.
Для сбора данных с Instagram легальным образом можно использовать API, который предоставляет Instagram. К ним относятся API-интерфейс Graph Instagram и API-интерфейс Basic Display Instagram.
API-интерфейс Graph позволяет управлять и извлекать данные о бизнес-аккаунтах и аккаунтах создателей. А API-интерфейс Basic Display дает вам только доступ для чтения к основной информации пользователей. Оба этих API соответствуют политике Instagram относительно сбора данных, поэтому использование их для парсинга в Instagram является абсолютно законным.
Однако если вы используете не общедоступные API или незаконные методы, которые обращаются к платформе без предварительного разрешения и часто маскируют парсер, чтобы выглядеть как обычный пользователь, то это относится к несанкционированному сбору и нарушает Условия использования Instagram.
Так что прежде чем начать собирать данные из Instagram, задумайтесь и убедитесь в том, что вы помните и не нарушаете правила.
Какие данные Instagram вы можете легко получить?
Прежде чем показать вам, как собирать данные из Instagram, давайте сначала выясним, какие данные можно законно парсить с платформы. Легальный парсинг страниц Instagram может дать вам доступ к этим трем категориям данных:
-
Хэштеги: Вы можете получить самые популярные или недавно опубликованные фотографии и видео, помеченные определенным хэштегом в подписи.
-
Профили: Вы можете получить данные профиля, такие как публикации, количество лайков и количество подписчиков/подписок.
-
Посты:Вы можете получить количество комментариев, количество лайков, идентификатор профиля, дата публикации и URL-адрес.
3 способа парсинга Instagram
Вот три способа парсинга Instagram. Выберите тот, который соответствует вашим потребностям и возможностям:
Парсинг Instagram с использованием Instagram API
Вот пошаговое руководство о том, как парсить Instagram, но сначала убедитесь, что вы выполнили следующие требования:
-
Бизнес-аккаунт Instagram/аккаунт автора
-
Страница Facebook, связанная с учетной записью Instagram Business/Creator
-
Аккаунт разработчика Facebook для использования API Instagram Graph
-
Зарегистрированное приложения Facebook с минимальными настройками.
Как только вы закончите с этими предварительными условиями, следующие этапы будут выглядеть следующим образом.
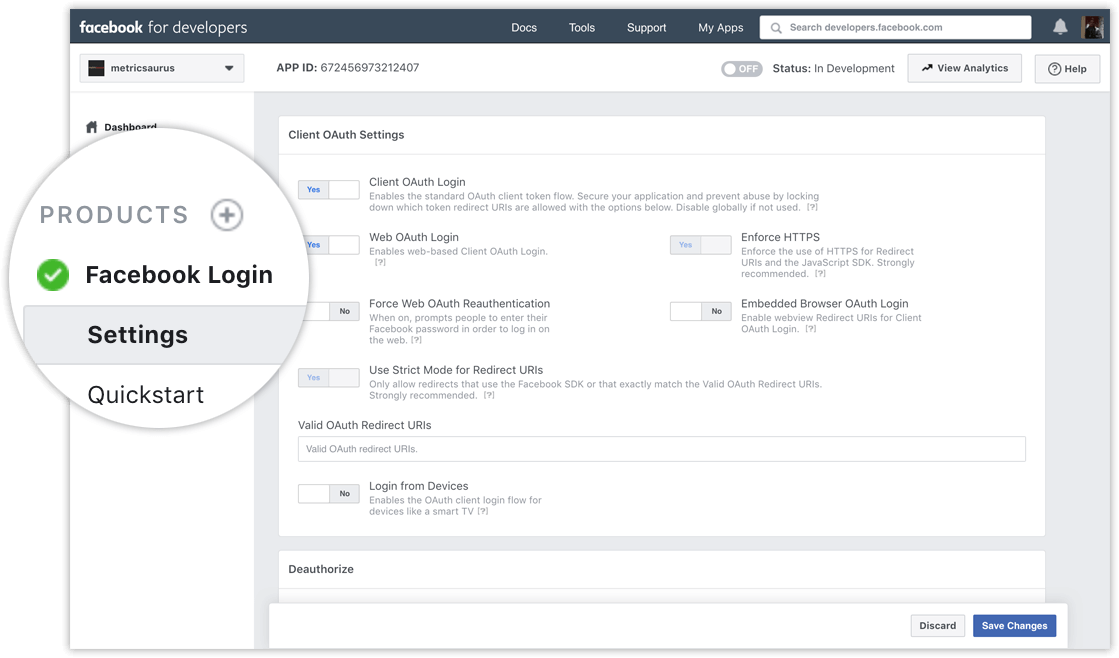
Добавьте функцию входа в Facebook:
Перейдите на панель управления вашего приложения Facebook и нажмите кнопку «Продукт +» на панели в левой части окна. Оттуда добавьте продукт для входа в Facebook. На данный момент не меняйте настройки этого продукта и оставьте их по умолчанию.
Далее вам нужно будет реализовать вход через Facebook в свое приложение с помощью документации по авторизации в Facebook и убедиться, что ваша процедура входа запрашивает эти два основных разрешения:
Создайте токен доступа:
Для выполнения действий с панели приложения на аккаунте Instagram требуется токен доступа пользователя. В правой части страницы панели управления откройте выпадающий список Пользователь или Страница и выберите Получить токен доступа пользователя.
Появится всплывающее окно, уведомляющее, что приложение (в данном случае ваше приложение) запрашивает вышеперечисленные разрешения. Просто нажмите кнопку Продолжить или ОК, и токен доступа пользователя будет получен в поле токена доступа на вашей панели управления.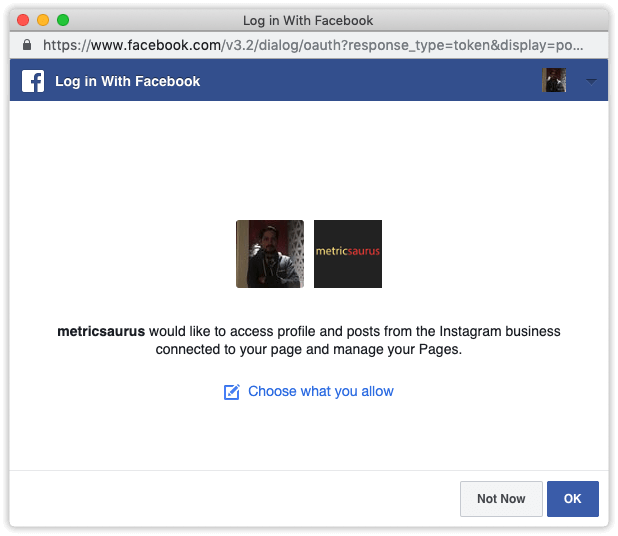
Теперь, используя токен доступа пользователя, мы выполним несколько основных запросов к аккаунту Instagram.
1. Get Facebook Page ID:
Во-первых, нам нужен ID страницы Facebook, связанный с аккаунтом Instagram Business. Для этого выполните следующий запрос Get на панели мониторинга.
Это вернет имя и идентификаторы страниц Facebook, принадлежащих пользователю Facebook. Результат будет выглядеть следующим образом.
Скопируйте ID страницы, подключенной к бизнес-аккаунту Instagram.
2. Получите ID бизнес-аккаунта Instagram:
Используя ID от Facebook, введите следующий скрипт в командной строке и нажмите «Отправить».
Вы получите следующий результат.
3. Получите медиа-объекты аккаунта Instagram:
Скопируйте ID Instagram из выходных данных и выполните следующий скрипт, чтобы получить идентификаторы всех историй, опубликованных в настоящее время в бизнес-аккаунте Instagram.
Результат будет содержать идентификатор для каждой истории.
Это был лишь один пример. С помощью Instagram Graph API вы также сможете получать другую информацию, включая метаданные пользователей Instagram и проводить анализ хэштегов.
Теперь давайте перейдем к другому способу.
Парсинг Instagram с помощью Cloud Scrapper
Для тех, у кого нет опыта в программировании, вышеупомянутый метод может быть сложен для понимания, не говоря уже о его выполнении. Но не беспокойтесь. Существуют инструменты для парсинга в Instagram, которые позволяют выполнять данную задачу без необходимости написания какого-либо кода.
Парсинг также можно выполнить с использованием инструмента под названием Apify.
Перейдите на страницу парсера Apify:
Посетите страницу Apify Instagram Scraper и нажмите кнопку «Попробовать бесплатно».
Зарегистрируйтесь в Apify, используя адрес электронной почты или аккаунт Google или Github. Вы попадете в консоль управления Apify, где происходит парсинг Instagram.
Соберите целевые URL-адреса Instagram:
Используя приложение или сайт Instagram, соберите все URL-адреса профилей Instagram, которые вы хотите спарсить. В консоли Apify вставьте все эти URL-адреса в указанные поля ввода по очереди. Чтобы внести их все сразу, можете использовать кнопку «Массовое редактирование».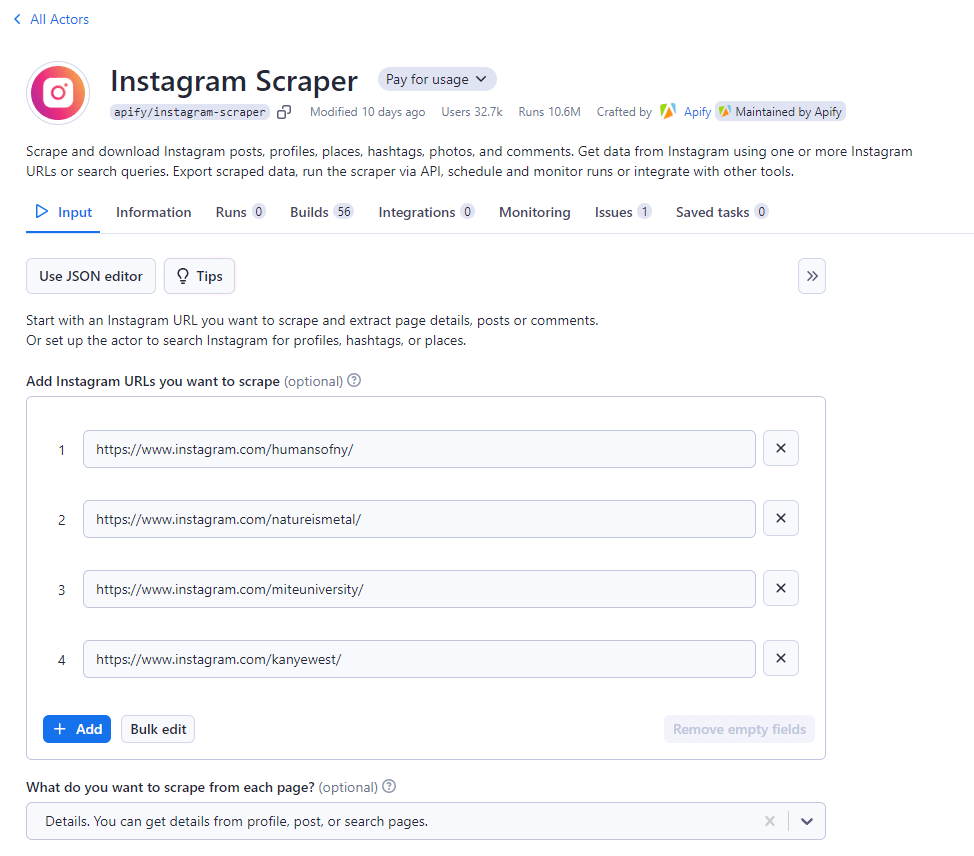
Apify предлагает три варианта парсинга предоставленных URL-адресов: вы можете парсить сообщения и комментарии или получать различные сведения из профилей.
Нажмите “Сохранить и запустить”:
Оставьте остальные настройки без изменений и нажмите "Сохранить и запустить", чтобы запустить парсер. Результатом будет таблица, содержащая количество строк, равное количеству URL-адресов профилей, которые вы предоставили, а также несколько столбцов с метаданными профиля, такими как биография, количество подписчиков, количество публикаций, количество рилов, ID аккаунта и статус верификации, чтобы упомянуть лишь некоторые из них.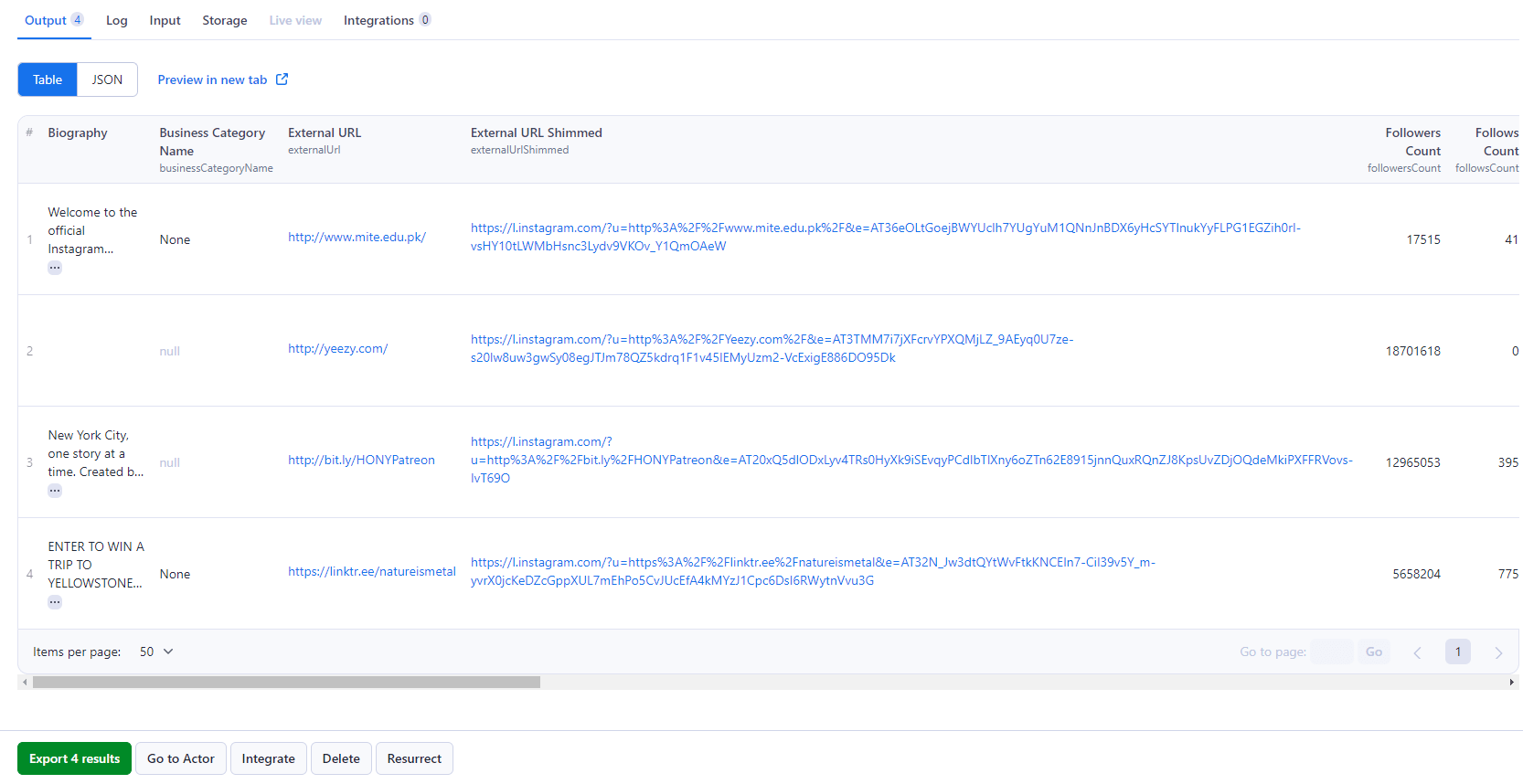
Соберите результаты:
Теперь нажмите кнопку "Экспорт результатов" и выберите желаемый формат файла из всплывающего окна. Вы также можете собрать данные, выбрав или исключив поля, которые вам не нужны. После этого вы сможете скачать результаты, просмотреть их в новой вкладке или поделиться по ссылке.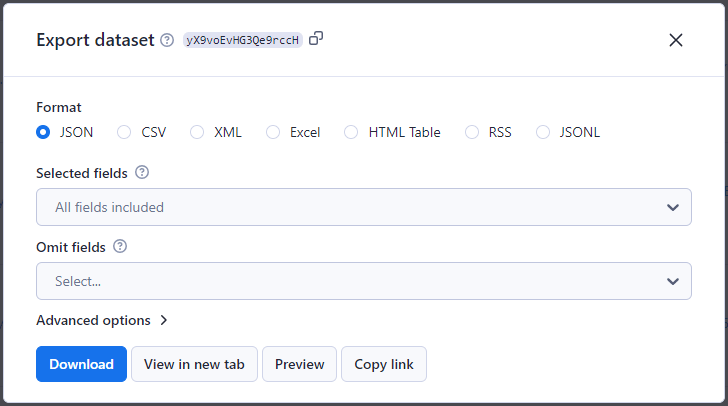
Парсинг Instagram с помощью языков программирования
Создание собственного парсера Instagram может стать наиболее эффективным решением, если ваши требования нестандартны, и у вас есть хорошие знания в программировании либо разработчик в команде. Вы можете сделать это, используя любой язык программирования совместим с фреймворком для веб-парсинга.
Это руководство покажет, как выполнить парсинг в Instagram с использованием Python и Selenium, фреймворка автоматизации браузера.
Импорт основных библиотек:
Для начала импортируйте базовые библиотеки: Selenium, его веб-драйвер и Selenium-Stealth, чтобы предотвратить идентификацию.
Библиотека pprint поможет нам аккуратно распечатать результат и повысить его читабельность.
Составьте список профилей Instagram:
Составьте список и добавьте никнеймы профилей Instagram, на которые вы ориентируетесь.
Переменная output - это словарь, который мы будем использовать для хранения результатов.
Определим основную функцию:
Главная функция будет последовательно обходить список пользователей и вызывать функцию "scrape" для каждого пользователя.
Определите функцию для управления настройками браузера:
Эта функция будет настраивать параметры браузера перед каждым запросом на парсинг, чтобы добавить анонимности и избежать обнаружения со стороны Instagram. Эти изменения включают в себя ротацию прокси, настройку параметров Selenium-Stealth и создание искусственного юзер агента.
Определите функцию для парсинга:
Функция scrape(), вызванная в главной, принимает в качестве аргумента единственное имя пользователя Instagram и создает конечную точку профиля, которую мы будем использовать для отправки запроса через браузер Chrome с помощью функции preparebrowser().
Мы также будем проверять статус запроса. Если ваш запрос был перенаправлен на страницу входа в систему, это означает, что запрос не удался. Если же строка для входа отсутствует, запрос был успешным, и результат будет разобран в формате JSON и отправлен в функцию prepare_browser() function вместе с именем пользователя.
Определите функцию parse_data():
Эта функция анализирует данные в формате JSON, переданные в аргументе userdata, чтобы получить необходимые поля данных. В данном примере, мы извлекаем полное имя пользователя, категорию аккаунта, количество подписчиков и заголовки постов.
Напишите код драйвера:
The driver code начинает процесс парсинга, извлекает данные в переменную output и вызывает функцию pprint() для красивого отображения результатов.
Обход обнаружения с помощью антидетект браузера AdsPower
Инстаграм достаточно строг, когда речь идет о парсинге, и предоставляет очень ограниченный доступ к публичным данным на своей платформе. Это включает в себя базовую информацию, такую как идентификатор профиля, количество подписчиков, количество лайков и комментариев. Углубленный анализ требует авторизации в систему, что нарушает политику Инстаграм и может привести к блокировке аккаунта.
Здесь на помощь приходит AdsPower, помогая вам сохранить анонимность профиля при парсинге данных с Инстаграм. AdsPower использует антидетект-техники, такие как ротацию IP-адресов и ограничение скорости, чтобы избежать защитных мер против парсинга.
Так что в следующий раз, когда вы займетесь парсингом в Инстаграм, используя no-code-инструменты или неофициальные API, попробуйте использовать браузер AdsPower для обхода обнаружения.
Итоги
Инстаграм разрешает собирать только общедоступные данные с их платформы при помощи двух API. Но эти API предоставляют очень ограниченный доступ к информации, и не позволяют получить действительно важные данные.
Из-за этого остается только использовать сторонние веб-парсеры или создать свой с помощью языков программирования. Однако, парсинг Инстаграм с использованием этих неофициальных методов может быть обнаружен, поэтому обязательно используйте специальный антидетект браузер AdsPower для дополнительной защиты.

Люди также читают
- Мистер Бист: Самый богатый ютубер и его успешная стратегия заработка на YouTube в 2025 году
- Как заработать на Adsense? До 5000 руб. в день!
- Как заработать с Outlier AI и получать деньги за обратную связь для ИИ
- Как безопасно управлять несколькими аккаунтами агента Zillow в 2025 году
- Что делать, если Амазон заблокировал аккаунт
