
Подробное руководство по использованию парсинга Amazon
Если правильно парсить Amazon, это может быть очень выгодно для бизнеса. Не верите нам? Подумайте над этой историей о сайте, который всего за два месяца заработал невероятные 800 тысяч долларов, просто ежедневно парся отзывы на Amazon. Круто, да?
Мы не обещаем, что вы заработаете кучу денег за одну ночь, но мы можем научить вас, как парсить Amazon, чтобы попытаться достичь этого.
Поэтому читайте этот блог, чтобы узнать о двух способах парсить Amazon: один из них - это использование парсинга Amazon без кода, а другой - создание парсинга Amazon на Python с помощью кода.
Но сначала давайте узнаем, можно ли парсить Amazon.
Законно ли парсить Amazon?
Когда речь идёт о парсинге Amazon, правила немного размыты. Файл robots.txt Amazon определяет допустимые параметры парсинга в длинном списке, в котором указано, что можно парсить, а какие области строго запрещены.
Однако файл robots.txt служит лишь этическим ориентиром и не является юридически обязательным. Таким образом, ваш парсинг Amazon может получить доступ к запрещённым зонам, не сталкиваясь с какими-либо проблемами.
В то же время Amazon не останавливается на достигнутом. Он пошёл дальше, внедрив технические барьеры, чтобы не дать ботам перегрузить свои серверы.
Например, он применяет такие меры против парсинга, как проверка CAPTCHA и ограничение скорости. Чтобы преодолеть эти препятствия, ваш парсинг Amazon должен обладать такими передовыми методами, как подмена агента пользователя, решение CAPTCHA или задержка запросов; в противном случае ваше начинание по парсингу Amazon так и останется мечтой.
Если кратко ответить на вопрос "Разрешает ли Amazon парсить веб-сайты?", то можно сказать, что законность парсинга данные Amazon не однозначна и зависит от различных факторов, включая
-
тип парсируемых данных
-
методы, используемые для парсинга
-
и цель парсить данные
Если парсинг не предполагает несанкционированного доступа, например, к данным, скрытым за логином, и не перегружает инфраструктуру сайта, он обычно подпадает под категорию безопасных. Верховный суд также защитил компанию, занимающуюся анализом данных, на которую LinkedIn подал иск в соответствии с CFAA, ссылаясь на несанкционированный веб-скрейпинг.
Кроме того, вы должны убедиться, что использование данных, которые вы парсите, законно, то есть вы не перепродаете и не тиражируете их, так как это может иметь серьезные юридические последствия.
Теперь вопрос на миллион долларов: как парсить Amazon?
Как парсить Amazon?
Несмотря на технические сложности, парсинг Amazon не представляет большого труда. Существует множество инструментов для парсинга Amazon, как с кодом, так и без кода, с решениями для борьбы с антиботами Amazon. С помощью этих инструментов вы можете успешно парсить отзывы, товары и цены Amazon, а также другие данные.
Итак, давайте начнем с бескодового парсинга Amazon.
Парсинг Amazon без кода:
Честно говоря, велика вероятность того, что читатель, читающий это, не обладает навыками кодирования. Но это не проблема. Вам не нужны знания кодирования, когда есть парсинги Amazon без кода.
С помощью этих инструментов вы просто указываете URL-адрес страницы продукта или категории, и парсинг получит все данные о продуктах Amazon с этой страницы. Когда он закончит парсинг Amazon, вам также будет предоставлено несколько вариантов сохранения файлов.
Для демонстрации мы выбрали Amazon от Apify. У Apify есть отдельные инструменты для парсинга различных областей Amazon, включая Amazon Product Scraper, Amazon Review Scraper и Amazon Bestsellers Scraper.
В этом руководстве мы будем использовать парсинг Amazon Product Scraper от Apify. Парсинг товаров Amazon имеет функции для решения CAPTCHA и установки прокси-серверов для обхода мер по борьбе с ботами.
Давайте приступим к демонстрации.
Шаг# 1: Посетите страницу Amazon Product Scraper
Зайдите в Amazon Product Scraper в магазине Apify и нажмите кнопку "Try for Free". Этот инструмент позволяет парсить данные о товарах Amazon, включая цены, отзывы, описания товаров, изображения и некоторые другие атрибуты.
Шаг# 2: Создайте свой аккаунт Apify
Если вы новичок, зарегистрируйте аккаунт Apify бесплатно. Платформа предлагает варианты регистрации через электронную почту, Google или GitHub. 
Шаг# 3: Вставьте URL-адреса целевого контента Amazon
В Apify Console введите URL-адрес товара или категории Amazon, которые вы хотите парсить. В данном примере мы использовали категорию "Консоли и аксессуары для видеоигр" и "Мебель".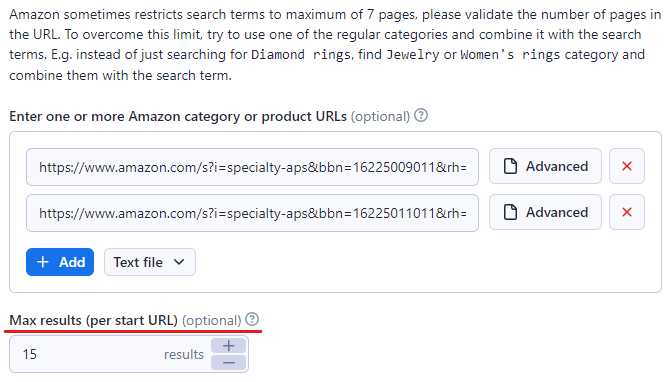
Вы можете вставить больше ссылок, нажав кнопку "+ Add". Или, если ссылок много, вы можете просто добавить их все в текстовый файл и загрузить его для парсинга Amazon.
Также определите максимальное количество предметов, которые вы хотите парсить, установив ограничение в поле 'Max items'. Мы установили значение 15, но вы можете установить его по своему усмотрению.
Шаг# 4: Включите CAPTCHA Solver
Вы не сможете парсить Amazon без CAPTCHA solver. Известно, что Amazon очень эффективно обнаруживает ботов. Как только он заподозрит активность бота, он бросает ему CAPTCHA.
Поэтому, чтобы ваш парсинг Amazon работал без проблем, включите CAPTCHA solving.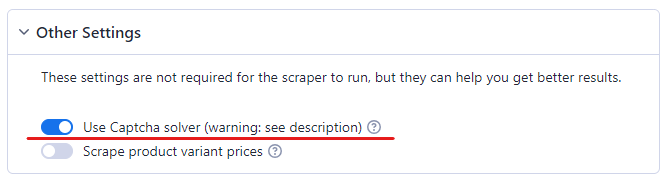
Шаг# 5: Настройте прокси
Использование прокси-сервера необходимо для обхода мер по защите от парсинга. Парсинг Amazon предлагает различные варианты прокси, включая Residential, Datacenter или ваш собственный, для маскировки парсинга и обхода ограничений. О различиях между прокси-серверами Residential и Datacenter читайте в нашем другом блоге.
По умолчанию выбран вариант с residential proxy, так как он лучше всего подходит для систем защиты от парсинга.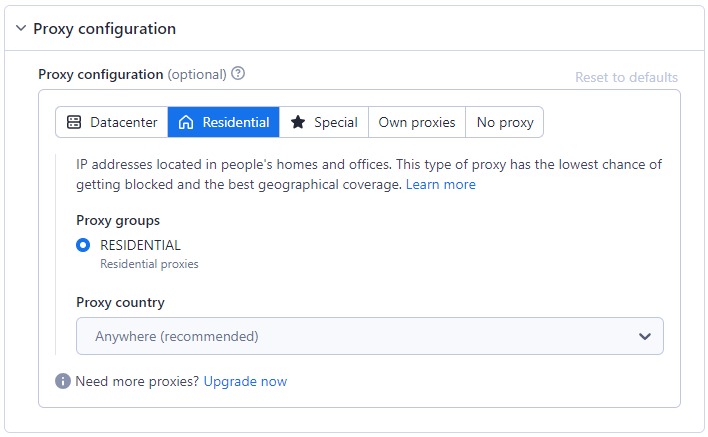
Шаг# 6: Запустите парсинг
Установив параметры, запустите Amazon Product Scraper, нажав кнопку " Start " в нижней части страницы.
После завершения статус изменится с " Running" на "Succeeded".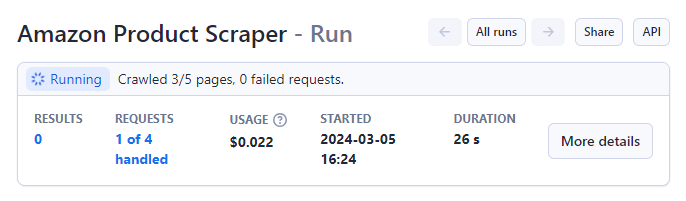
Когда все закончится, вы увидите предварительный просмотр данных на экране.
Шаг# 7: Экспортируйте ваш файл
Нажмите кнопку " Export results", чтобы загрузить собранные данные. Платформа поддерживает множество форматов, включая CSV, JSON и Excel.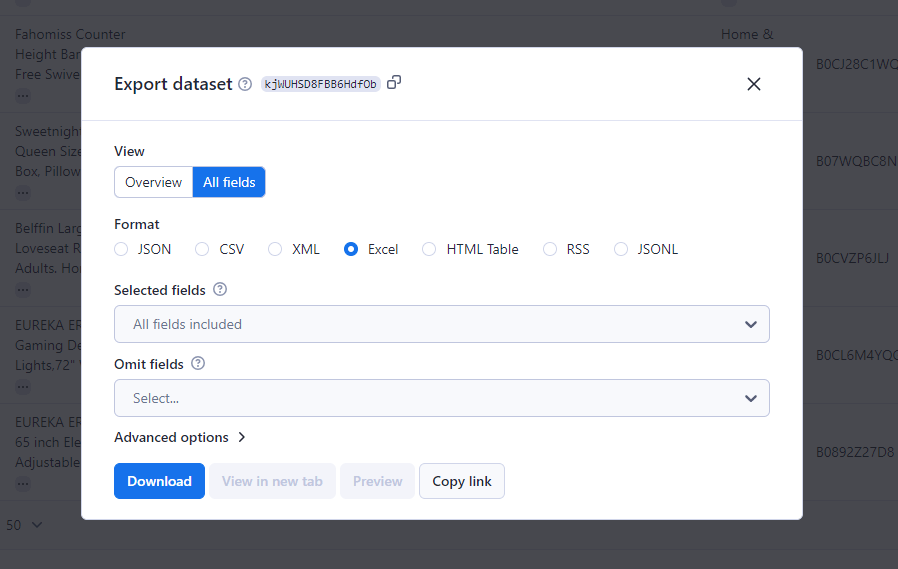
Парсинг Amazon на Python с помощью программирования
В парсинге Amazon без кода, который мы использовали выше, если вы внимательно посмотрите на ранее упомянутый шаг 6, 69 из 173 запросов оказались неудачными. Это происходит потому, что Amazon блокирует эти запросы.
Чтобы обойти эту проблему, вам придется написать собственный скрипт для парсинга. В этом руководстве мы создадим парсинг товаров Amazon на языке Python.
Итак, начнем.
Шаг# 1: Установите Python
Для написания наш парсинг Amazon на Python, необходимо установить Python на вашем компьютере. Рекомендуется скачать последнююверсию для совместимости с необходимыми библиотеками.
Шаг# 2: Импортируйте необходимые библиотеки
Суть любого парсинга Amazon заключается в получении и разборе веб-контента. Для этого мы используем комбинацию библиотек Python.
-
Requests: для выполнения HTTP-запросов к веб-сайту Amazon
-
BeautifulSoup: для навигации и разбора возвращаемого HTML-содержимого
-
lxml: для синтаксического анализа
-
Pandas: для организации и экспорта данных
Прежде чем импортировать их, необходимо установить их с помощью следующей команды:
Теперь мы импортируем их в наш Python-скрипт парсинга Amazon:
Шаг# 3: Настройте заголовки HTTP
Частым препятствием при парсинге веб-сайтов Amazon являются защитные меры Amazon против автоматического доступа. Чтобы избежать этого, наш Python-скрипт для парсинга Amazon имитирует запрос веб-браузера, включая пользовательские HTTP-заголовки, такие как 'User-Agent' и 'Accept-Language'.
Лучше добавить больше заголовков.
Чтобы получить эти заголовки для вашего браузера,
-
нажмите F12 на странице Amazon, чтобы открыть инструменты разработчика,
-
откройте вкладку Сети и выберите Заголовки
-
перезагрузите страницу
-
выберите первый запрос
-
на вкладке "Заголовки" прокрутите вниз до раздела "Заголовки запросов" и скопируйте значения заголовков, упомянутых выше
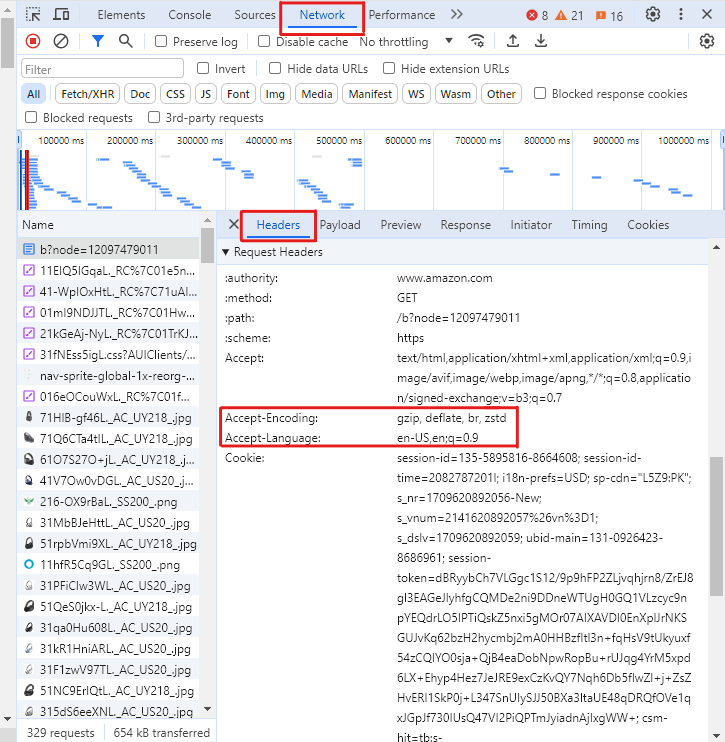
Без этих заголовков велика вероятность того, что Amazon заблокирует запрос GET и вернет ответ, подобный следующему, с кодом состояния_ 503 (ошибка) вместо 200 (успех).
Шаг# 4: Извлечение информации о продукте
Наш парсинг продуктов Amazon включает функцию scrape_amazon_product, которая выполняет важную задачу по извлечению информации о продукте. Функция принимает на вход URL страницы категории Amazon и возвращает словарь с информацией о продукте.
Затем метод отправляет запрос в Amazon, используя URL и переменную пользовательских заголовков, которую мы создали выше.
После этого, используя CSS-селекторы BeautifulSoup, мы получим название, цену, URL-адрес изображения и описание товара с отдельных страниц продукта.
Шаг# 5: Работа с списками товаров и пагинацией
Для сбора обширных данных наш скрипт на Python для парсинга Amazon перемещается по страницам категорий и обрабатывает пагинацию, переходя по страницам списка товаров Amazon.
Он определяет ссылки на товары с помощью CSS-селекторов и отслеживает пагинацию, обнаруживая ссылку "Next" на странице.
Шаг# 6: Сохраните парсированные данные
Наконец, спарсированные данные объединяются в список словарей, который затем преобразуется в Pandas DataFrame. Затем этот DataFrame экспортируется в CSV-файл.
Используйте парсинг Amazon незаметно
Парсить Amazon обычно очень прост. Однако вы можете столкнуться с такими проблемами, как CAPTCHA, блокировка запросов и ограничения скорости.
Чтобы не столкнуться с этими проблемами, используйте антидетект браузера, например AdsPower. AdsPower гарантирует, что ваш парсинг Amazon останется незамеченным, благодаря таким функциям, как подмена отпечатков пальцев и ротация прокси.
Так что регистрируйтесь бесплатно прямо сейчас и начинайте парсить Amazon без проблем.

Люди также читают
- DuckDuckGo браузер действительно анонимен? Вот что вам нужно знать
- Что такое Likee и как создать второй аккаунт в Likee: пошаговое руководство
- Лучшие сайты для удалённой работы и дополнительного заработка
- Хотите купить органический трафик? Вот что действительно работает (и чего стоит избегать)
- Эфиры в Тик Ток: как вести, кто может выйти и зачем это нужно
