
Упрощенный парсинг Pinterest: от готовых инструментов до написания собственного парсера
Pinterest - это не только место для поиска рецептов или красивых картинок, но и множество возможностей для бизнеса.
Как говорит генеральный директор Pinterest Бен Сильберманн, "Вся причина существования Pinterest заключается в том, чтобы помочь людям обнаружить вещи, которые им нравятся, а затем начать действовать в соответствии с ними, и многие действия, которые они предпринимают, связаны с коммерческими намерениями".
В прошлом году число ежемесячно активных пользователей Pinterest перешагнуло через предел и достигло 498 миллионов человек! Это огромное количество людей и огромный потенциал для того, чтобы использовать Pinterest в коммерческих или личных целях.
В этой стать мы покажем вам, как парсить Pinterest с помощью удобного инструмента Pinterest Scraper и более технически сложного способа с использованием Python.
Так что, независимо от того, новичок вы или уже немного разбираетесь в кодинге, мы поможем вам. Но прежде чем мы начнем, давайте узнаем об отношении Pinterest к парсингу.
Законно ли парсить в Pinterest?
В Условиях использования Pinterest прямо указано, что парсинг данных Pinterest и их сбор с помощью автоматизированных инструментов запрещены. Это включает в себя сбор данных с помощью любой формы парсера или программных скриптов.
Но ведь у Pinterest есть официальный API, верно? А как насчет парсинга с помощью Pinterest API? Это тоже запрещено. Pinterest ясно дает понять в своих рекомендациях для разработчиков, что извлечение данных из своей платформы является недопустимым использованием Pinterest API и других инструментов разработчика.
Однако общее правило для большинства платформ гласит, что парсинг разрешен, если данные находятся в открытом доступе и не требуют авторизации. Вам также следует избегать копирования защищенного авторским правом или персонального контента, поскольку это может привлечь юридические последствия.
Короче говоря, если ваш подход к парсингу на платформе Pinterest безвреден, а извлеченных данных законно, то вы находитесь в “безопасных водах”.
Парсеры для Pinterest: готовый и собственный инструмент
Теперь, когда мы поняли юридические последствия парсинга, давайте покажем вам, как использовать парсер Pinterest без применения программного кода, а также как создать собственный парсер с помощью Python.
Готовый инструмент
Поиск данных в Pinterest может показаться довольно непростой задачей, особенно если вы не разбираетесь в программировании. К счастью, готовые инструменты сделали парсинг Pinterest не только возможным, но и удивительно простым.
Apify, Octoparse и ParseHub являются одними из лучших парсеров для Pinterest благодаря своей эффективности и удобному интерфейсу.
В этом руководстве мы будем использовать Apify Pinterest Scraper.
Бот Apify Pinterest превращает сложную процедуру извлечения данных в простой и управляемый процесс. Этот инструмент предназначен для беспрепятственной навигации по Pinterest и извлечения информации с пинов, досок и информации о профиле пользователя.
Вот краткая инструкция, как пользоваться Apify Pinterest Scraper.
Шаг 1: перейдите на сайт Pinterest Scraper в Apify Store
Перейдите в магазин Apify Store и найдите инструмент Pinterest Scraper. Нажмите кнопку "Попробовать бесплатно". 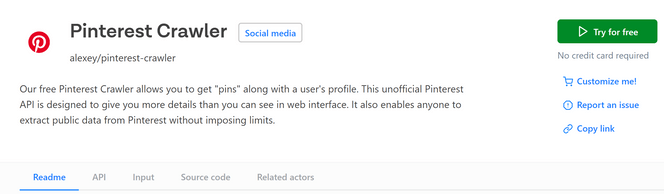
Шаг 2: создайте учетную запись:
Нажав кнопку "Попробовать бесплатно", вы попадете на страницу входа/регистрации. Зарегистрируйтесь на Apify, используя адрес электронной почты и надежный пароль. Или просто используйте свой аккаунт Google или GitHub для быстрого аккаунта.
Если вы уже являетесь членом семьи Apify, начните с шага 3.
После успешной регистрации вы попадете в консоль Apify. Да, вам не придется скачивать расширение для браузера или пакет программного обеспечения!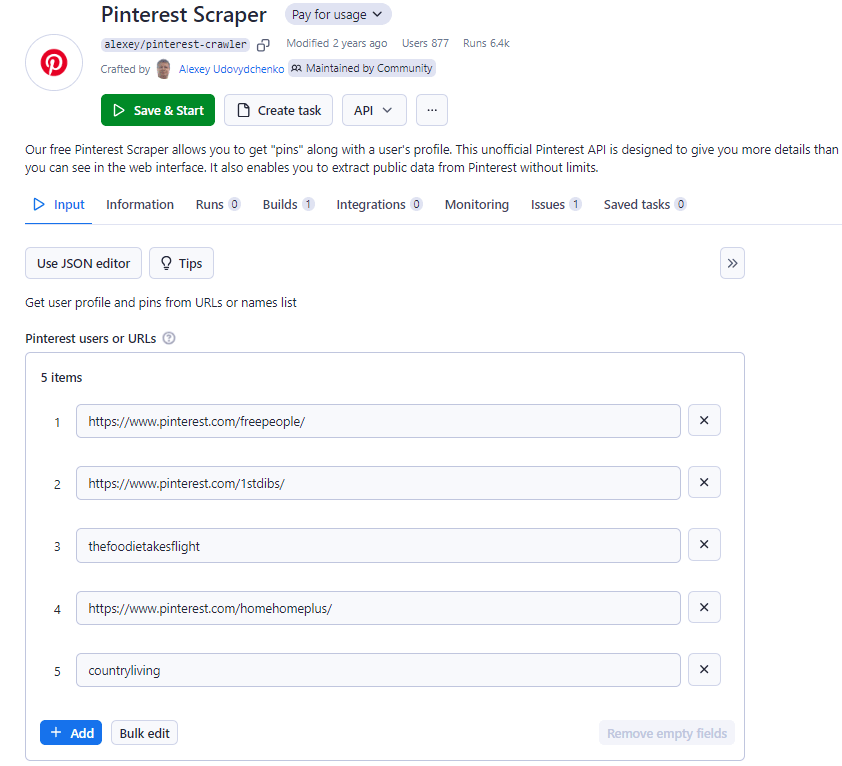
Шаг 3: выберите источник данных Pinterest
В консоли Apify Console вы найдете поле с запросом URL-адреса интересующего вас профиля Pinterest или пинов. Вставьте сюда целевые ссылки на профили Pinterest.
Вы также можете опубликовать их все сразу, нажав кнопку Bulk Edit. 
Шаг 4: запустите процесс парсинга
После того как вы введете все целевые URL и/или имена пользователей, нажмите кнопку "Сохранить и начать", дальше Pinterest Scraper сделает свое дело. 
Вы поймете, процесс закончен, когда статус переключится с "Выполняется" на "Удалось".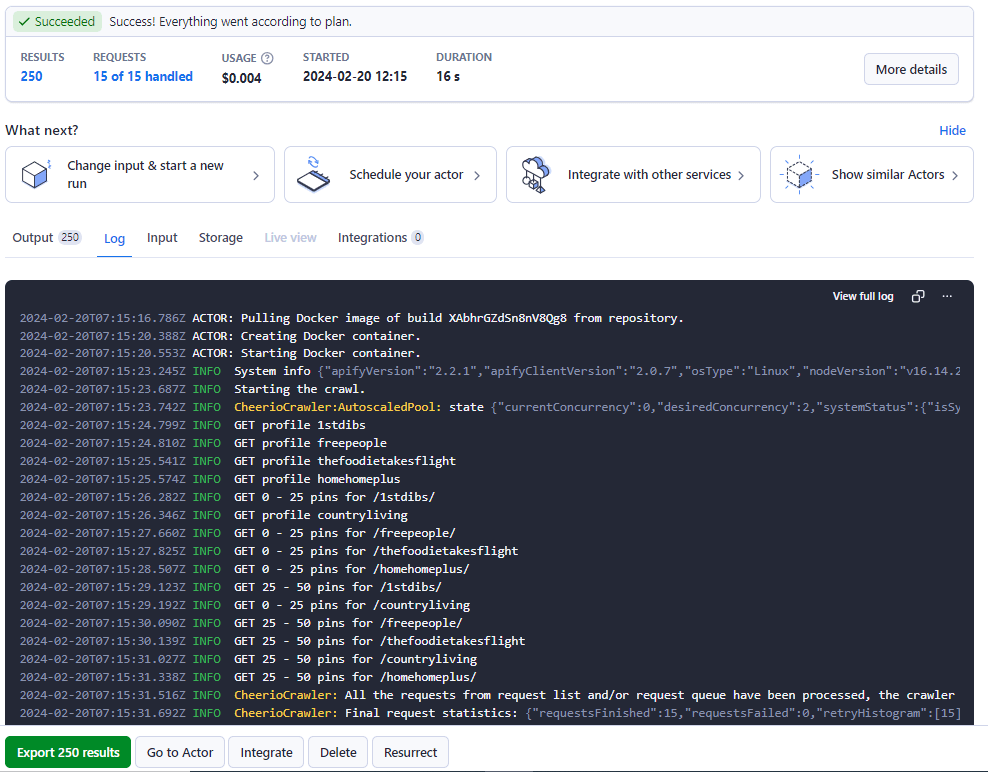
Шаг 5: сохраните данные
Когда работа парсера будет завершена, перейдите на вкладку "Хранилище".
Здесь вы найдете только что собранные данные, которые готовые к просмотру. Вы можете просмотреть их в различных форматах: HTML, JSON, CSV, Excel, XML и даже RSS-ленту. 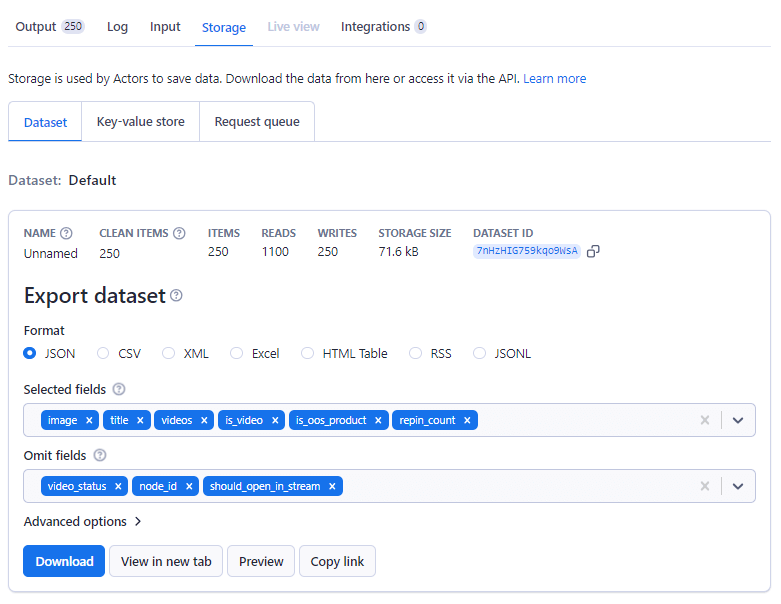
Перед сохранением набора данных у вас есть возможность выбрать определенные поля и пропустить неактуальные. После этого скачайте файл в нужном вам формате.
Парсинг Pinterest с помощью Python
Парсинг с использованием Python может быть довольно простым процессом при наличии правильных инструментов и небольших знаний в области программирования.
Ниже краткое руководство по созданию собственного Pinterest-парсера на языке Python с использованием библиотек requests и BeautifulSoup. Руководство дает поверхностное объяснение процесса, идеально подходит для новичков или тех, кто ищет краткий обзор.
Шаг 1: настройка среды
Убедитесь, что на вашем компьютере установлен Python. Вам также понадобятся библиотеки requests и BeautifulSoup, которые можно установить с помощью pip, если вы этого еще не сделали.
Шаг 2: напишите свой класс парсера
Начните с импорта необходимых модулей:
● requests для выполнения HTTP-запросов к Pinterest и
● BeautifulSoup из bs4 для разбора содержимого HTML
Шаг 3: Загрузка изображений
Создайте в своем классе метод (load_images) для чтения HTML-содержимого страницы, на которой размещены изображения Pinterest. Этот метод считывает данные из локально сохраненного HTML-файла (images.html), который вы должны были предварительно сохранить.
Шаг 4: разбор изображений
Реализуйте еще один метод (parse), который принимает HTML-содержимое в качестве входных данных и использует BeautifulSoup для его разбора. Извлеките атрибуты src из всех тегов <img>, чтобы получить URL-ссылки изображений, которые вы хотите загрузить.
Шаг 5: Загрузка изображений
Напишите метод загрузки, который принимает URL-адрес изображения, извлекает его с помощью метода requests.get и сохраняет локально. Убедитесь, что вы правильно обрабатываете ответ, проверяя успешный код состояния (200), прежде чем приступить к сохранению файла.
Шаг 6: запуск парсера
Определите метод выполнения, который свяжет все воедино: загрузите содержимое HTML, разберите его, чтобы извлечь URL-адреса изображений, а затем загрузите каждое изображение.
Шаг 7: выполните сценарий
Определив класс PinterestScraper, вызовите метод run в блоке if __name__ == '__main__':, чтобы запустить процесс парсинга при выполнении скрипта.
Объединив все приведенные выше фрагменты, мы получим готовый скрипт для парсинга Pinterest:
Это упрощенная инструкция, которая дает вам базовую информацию, чтобы создать собственный парсер с использование Python скрипта.
Выполняйте парсинг на Pinterest, не получая блокировки
Pinterest строго запрещает несанкционированный сбор данных с помощью автоматизированных средств без явного разрешения. Pinterest также может заблокировать доступ для ваших аккаунтов или забанить ваш IP-адрес при обнаружении с действий по сбору данных.
Это создает проблемы для всех, кому необходимо этично сканировать Pinterest для юридических целей.
Но не стоит паниковать. AdsPower предлагает решение. Антидетект браузер AdsPower предназначен для веб-парсинга Pinterest. Он заставляет ваш парсер Pinterest имитировать поведение реального человека, что снижает риск обнаружения.
Он использует методы ротации IP-адресов и подмены отпечатков браузера, чтобы сделать ваш парсер Pinterest более незаметным и эффективным. Инструмент также оснащен полезными функциями для автоматизации процесса парсинга и дальнейшего снижения рабочей нагрузки.
Поэтому, прежде чем приступать к работе с Pinterest, убедитесь, что AdsPower обеспечивает безопасное и бесперебойное присутствие на сайте.

Люди также читают
- DeepSeek нейросеть на русском: что такое DeepSeek и как им пользоваться
- Как заработать с помощью ChatGPT: 100 000 ₽ за неделю и полезные советы
- Что такое нейросеть и как заработать на нейросетях в 2025 году
- Как заработать на Spotify? Вот как люди получают прибыль
- Антидетект браузер партнерских маркетологов: избегайте блокировок и увеличивайте ROI
