
Вот как нужно парсить Reddit: два разных, но эффективных способа
Нет никаких сомнений в том, что данные Reddit имеют огромную ценность, настолько большую, что Google и OpenAI используют их для обучения своих больших языковых моделей (LLM).
Но как парсить Reddit и воспользоваться его ценностью, не потратив при этом ни сил, ни денег?
Неважно, опытный ли вы кодер или тот, кто не знаком со сложным миром программирования, - для вас найдется подходящий метод.
В этой статье вы узнаете, как парсить Reddit двумя простыми способами и получить все богатства информации, которую может предложить Reddit.
Но прежде чем перейти к деталям, давайте вкратце расскажем о различных способах парсинга данных в Reddit.
Различные способы парсинга Reddit
Многие пользователи извлекают данные из Reddit множеством способ. У каждого из этих способов есть свои плюсы и минусы.
Некоторые из них просты, словно прогулка по парку, и не требуют никаких технических навыков, в то время как другие сложны и требуют средних или высоких знаний в области программирования.
Давайте вкратце познакомим вас с каждым из способов получения данных с Reddit.
Парсинг Reddit вручную
Это, пожалуй, самый простой и понятный подход к поиску информации на Reddit или любой другой платформе. Он не требует никакого опыта, только умение копировать и вставлять данные в таблицу.
Например фотографии и аватарку профиля, можно легко загрузить с платформы, а видео - с помощью сторонних сайтов для загрузки видео.
Кроме того, вы сможете проверить каждую точку в информации и убедиться, что в таблицу попали только правильные и актуальные данные.
Однако, поскольку весь процесс выполняется вручную, он займет у вас много времени. Кроме того, при ручном парсинге Reddit возрастает вероятность ошибиться и собрать ненужную информацию.
Парсинг Reddit, используя его API
Reddit предоставляет свой API, чтобы разработчики могли создавать приложения и другие продукты на основе платформы. Вы также можете использовать этот API для извлечения данных с сайта Reddit. Но для этого вы должны обладать умеренными навыками кодирования.
Есть и другие ограничительные правила, установленные Reddit, которые необходимо соблюдать, чтобы использовать API. Вдобавок ко всему, после "Споров на Reddit в 2023" API стал платным и остается бесплатным только для разработчиков инструментов модерации или в академических целях.
Создание собственного парсера для Reddit
Следующий вариант - парсить Reddit без API, создав собственный парсер с нуля. Этот способ непрост, так как требует продвинутых навыков программирования, но он весьма перспективен, если вам все же удастся это сделать.
Этот метод позволяет настроить парсер для извлечения любых типов данных, которые не могут извлечь другие готовые парсеры. Более того, вы можете написать скрипты для масштабирования задач в соответствии с вашими потребностями.
Однако разработка собственного парсера - непростая задача, требующая больших затрат и денег и времени.
Использование парсера Reddit без применения кодинга
Не умеете программировать? Не беда. Существует множество инструментов для кликов и парсинга, которые не требуют навыков программирования.
Эти инструменты поставляются в виде удобных программ или расширений для браузеров и позволяют получить данные с Reddit в течение нескольких минут, сделав всего несколько кликов мышью.
Хорошая новость заключается в том, что большинство из этих инструментов имеют бесплатный тариф, которого часто хватает большинству пользователей.
Как спарсить данные с Reddit с помощью кода и без него?
А теперь, без лишних слов, давайте приступим к делу и узнаем, как парсить Reddit с помощью специального парсера без навыков программирования и библиотеки Python.
Спарсите Reddit с помощью Parsehub (без использования кода)
Ручной сбор данных с Reddit может занять целую вечность. Хотя найти посты, открыть их, подождать, пока они загрузятся, а затем вручную скопировать и вставить данные в электронную таблицу вполне возможно, это все равно непродуктивно, особенно если речь идет о сотнях постов.
Позвольте автоматическим парсерам сделать работу за вас. Эти инструменты позволяют автоматически собирать практически все типы данных, включая юзернеймы, ссылки, названия постов, даты, изображения, комментарии и т. Д.
К числу популярных инструментов для парсинга Reddit, без применения кода, относятся ParseHub, Apify и Octoparse.
Как уже говорилось ранее, парсинг Reddit с помощью готового инструмента, - проще простого, но для начала вам нужно изучить некоторые рекомендации.
Итак, теперь давайте узнаем, как парсить Reddit с помощью ParseHub.
-
Скачайте ParseHub: Перейдите на официальный сайт ParseHub и выберите подходящий вариант загрузки для вашей операционной системы. Будет загружена установка. Запустите ее, и через несколько минут ParseHub будет установлен.
-
Создайте аккаунт: Если вы используете ParseHub впервые, вам придется зарегистрироваться и создать учетную запись. Этот процесс очень быстрый. Просто введите свое имя, электронную почту и пароль, и вы войдете в систему.
-
Создайте новый проект: На главном экране нажмите кнопку Новый проект.
-
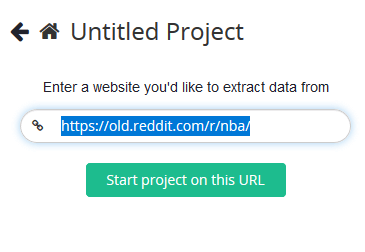
На новом экране вставьте ссылку на сабреддит, который вы хотите спарсить. Мы рекомендуем вам использовать старую версию Reddit, так как она лучше всего подходит для целей парсинга.
-
Для демонстрации мы будем использовать сабреддит NBA.
-
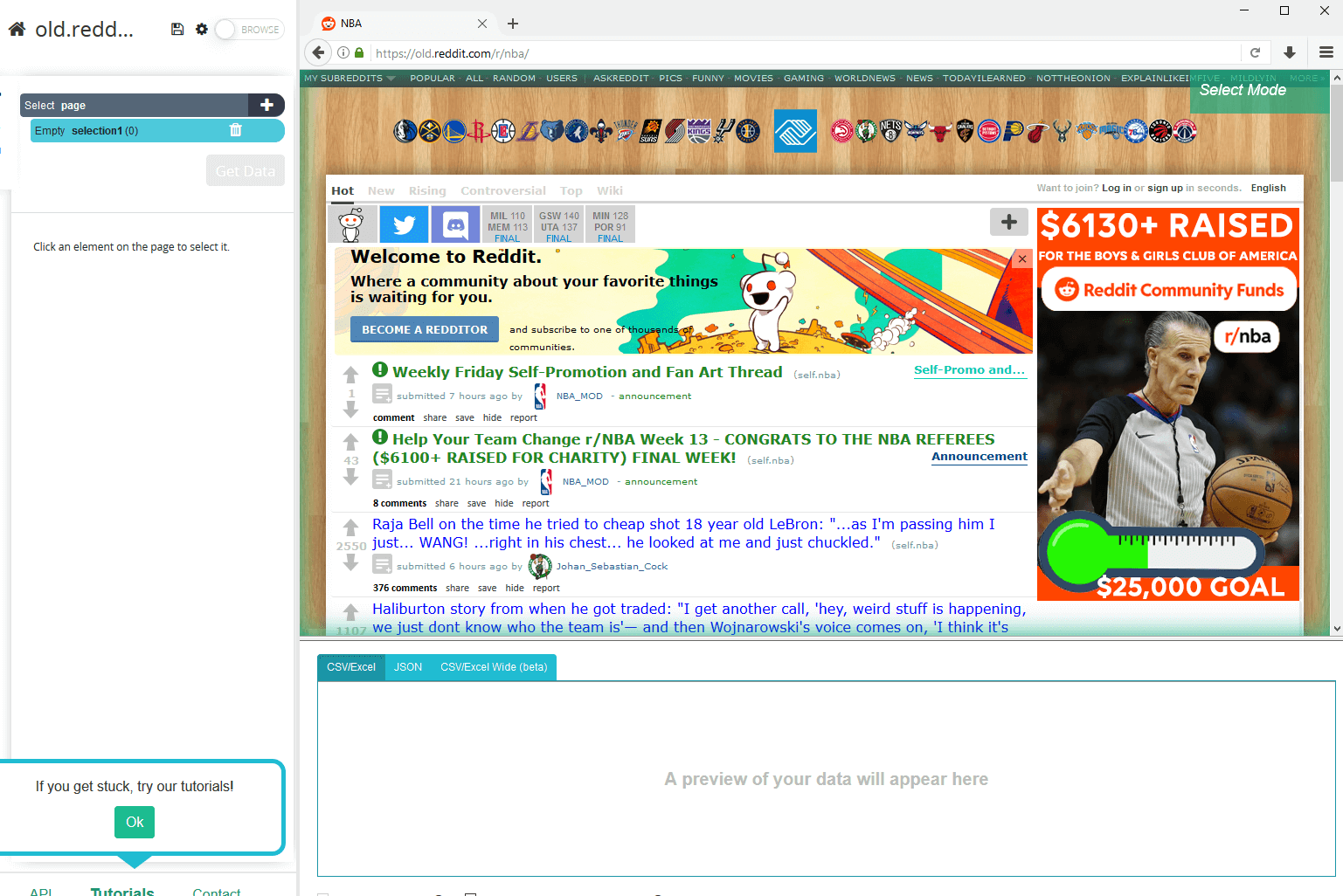
Нажмите кнопку "Пуск", и сабреддит загрузится на главный экран.
-
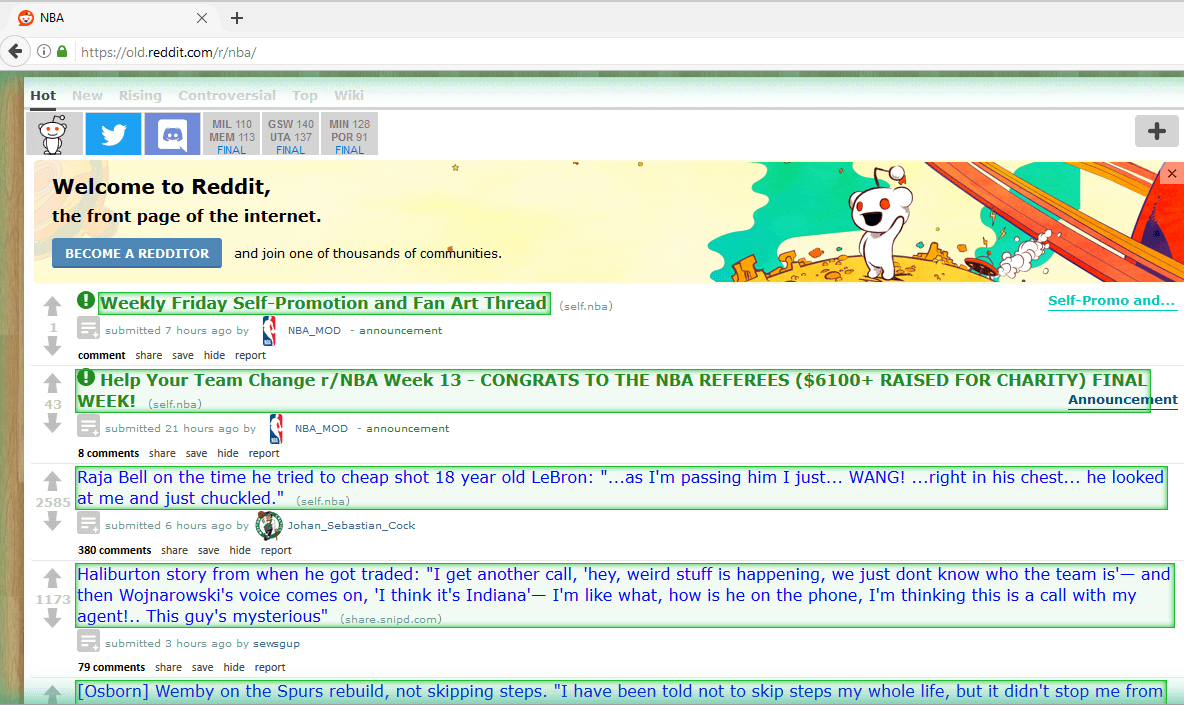
Выберите релевантные данные: допустим, мы хотим извлечь заголовки и ссылки всех постов. Кликните по заголовку первого сообщения на странице. Выбранный заголовок станет зеленым, а заголовки других постов - желтыми. Теперь выберите заголовок второго поста, и все заголовки станут зелеными, указывая на то, что все они были выбраны.
-
На боковой панели дайте подборке соответствующее название, например "Посты".
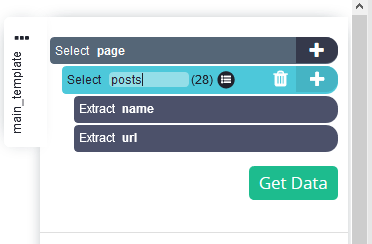
-
Сделайте дополнительные выборки: предположим, нам также нужна дата каждого сообщения. Для этого нажмите на символ "+" в области выбора постов и выберите Relative Select.
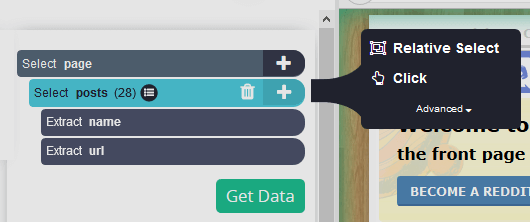
-
Теперь нажмите на заголовок первого сообщения, а затем кликните на временную метку сообщения. Вся страница станет выглядеть следующим образом.
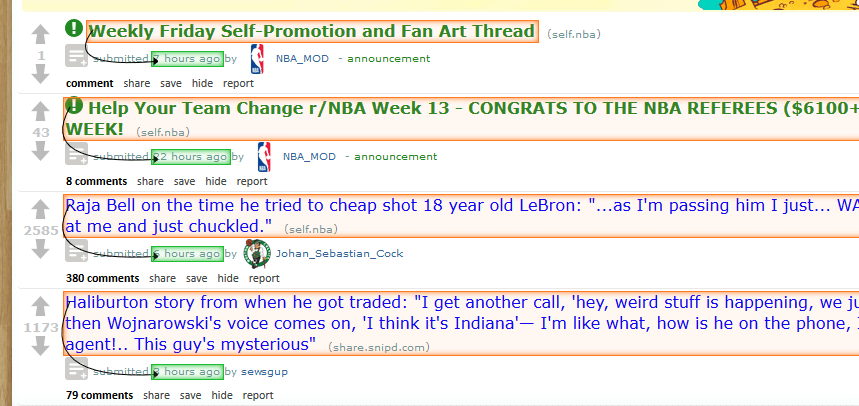
-
Переименуйте только что созданную подборку в дату.
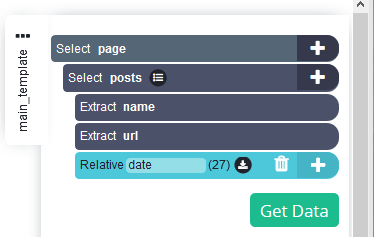
-
При выборе даты извлекается соответствующая временная метка, но нам нужны дата и время сообщения. Поэтому нажмите символ "+" рядом с выбором даты, нажмите кнопку Дополнительно, чтобы открыть полное меню, и выберите Извлечь.
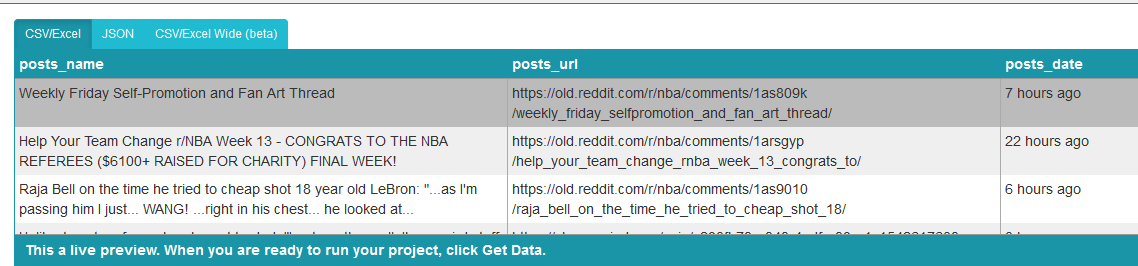
-
Откройте выпадающий список рядом с Extract и выберите "title Attribute".
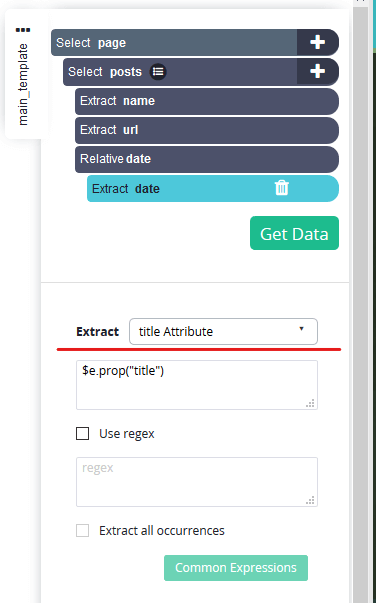
-
Вы заметите, что теперь при выборе выбираются даты и время.

-
Повторите для других типов данных: повторите предыдущий шаг для никнеймов пользователей, количества комментариев и количества поднятых голосов.
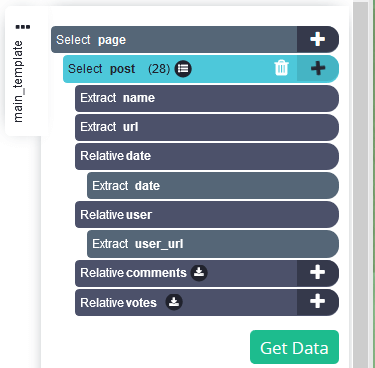
-
Добавьте пагинацию: выбранные, до сих пор, страницы извлекают данные только с первой страницы. Чтобы перейти к следующим страницам, нажмите на символ "+" выделения страницы и нажмите Выбрать.
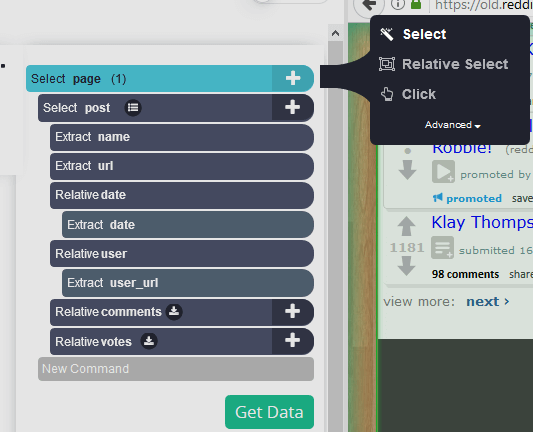
-
Прокрутите страницу до самого низа и нажмите кнопку "Далее".
-
Нажмите на символ "+" на следующем выделении и выберите “Кликнуть”.

-
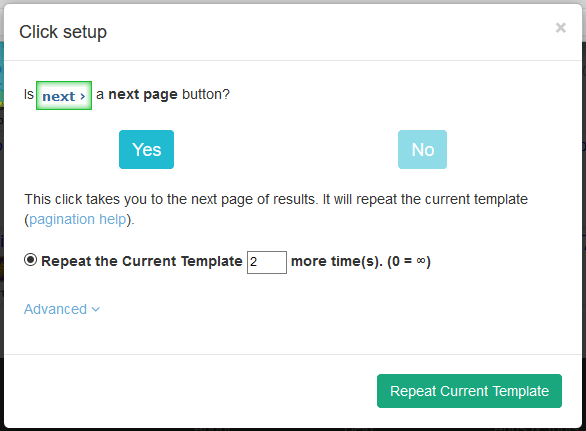
Появится всплывающее окно с вопросом, является ли эта кнопка следующей страницей. Выберите “Да” и введите количество страниц, на которых она должна быть нажата. Мы ввели 2, поэтому в общей сложности мы спарсим 3 страницы. Теперь нажмите кнопку Repeat Current Template (Повторить текущий шаблон).
-
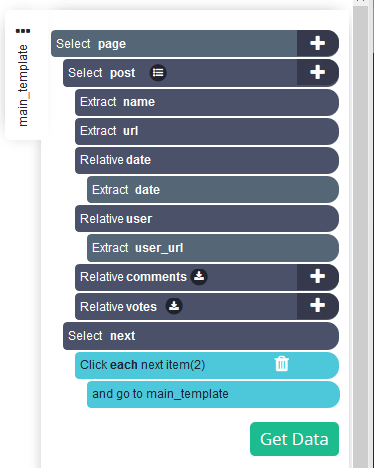
Проект готов.
-
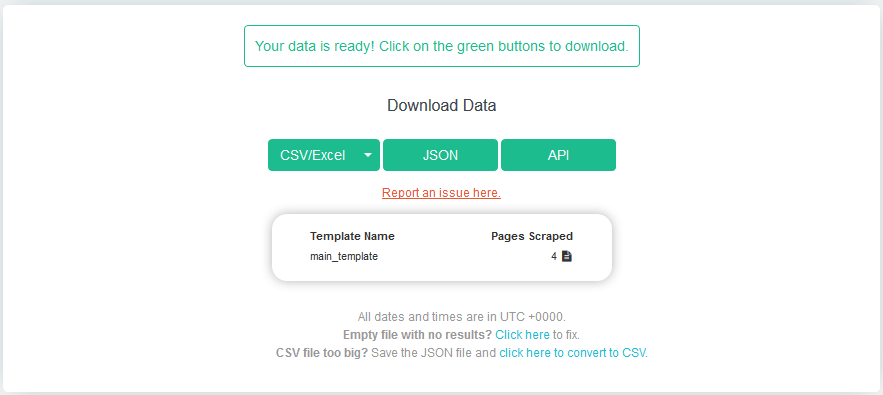
Запустите проект: нажмите кнопку “Получить данные”.

-
Выберите "Выполнить". Через несколько минут данные будут готовы. Выберите нужный формат сохранения файла.
Парсинг Reddit с помощью Python (кодинг)
Зная, как парсить Reddit с помощью готового инструмента, не требующего знания кода, вы удивитесь, почему люди все же прибегают к написанию скриптов для решения той же задачи.
Ответ заключается в свободе, которую дает этот метод.
Используя готовый парсер, вы можете собрать только те типы данных, которые он позволяет собрать. Могут быть и другие ограничения, например лимиты страниц или постов.
Возможно, вы сможете обойти эти ограничения, перейдя на премиум тариф. Но это может ударить по вашему кошельку, и, кроме того, если ваши требования к парсингу высоки, готовые парсеры для Reddit не смогут помочь.
Именно тогда вам придется прибегнуть к помощи Python или других языков программирования, чтобы спарсить Reddit.
Парсинг в Reddit с помощью Python позволит вам не только извлекать любые данные и любое количество страниц, но и делать это, не заплатив ни копейки. Но это только в том случае, если вы сами разбираетесь в программировании. В противном случае вам придется нанять специалиста.
Итак, давайте посмотрим, как парсить Reddit с помощью Python:
-
Установите необходимые библиотеки: убедитесь, что вы установили необходимые библиотеки, PRAW (Python Reddit API Wrapper) и Pandas.
-
Создайте приложение Reddit: перейдите на сайт Reddit и создайте новое приложение. Получите идентификатор клиента, секрет клиента, имя пользователя и пароль.
-
Пройдите аутентификацию: используйте полученные данные аккаунта для аутентификации в API Reddit с помощью PRAW.
-
Выберите Subreddit: укажите субреддит, который вы хотите парсить.
-
Парсинг данных: используйте PRAW для получения постов из выбранного сабреддита, т. е. укажите количество постов и желаемые атрибуты.
-
Сохранить данные: сохраните собранные данные в подходящем формате, например в DataFrame, используя Pandas.
-
Анализируйте или визуализируйте: анализируйте или визуализируйте полученные данные так, как это необходимо для вашего проекта или анализа.
Для более глубокого понимания и получения фрагментов кода для каждого шага перейдите на эту подробную инструкцию.
Обезопасьте свой парсинг от блокировки
Согласно пользовательскому соглашению Reddit, доступ к сайту с помощью автоматизации и парсинга данных без предварительного согласия запрещены.
Однако информации о превентивных мерах Reddit против парсинга, таких как запрет для посещения с конкретных IP-адресов или банов аккаунтов, не так много.
Это может свидетельствовать о “понимающем” отношении Reddit к парсингу. Но все же есть вероятность, что ваш парсер может столкнуться с такими препятствиями, как CAPTCHA, ограничения скорости или приостановка работы.
Именно для этого создан антидетект браузер AdsPower. AdsPower делает ваши парсери похожими на реальных пользователей благодаря умным методам защиты отпечатков браузера, чтобы вы могли беспрепятственно собирать данные.
Теперь, когда вы знаете, как парсить Reddit с помощью кодинга и готового инструмента, зарегистрируйтесь на сайте AdsPower и парсите полезные сабреддиты без ограничений.

Люди также читают
- Популярные хештеги для Тик Тока для рекомендации: какие работают в 2025 году
- DeepSeek нейросеть на русском: что такое DeepSeek и как им пользоваться
- Как заработать с помощью ChatGPT: 100 000 ₽ за неделю и полезные советы
- Что такое нейросеть и как заработать на нейросетях в 2025 году
- Как заработать на Spotify? Вот как люди получают прибыль
