
5種有效避免被屏蔽的網頁抓取方法

你知道嗎? 大約47%的網路流量是由機器人(包括網路爬蟲)產生的。在資料至上的數位化世界裡,網路爬蟲獲取資訊已成為許多企業的必需手段。
然而,儘管這一過程至關重要,但它也面臨著許多挑戰,例如阻止自動存取的驗證碼,以及引誘和暴露機器人的蜜罐陷阱。
但我們的主要關注點並非這些障礙。我們旨在探索有效的解決方案來繞過它們,從而實現流暢的網頁抓取,避免被封鎖。
本文概述了五種成功進行網頁抓取而不被屏蔽的方法。從使用功能強大的反偵測瀏覽器到在訪問量較低的時段安排抓取任務,我們涵蓋了一系列技巧。
透過部署這些方法,不僅可以降低被封鎖的幾率,還可以提高網路爬蟲活動的效率和規模。
讓我們深入了解一下,幫助您順利收集重要數據。
網路爬蟲面臨的挑戰
資料抓取面臨的風險和挑戰多種多樣,從技術障礙到網站故意設置的陷阱,不一而足。了解這些挑戰是製定穩健的網頁抓取策略的關鍵一步。
下面,我們將重點介紹網路爬蟲面臨的一些最常見的挑戰。
5種不被屏蔽的網頁抓取方法

網路爬蟲面臨諸多挑戰,但每種挑戰都有相對應的解決方案。讓我們一起來探索這些技巧,了解它們如何幫助我們順利進行網路爬蟲,避免被封鎖。
無頭瀏覽器
一種避免被網站屏蔽的網頁抓取方法是使用無頭網頁抓取技術。這種方法需要使用無頭瀏覽器-一種沒有圖形使用者介面(GUI)的瀏覽器。無頭瀏覽器可以模擬一般使用者的瀏覽活動,幫助你避開那些使用 JavaScript 來追蹤和封鎖網頁抓取工具的網站。
當目標網站載入了 Javascript 元素時,這些瀏覽器尤其有用,因為傳統的 HTML 抓取工具缺乏像真實使用者一樣渲染這類網站的能力。
主流瀏覽器如Chrome和Firefox都支援無頭模式,但你仍然需要調整它們的行為以使其看起來更像真實瀏覽器。此外,你還可以將無頭瀏覽器與代理結合使用,以隱藏你的IP位址並防止被封鎖,從而增加一層額外的保護。
你可以透過 Puppeteer 以程式方式控制無頭 Chrome,它提供了一個進階 API 來瀏覽網站並對其執行幾乎任何操作。
例如,這裡有一個簡單的 Puppeteer 腳本,用於建立一個瀏覽器實例,截取網頁的螢幕截圖,然後關閉該實例。
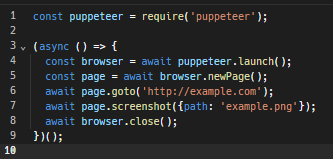
以下是使用 Puppeteer 實作無頭瀏覽的詳細教學。
在非尖峰時段進行刮除作業
網頁抓取是指以極快的速度瀏覽網站,這種行為在一般使用者中並不常見。這會導致伺服器負載過高,並影響其他使用者的存取速度。因此,網站管理員可能會注意到網頁抓取程序,並將其從伺服器中移除。
因此,避免被網站封鎖的明智之舉是在網站的非尖峰時段進行網頁抓取。此時網站通常監管較為鬆懈。即使你的爬蟲活動消耗了大量伺服器資源,也未必會耗盡伺服器資源,引起管理員的注意。
然而,仍然有被發現的風險。一些網站可能採取了複雜的措施來監控用戶活動,即使在訪問量較低的時段也是如此。此外,如果資訊不夠及時,確定網站的非尖峰時段也可能很棘手。
使用反檢測瀏覽器
反偵測瀏覽器是一種綜合工具,旨在保護使用者匿名性,並隱藏使用者在所造訪網站上的線上活動。它的工作原理是掩蓋或更改用戶瀏覽器的數位指紋,該數位指紋通常包含瀏覽器類型、插件、螢幕解析度和時區等訊息,網站會利用這些資訊來追蹤用戶活動。
這使得防偵測瀏覽器成為網頁抓取而不被封鎖的理想選擇。然而,需要注意的是,這些瀏覽器只能降低被偵測到的風險;它們並非對所有網站都完全有效。因此,選擇一款最適合網頁抓取的防偵測瀏覽器是最大限度降低被偵測到幾率的關鍵。
AdsPower是一款優秀的網頁抓取反偵測瀏覽器。它使用特定的技術來規避反抓取措施,例如:
除了這些功能外,AdsPower 還提供抓取自動化和多瀏覽器設定檔等額外優勢,以加快抓取過程。
自動解決驗證碼或使用付費服務
為了在網頁抓取過程中繞過驗證碼而不被封禁,您有幾個選擇。首先,考慮是否可以在不訪問受驗證碼保護的區域的情況下獲取所需信息,因為直接編寫解決方案難度較高。
但是,如果存取這些部分至關重要,您可以使用驗證碼破解服務。這些服務,例如2Captcha和 AntiCaptcha,會僱用真人來破解驗證碼,並按破解次數收費。但請記住,完全依賴這些服務可能會讓您花費不少錢。
此外,像 ZenRows 的 D 和 Oxylabs 的資料爬蟲工具這樣的專用網路爬蟲工具可以自動繞過驗證碼。這些工具使用先進的機器學習演算法來解決驗證碼,以確保您的爬蟲活動順利進行。
蜜罐陷阱
為了在進行網路爬蟲操作時有效應對蜜罐陷阱而不被屏蔽,關鍵在於識別並避開它們。蜜罐陷阱是一種旨在引誘和識別機器人的機制,通常以隱藏在網站 HTML 程式碼中的不可見連結形式出現,這些連結對使用者不可見,但網路爬蟲可以檢測到。
一種策略是編寫程序,讓你的爬蟲或抓取工具識別那些透過 CSS 屬性對使用者不可見的連結。例如,避免追蹤與背景顏色融為一體的文字鏈接,因為這是一種故意隱藏連結的策略。
這是一個用於檢測此類隱藏連結的基本 JavaScript 函數。
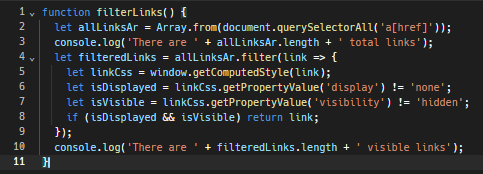
此外,遵守網站的 robots.txt 檔案至關重要。該文件專為機器人設計,列出了抓取網站的規則和禁忌。它提供了有關網站哪些區域禁止抓取以及哪些區域允許抓取的資訊。遵循這些規則是一種良好的實踐,可以幫助您避免落入陷阱。
總結完畢!
當然,反爬蟲措施會阻止我們訪問目標網站上的寶貴數據,有時甚至會導致我們被永久封鎖。但這些挑戰並非無法克服。
你可以使用無頭瀏覽器之類的工具來模擬真實瀏覽行為,在訪問量較低的時段進行資料抓取以避免被偵測到,並使用 AdsPower 等反偵測瀏覽器來隱藏你的活動痕跡。此外,還有一些方法可以繞過驗證碼和躲避蜜罐陷阱。
有了這些策略,就能輕鬆實現不被封鎖的網頁抓取。所以,讓我們告別碰運氣式的方法,開始用更聰明的方式抓取網頁吧。

人們也讀過
- 2026 年最適合在學校和工作場所使用的音樂網站(已解除封鎖)

2026 年最適合在學校和工作場所使用的音樂網站(已解除封鎖)
發現適合學校和工作場所的、未被封鎖的最佳音樂網站。
- 初學者的最佳Reddit被動收入點子(2026指南)

初學者的最佳Reddit被動收入點子(2026指南)
想找被動收入來源?了解Reddit用戶在2026年賺錢的5種行之有效的方法。
- 如何匿名查看 Instagram 快拍? 2026 年完整指南

如何匿名查看 Instagram 快拍? 2026 年完整指南
了解如何在 2026 年匿名查看 Instagram 快拍,並找到最符合您的隱私和瀏覽需求的方法。
- 您可以擁有多個 Polymarket 帳戶嗎?規則、風險與最佳實務 (2026)

您可以擁有多個 Polymarket 帳戶嗎?規則、風險與最佳實務 (2026)
本指南解釋了 Polymarket 關於多重帳戶的規則、潛在風險以及安全高效管理多個帳戶的最佳實踐。
- 學校未封鎖的12款熱門遊戲(附簡易解決方法)

學校未封鎖的12款熱門遊戲(附簡易解決方法)
發現 12 款適合學生免費暢玩的無限遊戲,學習存取被封鎖遊戲網站的實用方法

