
6 個實現無縫電子商務網頁抓取的技巧
電子商務網頁抓取是企業獲取市場洞察、提升績效的有效工具。然而,這種工具也面臨許多挑戰。這些挑戰會擾亂抓取過程,阻礙資料順利收集。
此外,一些網站還採取了措施來防止資料被抓取,這無疑增加了任務的複雜性。在當今數據驅動的世界裡,了解如何克服這些障礙是保持競爭力和獲利能力的關鍵。
這篇部落格文章提供了五個確保電商網站資料抓取順利進行的關鍵技巧。這些策略將幫助您克服常見的抓取難題,並有效率地收集所需資料。
所以請繼續閱讀,學習如何像專業人士一樣在電子商務領域進行網路爬蟲。但在深入了解技巧之前,讓我們先快速了解網路爬蟲對電子商務的重要性。
電子商務在網路爬蟲產業中佔最大份額!
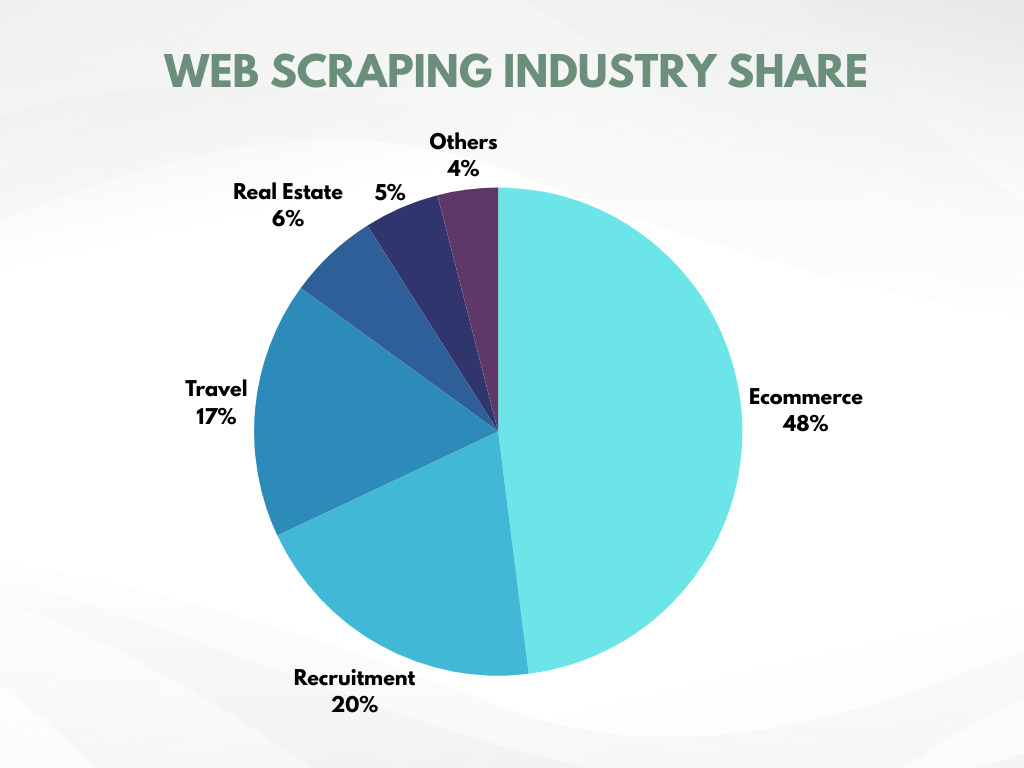
最近的一項研究表明,電子商務產業承擔了所有網路爬蟲活動的48%。光是這一點就足以說明網路爬蟲在資料收集中扮演著多麼重要的角色。
進一步的研究表明,採用數據驅動策略的企業績效優於競爭對手。這些企業高度依賴網路爬蟲技術,因為它是唯一能夠以最小的努力快速自動地從網路上收集大量資料的方法。
5 個讓電商網站抓取更輕鬆的技巧 + 額外提示
上次,我們指導了您如何抓取電商網站的資料。但在您開始抓取電商網站資料之前,遵循一些技巧至關重要,這樣才能最大限度地提高抓取效率並獲得最佳結果。

採用地理定位
如果您想要獲得針對不同地區的精準資料洞察,地理定位應該是您的首選策略。地理定位不僅能幫助您根據特定地區客戶的需求開發產品,還能幫助您:
- 識別市場機會
- 學習競賽
- 制定有針對性的行銷或定價策略
但是,重複抓取大量資料會帶來挑戰。這種行為可能會將電商網站抓取工具標記為機器人,並可能導致您的帳戶被封鎖。許多網站會限制用戶在其地理位置範圍內訪問,任何來自外部的IP位址都會被偵測並封鎖。
解決這個問題最簡單的方法是IP輪替。網路爬蟲可以隱藏其IP位址,使其看起來像是使用代理的真實用戶從不同位置訪問網站。這種方法還可以掩蓋爬蟲的機器人行為,防止其被屏蔽。
但如果您要造訪的網站採用了進階反爬蟲措施,則必須使用住宅IP位址。這些IP位址由目標地區的網路服務供應商提供,更不容易被偵測到。在這種情況下,不建議使用免費代理,因為網站通常會列出已知的免費IP位址並主動封鎖它們。
降低刮擦速度
網站通常會限制使用者在特定時間內可以發出的請求數量,這給電子商務網頁抓取帶來了挑戰,因為抓取工具通常會在短時間內發送大量請求。這種極高的請求頻率與人類的瀏覽速度相比很不自然,可能會導致伺服器將抓取工具識別為機器人並封鎖其IP位址。
避免被偵測和屏蔽的關鍵在於減慢抓取速度。透過在請求之間隨機插入停頓或新增等待指令,抓取程式可以更逼真地模擬人類的瀏覽模式。這種方法降低了觸發網站反機器人系統的風險,並允許在不被封鎖的情況下進行電商抓取。
躲避驗證碼
網站通常會針對其認為可疑的使用者活動產生驗證碼。這會阻止電子商務網站的抓取活動,因為抓取工具通常缺乏解決驗證碼的機制,而且自動解決驗證碼也並非易事。
一個可能的解決方案是使用驗證碼破解服務,這些服務僱用真人付費破解驗證碼。然而,完全依賴這些服務可能會造成經濟負擔。此外,還有一些工具可以自動破解驗證碼,但這些工具可能存在可靠性問題,尤其是在網站不斷更新驗證碼機制使其變得更加複雜的情況下。
面對這種情況,最有效的解決方案是找出觸發驗證碼產生的根本原因。關鍵在於配置網路爬蟲,使其能夠模擬真實使用者的行為。這包括採取一些策略來避免隱藏陷阱、使用代理、輪換 IP 位址和請求頭,以及清除自動化痕跡等等。
避免使用反機器人系統
網站使用 HTTP 標頭資訊創建用戶指紋,這有助於識別和監控用戶,並將機器人與人類用戶區分開來。
此標頭包含一個使用者代理字串,網站會在您連接到其伺服器時收集此字串。該字串通常包含有關您正在使用的瀏覽器和裝置的詳細資訊。對於普通用戶而言,這不成問題,因為他們通常使用常見的瀏覽器、裝置和作業系統。但由於網路爬蟲通常不會透過標準瀏覽器進行抓取,因此它們的用戶代理字串會暴露其機器人身份。
解決此問題的變通方法是透過腳本手動編輯 User-Agent 字串,將常用元素替換為瀏覽器名稱、版本和作業系統。
方法如下:
但是,使用同一個用戶代理字串重複發送請求仍然可能被偵測到。因此,為了更加安全,你可以在腳本中使用不同的用戶代理字串列表,並隨機輪換使用,以避免觸發反機器人系統。
為了獲得更萬無一失的解決方案,您可以使用Selenium或Puppeteer等瀏覽器自動化工具,配合 AdsPower 等反偵測瀏覽器進行資料擷取。這些瀏覽器內建了多種防指紋辨識技術,包括遮蔽、修改和旋轉使用者指紋,從而防止指紋辨識。
注意動態網站
動態網站會根據訪客狀況改變網頁內容和版面。即使是同一訪客,動態網站也會根據以下因素,在不同的訪問中顯示不同的網頁:
- 地點
- 設定
- 時區
- 或使用者行為,例如購物習慣
相比之下,靜態網站會向所有使用者顯示相同的內容。這給電子商務網頁抓取帶來了挑戰,因為動態網站的網頁只有在瀏覽器載入後才存在。
你可以透過使用 Selenium 自動化腳本來解決這個問題,腳本會在有頭瀏覽器中載入動態網頁,然後抓取其內容。但是,由於 Selenium 不支援非同步客戶端,因此等待所有網頁在真實瀏覽器中完全載入將耗時極長。
或者,您可以使用 Puppeteer 或 Playwright,它們支援非同步網頁抓取,抓取程式可以在目前網頁載入的同時要求其他網頁。這樣,抓取程式無需等待網頁回應,速度大大提升。
額外提示 ⇒ 使用 AdsPower 進行無風險的電子商務網站抓取
雖然這些技巧在一定程度上可以幫助應對抓取電商網站資料的挑戰,但它們並非萬無一失。例如,即使降低抓取速度或在非尖峰時段抓取,也可能無法躲過那些擁有先進反抓取機制的網站的偵測。
同樣,IP 輪換和代理仍然可能使爬蟲程序容易被檢測到。
所有這些限制都凸顯了需要一個萬無一失的解決方案來確保流暢的電商網站抓取體驗。而這正是AdsPower的設計初衷。 AdsPower 擁有所有必要的技術,可將您的抓取程式偽裝成真實用戶,從而保持隱藏並避免被偵測到。
它透過掩蓋爬蟲的數位指紋來實現這一點,從而防止網站將爬蟲標記為障礙物並產生驗證碼。此外,AdsPower 結合了有頭瀏覽器和無頭瀏覽器的優勢,以應對動態網站帶來的挑戰。
除了上述功能外,AdsPower 還允許並行建立多個使用者設定文件,從而擴展資料擷取流程。它還有助於自動化電子商務網站資料抓取,以節省時間和資源。
駕馭數據的力量!
雖然電子商務網頁抓取面臨許多挑戰,例如高階反機器人系統和動態網站的複雜性,但這些障礙是可以克服的。
你可以透過一些有效技巧來提升你的電商網站抓取效率,例如地理定位、降低抓取速度、學習如何繞過反機器人系統、適應動態網站以及阻止網站產生驗證碼。為了更穩健,AdsPower 的反偵測瀏覽器是讓你的抓取程式不被網站發現的最佳平台。
所以,讓我們把這些技巧付諸實踐,充分利用數據的力量。

人們也讀過
- 無法透過 Cloudflare 驗證? 7 個解決方案(2026 年更新)

無法透過 Cloudflare 驗證? 7 個解決方案(2026 年更新)
透過逐步解決方案修復「正在驗證您是人類」錯誤,這些解決方案涉及瀏覽器設定、Cookie、JavaScript、代理程式、VPN 和瀏覽器設定檔。
- 2026 年最適合在學校和工作場所使用的音樂網站(已解除封鎖)

2026 年最適合在學校和工作場所使用的音樂網站(已解除封鎖)
發現適合學校和工作場所的、未被封鎖的最佳音樂網站。
- 初學者的最佳Reddit被動收入點子(2026指南)

初學者的最佳Reddit被動收入點子(2026指南)
想找被動收入來源?了解Reddit用戶在2026年賺錢的5種行之有效的方法。
- 如何匿名查看 Instagram 快拍? 2026 年完整指南

如何匿名查看 Instagram 快拍? 2026 年完整指南
了解如何在 2026 年匿名查看 Instagram 快拍,並找到最符合您的隱私和瀏覽需求的方法。
- 您可以擁有多個 Polymarket 帳戶嗎?規則、風險與最佳實務 (2026)

您可以擁有多個 Polymarket 帳戶嗎?規則、風險與最佳實務 (2026)
本指南解釋了 Polymarket 關於多重帳戶的規則、潛在風險以及安全高效管理多個帳戶的最佳實踐。

