
Instagram'dan Veri Toplama Nasıl Yapılır? Veri Toplama Çabalarınızdan En İyi Şekilde Yararlanmanın 3 Yolu
Üzerinde 1,3 Milyar kullanıcısı olan Instagram, işletmeler için değerli verilerin bulunduğu bir altın madeni. Pazar araştırması, potansiyel müşteri yaratma ve performans izleme için kullanılabilir. Ancak bu verileri elde etmek için Instagram'ı taramak, zorlu kısımdır.
İşlem basit değildir ve Instagram politikaları veya teknik belirsizlikler nedeniyle çok karmaşıklık içermektedir.
Bu kılavuz, düşük ve yoğun kodlu yöntemler ve kodsuz bir yöntem içeren üç yolu sunarak Instagram'ı nasıl tarayacağınızı yanıtlar.
Instagram Veri Toplama Yasal mı?
Instagram veri kazıma yasal mı? sorusunun cevabı aynı zamanda hem evet hem hayır nbsp;kazıdığınız veri türüne Eğer Instagram dan herkese a erişilebilen veri kazı istiyorsanız cevap evet
Ancak, Instagram'ı özel veriler için kazıyorsanız ve bu da Instagram oturumu açmayı gerektiriyorsa, bu açıkça yasaktır ve siz de Hesabınızın askıya alınmasıyla ve en kötü durumlarda yasal işlemle karşı karşıya kalabilirsiniz. Ancak, kamuya açık veriler için bile, yasal bir veri toplama yöntemi sağlamanız gerekir.
Instagram'dan yasal veriler elde etmek için Instagram tarafından sağlanan API'leri kullanabilirsiniz. Bunlara Instagram Grafik API'si ve Instagram Temel Ekran API'si dahildir.
Grafik API'si, işletme ve oluşturucu hesaplarıyla ilgili verileri yönetmenize ve çıkarmanıza olanak tanır. Temel Görüntüleme API'si ise size salt okunur erişim olanağı sunar. Temel kullanıcı bilgilerine erişim. Her iki API de Instagram'ın veri toplama politikalarına uymaktadır, bu nedenle Instagram'ın bunları kullanarak veri toplaması tamamen yasaldır.
Ancak, kamuya açık olmayan API'leri veya önceden izin almadan platforma erişen yasadışı araçları kullanırsanız ve sık gizli Kazıyıcının sıradan bir kullanıcı gibi görünmesi durumunda, bu yetkisiz kazıma kapsamına girer ve Instagram'ın Hizmet Şartları.
Bu yüzden Instagram'da veri toplamaya başlamadan önce, bir adım geri çekilip kendinizi düşünün ve "Instagram veri toplamaya izin veriyor mu?" diye düşünün. Bunu yaparken dikkatli olduğunuzdan emin olun.
Hangi Instagram Verilerini Kolayca Toplayabilirsiniz?
Instagram'dan nasıl veri kazacağınızı göstermeden önce platformdan yasal kazınabilen verileri keşfedelim. Yasal Instagram web kazıma size şu üç veri kategorisine erişim sağlayabilir:
-
Hashtag'ler: Başlıklarında belirli bir hashtag ile etiketlenmiş, en iyi performans gösteren veya en yeni fotoğrafları ve videoları alabilirsiniz.
-
Profiller: Gönderiler, medya sayısı ve takipçi/takip edilen kişi sayısı gibi profil verilerini alabilirsiniz.
-
Gönderiler: Yorum sayısı, beğeni sayısı, profil kimliği, yayınlanma tarihi ve URL gibi metriklere ulaşabilirsiniz.
Instagram'ı Taramanın 3 Yolu
Instagram'ı taramanın üç yolu var. İhtiyaçlarınıza ve kaynaklarınıza uygun olanı seçin:
Instagram API'sini Kullanarak Instagram Verilerini Kazıma
İşte Instagram'ı nasıl tarayacağınıza dair adım adım bir kılavuz, ancak önce aşağıdaki gereksinimleri karşıladığınızdan emin olun:
-
Instagram İşletmesi/İçerik Üreticisi Hesabı
-
Instagram İşletmesi/İçerik Üreticisi Hesabına Bağlı Bir Facebook Sayfası
-
Instagram Grafik API'sini kullanmak için bir Facebook Geliştirici hesabı
-
Minimum ayarlarla kayıtlı bir Facebook Uygulaması kurulumu
Bu ön koşulları tamamladığınızda, sonraki aşamalar şöyle görünür
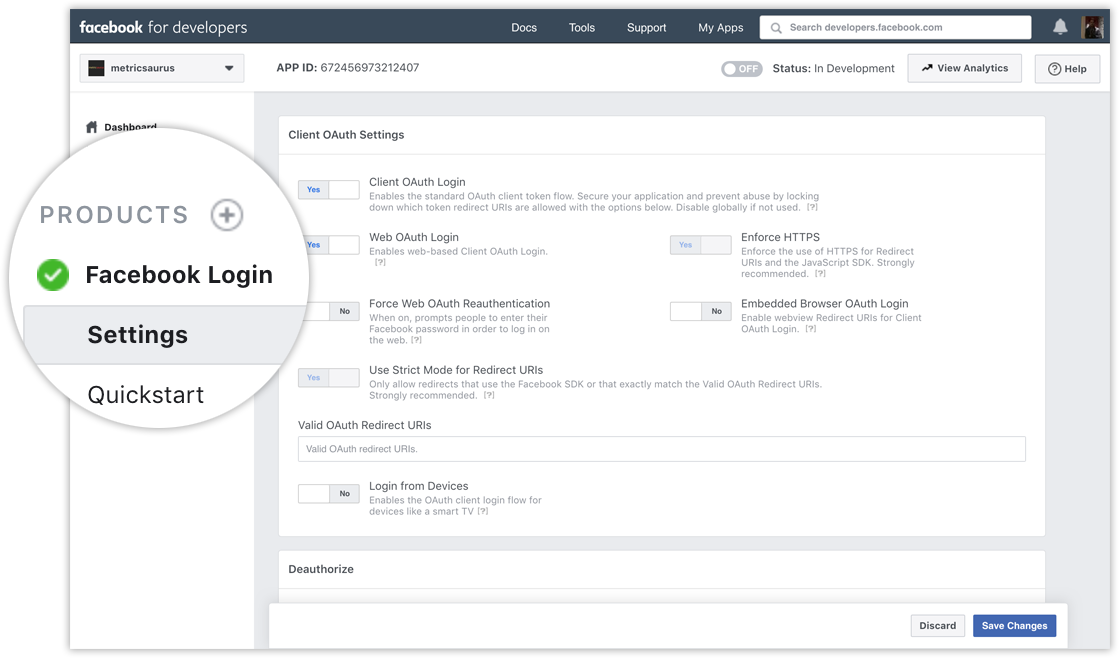
Facebook Giriş İşlevini ekleyin:
Facebook Uygulamanızın panel ine gidin ve sol tarafındaki panel Ürün +” düğmesine tıklayın ;pencere. Oradan Facebook Giriş Ürününü ekleyin. Şimdilik bu ürün için ayarları değiştirmeyin ve bunları varsayılan ayarlarında bırakın.
Sonra, uygulamanızda Facebook Girişi'ni Facebook Giriş Belgeleri ve giriş prosedürünüzün şu iki temel izni talep ettiğinden emin olun:
Erişim Jetonu Oluştur:
Instagram hesabındaki uygulama kontrol panelinden eylemler gerçekleştirmek için bir Kullanıcı Erişim Jetonu gerekir. Kontrol paneli sayfasının sağ tarafında, Kullanıcı veya Sayfa açılır menüsünü ve Kullanıcı Erişim Jetonunu Al'ı seçin.
Bir uygulamanın (bu durumda sizin uygulamanızın) yukarıda belirtilen izinleri istediğini bildiren bir açılır pencere görünecektir. Simp Devam veya Tamam düğmesine bastığınızda, kontrol panelinizdeki Erişim Jetonu alanında Kullanıcı Erişim Jetonu'nu alırsınız.
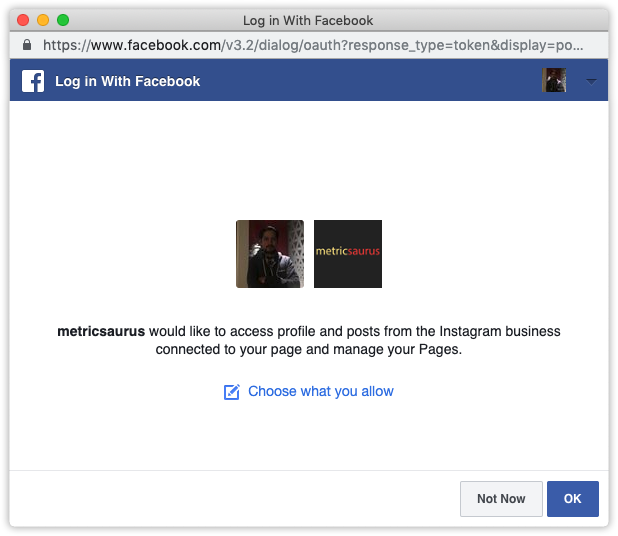
Şimdi, Kullanıcı Erişim Belirtecini kullanarak Instagram Hesabında birkaç temel sorguyu çalıştıracağız.
1. Facebook Sayfa Kimliğini Alın:
Öncelikle, Instagram İşletme hesabına bağlı Facebook Sayfası Kimliğine ihtiyacımız var. Bunun için, kontrol panelinde aşağıdaki Get sorgusunu çalıştırın.
Bu, Facebook kullanıcısına ait Facebook Sayfalarının adını ve kimliğini döndürecektir. Çıktı şuna benzeyecektir.
Instagram İşletme Hesabına bağlı sayfanın kimliğini kopyalayın.
2. Instagram İşletme Hesabı Kimliğini Alın:
Facebook kimliğini kullanarak, komut çubuğuna aşağıdaki betiği yazın ve gönder'e basın.
|
134895793791914?alanlar=instagram_iş_hesabı |
Aşağıdaki çıktıyı alacaksınız.
3. Instagram Hesabının Medya Nesnelerini Alın:
Instagram Kimliğini çıktıdan kopyalayın ve Instagram İşletme Hesabında şu anda paylaşılan tüm hikayelerin Kimliklerini almak için aşağıdaki komut dosyasını çalıştırın.
Çıktı, her hikaye için bir ID içerecektir.
Bu sadece bir örnekti. Instagram Grafik API'sini kullanarak, bir Instagram kullanıcısının meta verileri gibi diğer bilgileri de elde edebilir ve hashtag araştırması yapabilirsiniz.
Şimdi Instagram'dan veri toplamanın başka bir yoluna geçelim.
Kodsuz Bulut Kazıyıcı Kullanarak Instagram'dan Veri Kazıma
Kodlama geçmişi olmayanlar için, yukarıdaki yöntemi anlamak zor olabilir, bırakın uygulamayı. Ancak endişelenmeyin. Herhangi bir kod gerektirmeden işi yapan Instagram Kazıyıcıları var.
İşte Apify.
Apify Instagram Kazıyıcı sayfasına gidin:
Apify Instagram Kazıyıcı sayfasını açın ve Ücretsiz Deneyin düğmesine basın.

E-posta adresinizi veya Google ya da Github hesaplarınızı kullanarak Apify'a kaydolun. Bu sizi gerçek Instagram veri toplama işleminin gerçekleştiği Apify Konsoluna götürecektir.
Hedef Instagram URL'lerini Topla:
Instagram uygulamasını veya web sitesini kullanarak, toplamak istediğiniz Instagram hesaplarının tüm profil URL'lerini toplayın. Apify konsolunda, bsp;tüm bu URL'leri verilen giriş alanlarına tek seferde yapıştırın. Hepsini tek seferde girmek için Toplu Düzenle düğmesine tıklayabilirsiniz.
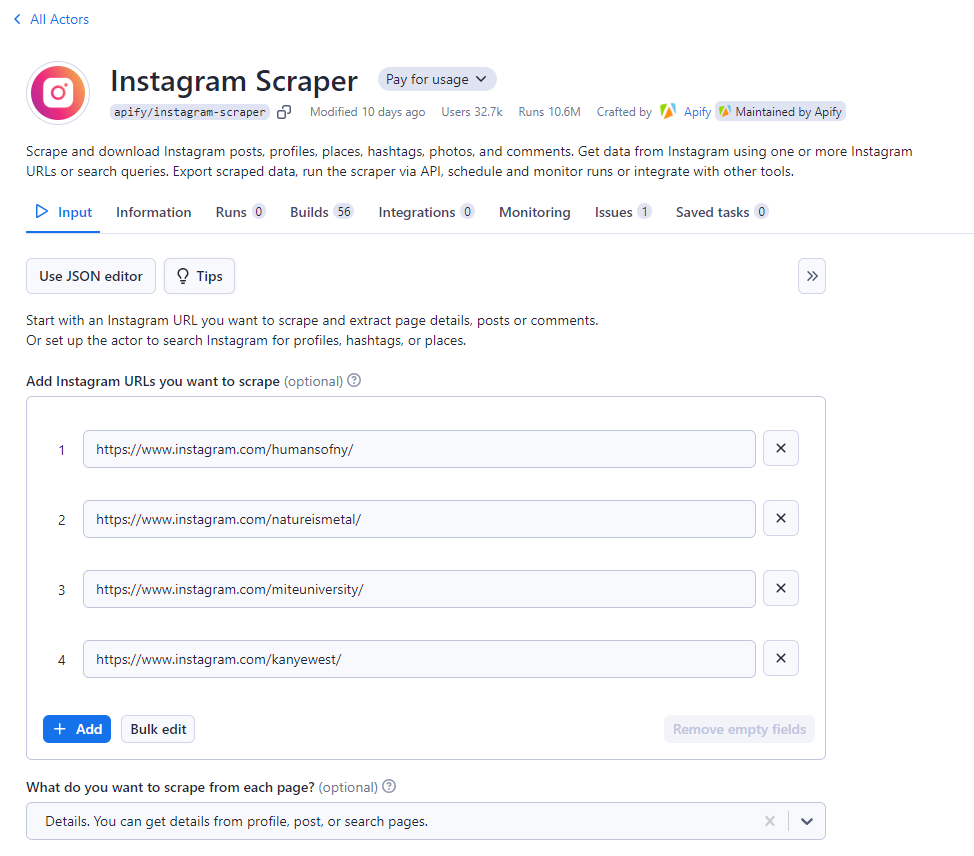
Apify, sağlanan URL'ler için üç tarama seçeneği sunar. Gönderileri, yorumları ve metinleri tarayabilir veya profillerden farklı ayrıntılar alabilirsiniz.
Kaydet'e tıklayın ve Başlayın:
Ayarların geri kalanını değiştirmeden bırakın ve kazıyıcıyı çalıştırmak için Kaydet ve Başlat'a basın. Sonuç, satır sayısına eşit satırlar içeren bir tablo biçiminde olacaktır. Birkaç tane profil URL'si sağladınız ve bu URL'lerde biyografi, takipçi sayısı, gönderi sayısı, reel sayısı, hesap kimliği ve doğrulama durumu gibi profil meta verileri içeren birkaç sütun bulunuyor. />

Sonuçları Kaydet:
Şimdi Sonuçları Dışa Dışa Düğmesine basın ve açılan pencereden istediğiniz dosya biçimini seçin Ayrıca verileri seçerek temizleye bilirsiniz veya Gereksinim duymadığınız alanları atlayarak. Bundan sonra, sonuçları indirebilir, yeni bir sekmede görüntüleyebilir veya bir bağlantı aracılığıyla paylaşabilirsiniz.

Bir Programlama Dili Kullanarak Instagram'ı Kazıma
Gereksinimleriniz alışılmadıksa ve sağlam bir programınız varsa, kendi Instagram kazıyıcınızı oluşturmak en verimli çözüm olabilir. Bilginiz varsa veya ekibinizde bir geliştirici varsa. Bunu, herhangi bir programlama dilini ve bir web kazıma çerçevesini kullanarak yapabilirsiniz.
Bu kılavuz, Instagram'ın Python ve Selenium kullanılarak nasıl taranacağını gösterir; bu da bir tarayıcı otomasyon çerçevesidir.
Temel Kitaplıkları İçe Aktar:
Başlamak için, Selenium, webdriver ve Selenium-Stealth dahil olmak üzere temel kitaplıkları içe aktarın ve algılamayı önleyin.
Pprint kütüphanesi, okunabilirliği artırmak için çıktıyı düzgün bir şekilde yazdırmamıza yardımcı olacaktır.
Instagram Kullanıcı Adlarını Topla:
Bir liste oluşturun ve hedeflediğiniz Instagram profillerinin kullanıcı adlarını ekleyin.
Çıktı değişkeni sonuçları depolamak için kullanacağımız bir sözlük
Ana fonksiyonu tanımlayın:
Ana işlev, kullanıcı adları listesini tek seferde tarayacak ve her kullanıcı adı için tarama işlevini çağıracaktır.
Tarayıcı ayarlarını yönetmek için bir işlev tanımlayın:
Bu işlev, Instagram tarafından algılanmayı önlemek için anonimlik eklemek amacıyla her veri kazıma isteğinden önce tarayıcı ayarını düzenleyecektir. Bu değişiklikler arasında, proxy'lerin döndürülmesi, Selenium-Stealth ayarlarının yapılandırılması ve yapay bir kullanıcı aracısı oluşturulması yer alıyor.
Kazıma için bir fonksiyon tanımlayın:
Ana işlevde çağrılan scrape() işlevi tek Instagram kullanıcı adını bağımsız bağımsız oluşturur prepare_browser() işlevi aracılığıyla oluşturulan Chrome tarayıcısını kullanarak bir istek göndermek için kullanacağımız profil uç noktası.
İsteğinizin durumunu da kontrol edeceğiz. İsteğiniz giriş sayfasına yönlendirildiyse, bu isteğin başarısız olduğu anlamına gelir. re giriş dizisi yoksa, istek başarılı ve sonuç JSON olarak ayrıştırılacak ve parse_data() fonksiyonuna kullanıcı adı ile gönderilecektir.
parse_data() fonksiyonunu tanımlayın:
Bu işlev, istenen veri alanını elde etmek için user_data bağımsız değişkenindeki JSON verilerini ayrıştırır. Bu örnekte, kullanıcının tam adını, hesap kategorisini, takipçi sayısını ve gönderi başlıklarını topluyoruz.
Sürücü kodunu yazın:
Sürücü kodu, veri kazıma işlemini başlatır, verileri çıktı değişkenine çıkarır ve üzerinde pprint() fonksiyonunu çağırarak verileri oldukça hoş bir şekilde görüntüler.
AdsPower Antidetect Tarayıcısı ile Algılamayı Atla
Instagram, veri toplama konusunda katıdır ve platformundaki herkese açık verilere çok sınırlı erişim sağlar. Bu, temel düzeydeki bilgileri içerir, örneğin: Profil kimliği, takipçi sayısı, beğeniler ve yorum sayısı. Bundan daha derine inmek, giriş yapmayı gerektirir ve bu da Instagram politikalarına aykırıdır ve hesabın askıya alınmasına yol açabilir. />
İşte AdsPower işte işte işte Instagram politikalarını ihlal etme olası veri kazarken düşük bir profil korumanıza yardımcı olarak iş iş AdsPower, veri kazıma önleme önlemlerinden kaçınmak için IP rotasyonu ve hız sınırlaması gibi tespit önleme tekniklerini kullanır.
Yani bir dahaki sene kodsuz bir araç veya resmi Instagram API'lerini kullanarak kazı yaptığınızda algılamayı atlatmak için AdsPower antidetect tarayıcısını kullanın.
Sonuç
Instagram, yalnızca platformunda herkese açık olarak erişilebilen verilerin taranmasına izin verir ve bunun için iki API sağlar. Ancak bsp;bu API'ler, Instagram'dan gerçekten alakalı olan verileri toplamanıza izin vermeden, çok temel bir veri toplama seviyesi sunar.
Bu durum, bizi üçüncü taraf web kazıyıcılarıyla baş başa bırakır veya programlama dillerini kullanarak kendi kazıyıcınızı yapmanıza neden olur. Ancak, Instagram'ı bizden kazımak Bu resmi olmayan yöntemleri kullanmanın tespit edilme şansı vardır, bu nedenle ek koruma için AdsPower antidetect tarayıcısını kullandığınızdan emin olun.

İnsanlar Ayrıca Okuyun
- Web Kazıma İçin En İyi 10 Başsız Tarayıcı: Artıları & Eksileri

Web Kazıma İçin En İyi 10 Başsız Tarayıcı: Artıları & Eksileri
Web kazıma için en iyi başsız tarayıcıları keşfedin. Normal tarayıcılardan farklarını öğrenin ve verimli işlemler için hafif seçenekleri inceleyin...
- Yayıncılar İçin En İyi Doğal Reklam (Native Advertising) Platformları
 Platformları")
Yayıncılar İçin En İyi Doğal Reklam (Native Advertising) Platformları
Yayıncılar için en iyi doğal reklam platformlarını keşfedin. Doğal reklamlarınızı nasıl optimize edeceğinizi ve trafiğinizi artırmak için AdsPower'ı nasıl kullanacağınızı öğrenin.
- Okul ve İş İçin Engeli Kaldırılmış En İyi Müzik Web Siteleri (2026)

Okul ve İş İçin Engeli Kaldırılmış En İyi Müzik Web Siteleri (2026)
Okul ve iş için engeli kaldırılmış en iyi müzik web sitelerini keşfedin.
- Yeni Başlayanlar İçin En İyi Reddit Pasif Gelir Fikirleri (2026 Rehberi)

Yeni Başlayanlar İçin En İyi Reddit Pasif Gelir Fikirleri (2026 Rehberi)
Pasif gelir fikirleri mi arıyorsunuz? Reddit kullanıcılarının 2026'da para kazanmasının kanıtlanmış 5 yolunu keşfedin.
- Instagram Hikayelerini Anonim Olarak Görüntüleyebilir misiniz? 2026 İçin Kapsamlı Bir Kılavuz

Instagram Hikayelerini Anonim Olarak Görüntüleyebilir misiniz? 2026 İçin Kapsamlı Bir Kılavuz
2026 yılında Instagram Hikayelerini anonim olarak nasıl görüntüleyeceğinizi öğrenin ve gizlilik ve gezinme ihtiyaçlarınız için en iyi yöntemi keşfedin.
