
Eine ausführliche Anleitung zur Verwendung von Amazon Scraper
Web Scraping bei Amazon kann für Unternehmen äußerst lukrativ sein, wenn es geschickt eingesetzt wird. Glauben Sie uns nicht? Überlegen Sie es sich.diese Geschichtevon einer Website, die innerhalb von nur zwei Monaten unglaubliche 800.000 $ einbrachte, während sie lediglich täglich Amazon-Rezensionen auswertete. Cool, oder?
Wir können Ihnen nicht versprechen, dass Sie über Nacht eine Menge Geld verdienen, aber wir können Ihnen zeigen, wie Sie Amazon auswerten, um dorthin zu gelangen.
Lesen Sie diesen Blogbeitrag, um zwei Möglichkeiten zum Scrapen von Amazon kennenzulernen: eine mit einem No-Code-Amazon-Scraper und eine andere, bei der wir einen Python-Amazon-Scraper mit Code erstellen.
Aber zuerst wollen wir herausfinden, ob das Scrapen von Amazon in Ordnung ist.
Ist Amazon-Scraping legal?
Die Regeln für Amazon-Scraping sind etwas unklar. Amazonsrobots.txtDie Datei beschreibt zulässige Scraping-Parameter in einer langen Liste, die angibt, was scrapbar ist und welche Bereiche strengstens verboten sind.
Die Datei robots.txt dient jedoch lediglich als ethische Richtlinie und ist nicht rechtsverbindlich. Ihr Amazon Scraper kann also auf gesperrte Bereiche zugreifen, ohne zwangsläufig auf Probleme zu stoßen.
Amazon hört hier jedoch nicht auf. Das Unternehmen geht noch weiter und implementiert technische Barrieren, um zu verhindern, dass Bots seine Server überlasten.
Beispielsweise werden Anti-Scraping-Maßnahmen wie CAPTCHA-Tests und Ratenbegrenzungen eingesetzt. Um diese Hindernisse zu überwinden, muss Ihr Amazon Scraper über fortgeschrittene Technikenwie User-Agent-Spoofing,CAPTCHA-Lösenoder Verzögern von Anfragen; andernfalls würde Ihr Amazon-Scraping-Vorhaben ein Traum bleiben.
Um daher kurz zu antworten:„Erlaubt Amazon Web Scraping?“: Die Rechtmäßigkeit des Web Scrapings von Amazon-Daten ist nicht eindeutig und hängt von verschiedenen Faktoren ab, darunter
-
die Art der gescrapten Daten
-
die zum Scraping verwendeten Methoden
-
und der Zweck der gescrapten Daten
Solange Scraping keinen unbefugten Zugriff, z. B. auf Daten hinter einem Login, beinhaltet oder die Infrastruktur der Site überlastet, fällt es normalerweise in die Kategorie „sicher“. Der Oberste Gerichtshof verteidigte außerdem:Ein Datenanalyseunternehmen, das von LinkedIn verklagt wurdeunter Berufung auf unerlaubtes Web-Scraping nach dem CFAA-Vertrag.
Darüber hinaus sollten Sie sicherstellen, dass die Verwendung der gescrapten Daten legal ist, d. h., Sie dürfen sie nicht weiterverkaufen oder replizieren, da dies schwerwiegende rechtliche Konsequenzen haben kann.
Nun die Millionenfrage: Wie scrapt man Amazon-Daten?
Wie scrapt man Amazon?
Trotz technischer Herausforderungen ist es einfach, Amazon zu scrapen. Es gibt viele Code- und No-Code-Tools zum Amazon-Scraping mit Lösungen zur Bewältigung der Anti-Bot-Maßnahmen von Amazon. Mit diesen Tools können Sie ganz einfach Amazon-Bewertungen, Produkte, Preise und andere Daten extrahieren.
Beginnen wir zunächst mit dem No-Code-Amazon-Scraper.
No-Code-Amazon-Scraper:
Seien wir ehrlich: Die Wahrscheinlichkeit ist hoch, dass der aktuelle Leser, der dies liest, keine Programmierkenntnisse hat. Aber das ist kein Problem. Sie brauchen keine Programmierkenntnisse, wenn No-Code-Amazon-Scraper verfügbar sind.
Mit diesen Tools geben Sie einfach die URLs der Produkt- oder Kategorieseiten ein und der Scraper ruft alle Amazon-Produktdaten von dieser Seite ab. Nach Abschluss des Web Scrapings bei Amazon stehen Ihnen außerdem mehrere Optionen zum Speichern von Dateien zur Verfügung.
Für diese Demo haben wir uns für den Amazon Scraper von Apify entschieden. Apify bietet separate Tools zum Scraping verschiedener Bereiche von Amazon, darunter Amazon Product Scraper, Amazon Review Scraper und Amazon Bestsellers Scraper.
In dieser Anleitung verwenden wir den Amazon Product Scraper von Apify. Der Amazon Product Scraper bietet Funktionen zum Lösen von CAPTCHAs und zum Setzen von Proxys, um Anti-Bot-Maßnahmen zu umgehen.
Starten wir also die Demo.
Schritt 1: Besuchen Sie die Amazon-Produkt-Scraper-Seite
Zugriff aufAmazon-Produkt-Scraper klicken Sie im Apify Store auf die Schaltfläche „Kostenlos testen“. Mit diesem Tool können Sie Amazon-Produktdaten, einschließlich Preise, Bewertungen, Produktbeschreibungen, Bilder und zahlreiche weitere Attribute, scrapen.
Schritt 2: Erstellen Sie Ihr Apify-Konto
Wenn Sie neu bei Apify sind, können Sie kostenlos ein Apify-Konto eröffnen. Die Plattform bietet Anmeldeoptionen per E-Mail, Google oder GitHub.
Schritt 3: Amazon-URLs der Zielinhalte einfügen
Geben Sie in der Apify-Konsole die URL des Amazon-Produkts oder der Kategorie ein, die Sie scrapen möchten. Wir haben Folgendes verwendet:Videospielkonsolen und Zubehörund dieMöbelKategorie in diesem Beispiel.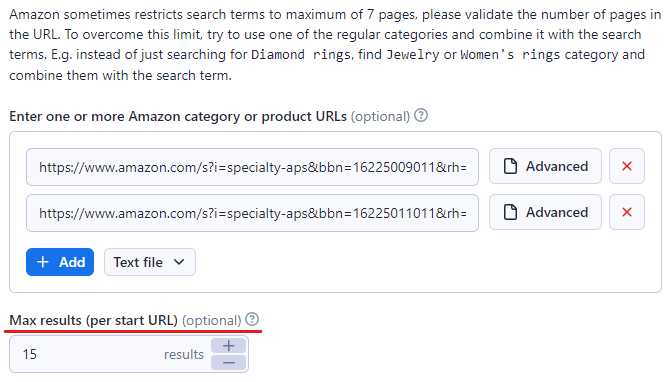
Sie können weitere Links einfügen, indem Sie auf die Schaltfläche „+ Hinzufügen“ klicken. Wenn es viele Links gibt, können Sie diese einfach alle in eine Textdatei einfügen und diese in den Amazon Scraper hochladen.
Legen Sie außerdem die maximale Anzahl der zu scrapenden Artikel fest, indem Sie im Feld „Max. Artikel“ ein Limit festlegen. Wir haben es auf 15 festgelegt, Sie können es aber beliebig hoch setzen.
Schritt 4: CAPTCHA-Solver aktivieren
Ohne CAPTCHA-Solver ist das Scraping bei Amazon nicht möglich. Amazon ist dafür bekannt, Bots sehr effizient zu erkennen. Sobald der Bot eine Aktivität vermutet, wird ihm ein CAPTCHA angezeigt.
Um sicherzustellen, dass Ihr Amazon Scraper reibungslos funktioniert, aktivieren Sie die CAPTCHA-Lösung.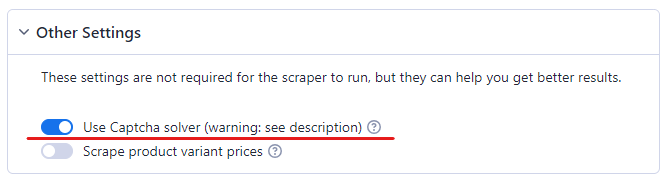
Schritt 5: Proxy konfigurieren
Die Verwendung eines Proxys ist unerlässlich, um Anti-Scraping-Maßnahmen zu umgehen. Der Amazon Scraper bietet verschiedene Proxy-Optionen, darunter Residential, Datacenter oder Ihren eigenen, um Scraping-Aktivitäten zu maskieren und Einschränkungen zu umgehen. Lesen Sie mehr über die Unterschiede zwischen Residential- und Datacenter-Proxysin unserem anderen Blog.
Die Option Residential Proxy ist standardmäßig ausgewählt, da sie für Anti-Scraping-Systeme am besten geeignet ist.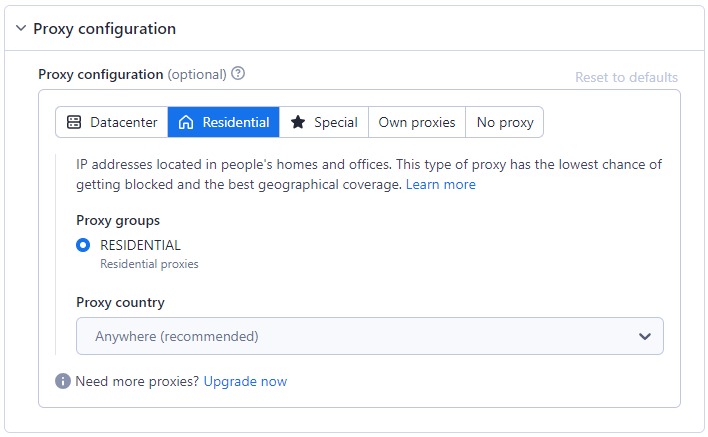
Schritt 6: Scraper starten
Nachdem Sie Ihre Parameter festgelegt haben, starten Sie den Amazon Product Scraper, indem Sie auf „Start“ klicken. Schaltfläche unten auf der Seite.
Der Status ändert sich nach Abschluss von „Läuft“ zu „Erfolgreich“.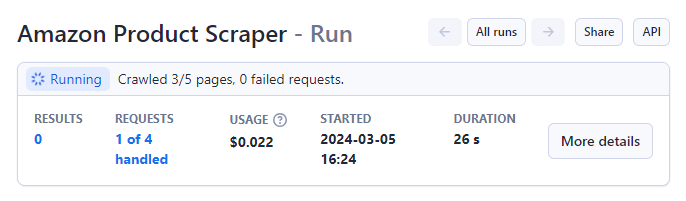
Nach Abschluss wird eine Vorschau der Daten auf Ihrem Bildschirm angezeigt.
Schritt 7: Datei exportieren
Klicken Sie auf „Ergebnisse exportieren“, um Ihre gesammelten Daten herunterzuladen. Die Plattform unterstützt verschiedene Formate, darunter CSV, JSON und Excel.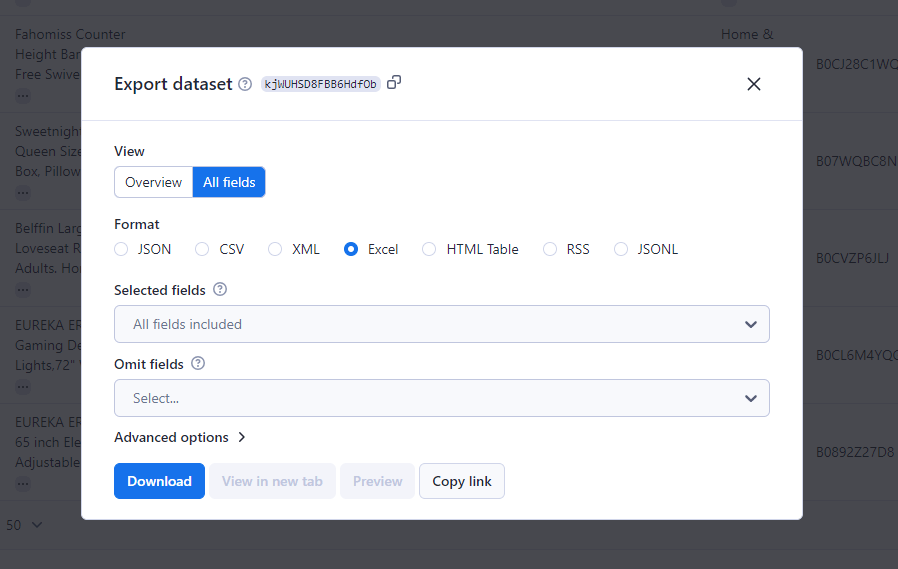
Python Amazon Scraper mit Programmierung
Wenn Sie sich den zuvor erwähnten Schritt 6 genauer ansehen, sind im oben verwendeten No-Code Amazon Scraper 69 von 173 Anfragen fehlgeschlagen. Dies liegt daran, dass Amazon diese Anfragen blockiert.
Um dieses Problem zu umgehen, müssen Sie ein eigenes Scraping-Skript programmieren. In dieser Anleitung erstellen wir einen Python-Amazon-Produkt-Scraper.
Fangen wir also an.
Schritt 1: Python installieren
Um unseren Python-Amazon-Scraper zu programmieren, muss Python auf Ihrem Computer installiert sein. Es wird empfohlen, Laden Sie die neueste Version herunteroder aktuelle Versionen, um die Kompatibilität mit den erforderlichen Bibliotheken sicherzustellen.
Schritt 2: Importieren der erforderlichen Bibliotheken
Die Kernaufgabe eines jeden Amazon Scrapers besteht im Abrufen und Parsen von Webinhalten. Hierfür verwenden wir eine Kombination aus Python-Bibliotheken.
-
Anfragen:Für HTTP-Anfragen an die Amazon-Website
-
BeautifulSoup:Zur Navigation und Analyse des zurückgegebenen HTML-Inhalts
-
lxml:zum Parsen
-
Pandas:zum Organisieren und Exportieren von Daten
Vor dem Import müssen Sie sie mit folgendem Befehl installieren:
Jetzt importieren wir sie in unser Amazon Scraper Python-Skript:
Schritt 3: HTTP-Header konfigurieren
Eine häufige Hürde beim Amazon-Web-Scraping sind Amazons Abwehrmaßnahmen gegen automatisierten Zugriff. Um dies zu vermeiden, ahmt unser Amazon-Scraper-Python-Skript die Anfrage eines Webbrowsers nach und fügt benutzerdefinierte HTTP-Header ein, wie z. B. 'User-Agent' und 'Accept-Language'.
Es empfiehlt sich, weitere Überschriften hinzuzufügen.
Um diese Header für Ihren Browser abzurufen,
-
Drücken Sie auf einer Amazon-Seite F12, um die Entwicklertools zu öffnen.
-
Öffnen Sie den Tab „Netzwerke“ und wählen Sie „Header“ aus.
-
Seite neu laden
-
Wählen Sie die erste Anfrage aus.
-
Scrollen Sie im Reiter „Header“ nach unten zum Abschnitt „Anforderungsheader“ und kopieren Sie die oben genannten Headerwerte.
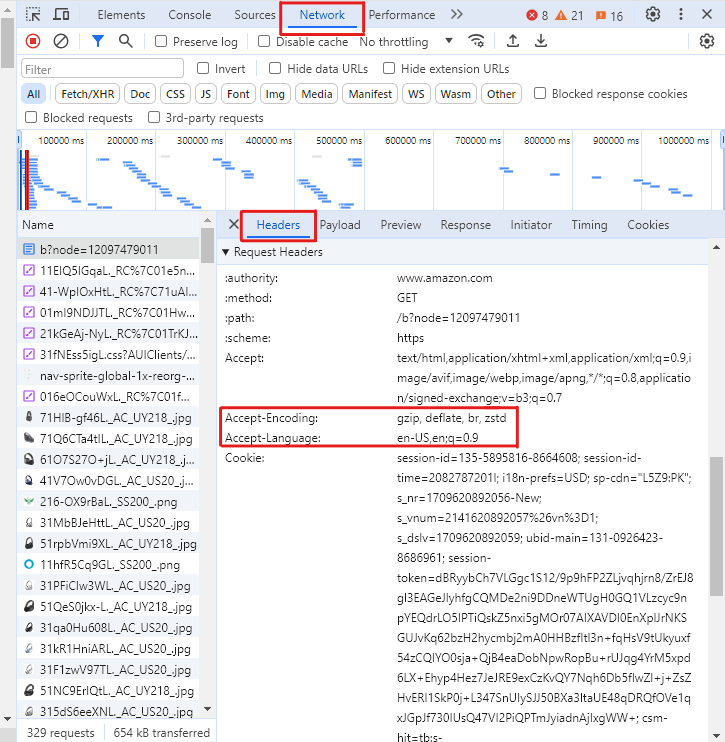
Ohne diese Header besteht eine hohe Wahrscheinlichkeit, dass Amazon die Get-Anfragen blockiert und eine Antwort wie die folgende mit dem Statuscode 503 (Fehler) statt 200 (Erfolg) zurückgibt.
Schritt 4: Produktinformationen extrahieren
Unser Amazon Product Scraper beinhaltet die Funktion:scrape_amazon_productführt die wichtige Aufgabe des Extrahierens von Produktdetails aus. Die Funktion verwendet die URL der Amazon-Kategorieseite als Eingabe und gibt ein Wörterbuch mit den Produktinformationen zurück.
Die Methode sendet dann eine Anfrage an Amazon unter Verwendung der URL und der oben erstellten benutzerdefinierten Header-Variable.
Anschließend rufen wir mithilfe der CSS-Selektoren von BeautifulSoup den Titel, den Preis, die Bild-URL und die Beschreibung des Produkts von den einzelnen Produktseiten ab.
Schritt 5: Umgang mit Produktlisten & Seitennummerierung
Damit unser Python-Skript für den Amazon-Scraper umfangreiche Daten durch Durchsuchen der Kategorieseiten und Bearbeiten der Seitennummerierung erfassen kann, navigiert das Skript durch die Produktlistenseiten von Amazon.
Es identifiziert Produktlinks mithilfe von CSS-Selektoren und verfolgt die Seitennummerierung, indem es die nächste Seite erkennt. Link.
Schritt 6: Gespeicherte Daten speichern
Abschließend werden die gescrapten Daten in einer Liste von Wörterbüchern aggregiert, die dann in einen Pandas DataFrame konvertiert wird. Dieser DataFrame wird anschließend als CSV-Datei exportiert.
Amazon Scraper heimlich nutzen
Das Scraping von Amazon ist normalerweise unkompliziert. Es können jedoch mehrere Herausforderungen auftreten, z. B. CAPTCHAs, Anfragesperren und Ratenlimits.
Um diese Probleme zu vermeiden, sollten Sie einen Browser mit Anti-Erkennungsfunktion verwenden, z. B.AdsPower. AdsPower stellt sicher, dass Ihr Amazon-Scraper unentdeckt bleibt, indem es Funktionen wie Fingerprint-Spoofing und Proxy-Rotationen anbietet.
Also Melden Sie sich jetzt kostenlos an und starten Sie nahtlos mit dem Scraping von Amazon.

Leute lesen auch
- Die 12 besten Spiele, die von der Schule nicht gesperrt werden (+ einfache Lösungen)
")
Die 12 besten Spiele, die von der Schule nicht gesperrt werden (+ einfache Lösungen)
Entdecke 12 beliebte, nicht blockierte Spiele für die Schule, lerne praktische Wege kennen, um auf gesperrte Spiele-Websites zuzugreifen, und sieh dir an, wie AdsPower dir hilft, deinen Spielebrowser zu schützen.
- Wie man im Jahr 2026 mehrere Apple-Konten sicher verwaltet

Wie man im Jahr 2026 mehrere Apple-Konten sicher verwaltet
Erfahren Sie mit praktischen Tipps, wie Sie mehrere Apple-Konten sicher verwalten.
- Wie man 2026 mit Substack Geld verdient: Umsatzstrategien für Content-Ersteller

Wie man 2026 mit Substack Geld verdient: Umsatzstrategien für Content-Ersteller
Möchtest du mit Substack Geld verdienen? Dieser Leitfaden erklärt bewährte Monetarisierungsmethoden, gibt Wachstumstipps und zeigt, wie Content-Ersteller ihre Inhalte in Einnahmen verwandeln.
- Claude nicht erreichbar oder ausgefallen? So diagnostizieren und beheben Sie häufige Probleme

Claude nicht erreichbar oder ausgefallen? So diagnostizieren und beheben Sie häufige Probleme
Ist Claude nicht erreichbar oder erhalten Sie Fehlermeldungen wie „Claude nicht erreichbar“? Erfahren Sie, wie Sie Anmeldeschleifen, Authentifizierungsfehler, Netzwerkprobleme und mehr beheben.
- Instagram gesperrt und dann verbannt? So erhalten Sie Ihr Konto zurück

Instagram gesperrt und dann verbannt? So erhalten Sie Ihr Konto zurück
Wurde Ihr Instagram-Konto gesperrt und anschließend deaktiviert? Dieser Leitfaden erklärt, was zu tun ist und wie Sie ein vorübergehend gesperrtes oder deaktiviertes Konto wiederherstellen können.
