
Comment scrapper Instagram ? 3 façons d'optimiser vos efforts de scrapping
Avec plus de 1,3 milliard d'utilisateurs, Instagram est une mine d'or de données précieuses pour les entreprises. Utilisez-les pour les études de marché, la génération de leads et le suivi des performances. Cependant, récupérer ces données sur Instagram est la partie la plus délicate.
La procédure n'est pas simple et présente de nombreuses complexités, dues soit aux politiques d'Instagram, soit à des ambiguïtés techniques.
Ce guide explique comment récupérer des données Instagram en présentant trois méthodes impliquant des méthodes à faible et à forte densité de code, ainsi qu'une méthode sans code.
Le scraping Instagram est-il légal ?
La réponse à la question « Le scraping Instagram est-il légal ? » est à la fois oui et non, car cela revient à Selon le type de données que vous récupérez. Si vous souhaitez récupérer des données Instagram accessibles au public, la réponse est oui.
Mais si vous récupérez des données Instagram privées qui nécessitent une connexion Instagram, cela est explicitement interdit et vous pouvez Votre compte ht peut être suspendu et, dans le pire des cas, faire l'objet de poursuites judiciaires. Cependant, même pour les données publiques, vous devez garantir une méthode de scraping légale.
Pour récupérer des données légales Instagram, vous pouvez utiliser les API fournies par Instagram. Celles-ci incluent l'API Instagram Graph et l'API Instagram Basic Display.
L'API Graph vous permet de gérer et d'extraire des données sur les comptes d'entreprise et de créateur. Alors que l'API d'affichage de base vous donne un accès en lecture seule Accès aux informations utilisateur de base. Ces deux API respectent la politique d'Instagram relative au scraping. Leur utilisation est donc parfaitement légale.
Cependant, si vous utilisez des API non publiques ou des moyens illicites qui accèdent à la plateforme sans autorisation préalable et souvent dissimulent Si le scraper apparaît comme un utilisateur ordinaire, cela relève alors du scraping non autorisé et viole les règles d'InstagramConditions d'utilisation.
Avant de commencer à scraper Instagram, prenez du recul et demandez-vous si « Instagram autorise le scraping » et soyez prudent.
Quelles données Instagram pouvez-vous facilement récupérer ?
Avant de vous montrer comment récupérer des données Instagram, découvrons d'abord quelles données peuvent être légalement récupérées sur la plateforme. Le scraping légal du Web Instagram peut vous donner accès à ces trois catégories de données :
-
Hashtags : vous pouvez obtenir les photos et vidéos les plus performantes ou récentes, identifiées par un hashtag spécifique dans leur légende.
-
Profils : vous pouvez obtenir des données de profil telles que les publications, le nombre de médias et le nombre d'abonnés.
-
Publications : Vous pouvez obtenir des statistiques telles que le nombre de commentaires, le nombre de mentions « J'aime », l'identifiant du profil, la date de publication et l'URL.
3 façons de scraper Instagram
Voici trois méthodes pour scraper Instagram. Choisissez celle qui correspond à vos besoins et à vos ressources :
Scraping Instagram à l'aide de l'API Instagram
Voici un guide étape par étape expliquant comment récupérer des données Instagram. Assurez-vous d'abord de remplir les conditions suivantes :
-
Un compte Instagram d'entreprise/de créateur
-
Une page Facebook liée au compte Instagram d'entreprise/de créateur
-
Un compte développeur Facebook pour utiliser l'API Instagram Graph
-
Une configuration d'application Facebook enregistrée avec les paramètres minimum
Une fois ces prérequis remplis, les étapes suivantes ressemblent à ceci :
Ajouter la fonctionnalité de connexion Facebook :
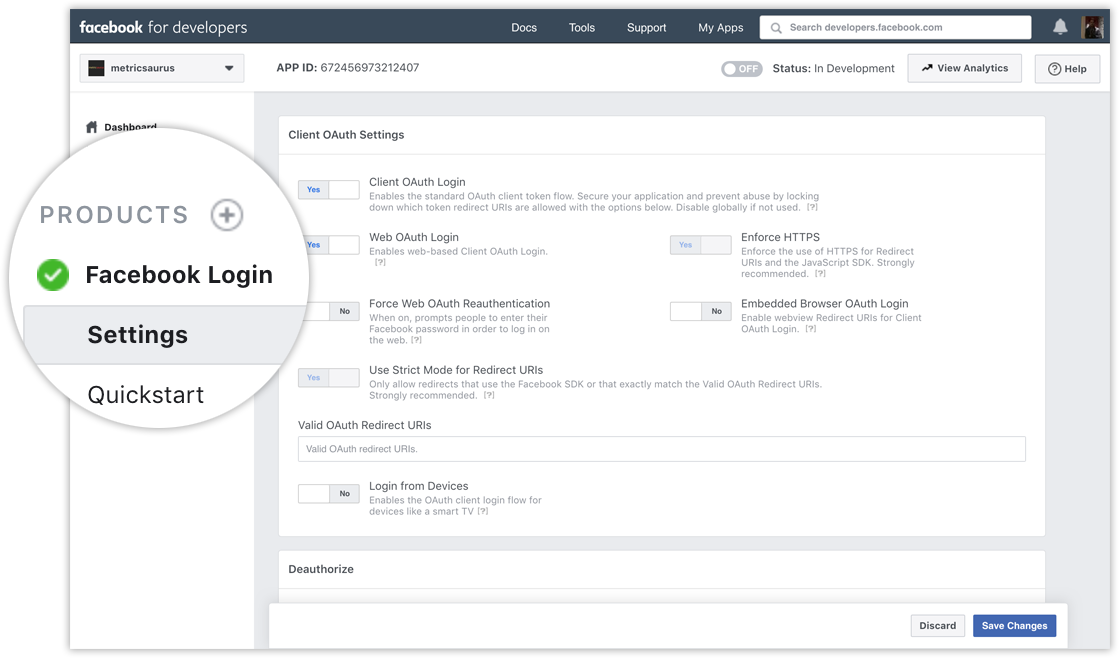
Accédez au tableau de bord de votre application Facebook et cliquez sur le bouton « Produit + » dans le panneau situé sur le côté gauche de ;la fenêtre. Depuis là, ajoutez le produit de connexion Facebook. Pour l'instant, ne modifiez pas les paramètres de ce produit et laissez-les par défaut.
Ensuite, vous devrez implémenter la connexion Facebook dans votre application à l'aide de Documentation de connexion Facebook et assurez-vous que votre procédure de connexion requiert ces deux autorisations de base :
Générer un jeton d'accès :
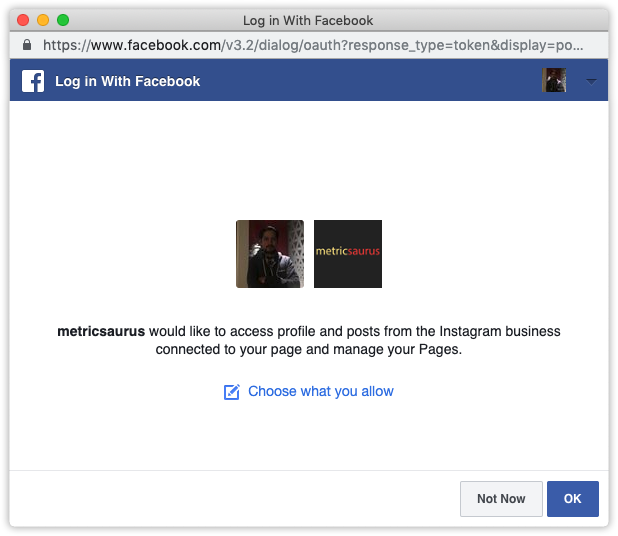
L'exécution d'actions depuis le tableau de bord de l'application sur le compte Instagram nécessite un jeton d'accès utilisateur. Sur le côté droit de la page du tableau de bord, ouvrez Menu déroulant Utilisateur ou Page et sélectionnez Obtenir le jeton d'accès utilisateur.
Une fenêtre contextuelle apparaîtra pour vous informer qu'une application (dans ce cas, votre application) demande les autorisations mentionnées ci-dessus. Simp Appuyez simplement sur le bouton « Continuer » ou « OK » pour obtenir le jeton d'accès utilisateur dans le champ « Jeton d'accès » de votre tableau de bord.
Nous allons maintenant exécuter quelques requêtes de base sur le compte Instagram à l'aide du jeton d'accès utilisateur.
1. Obtenir l'ID de la page Facebook :
Tout d'abord, nous avons besoin de l'identifiant de la page Facebook connectée au compte Instagram Business. Pour cela, exécutez la requête Get suivante dans le tableau de bord.
Cela renverra le nom et l'identifiant des pages Facebook appartenant à l'utilisateur. Le résultat ressemblera à ceci :
Copiez l'ID de la page connectée au compte Instagram professionnel.
2. Obtenir l'ID du compte Instagram professionnel :
À l'aide de l'ID Facebook, saisissez le script suivant dans la barre de commandes, puis cliquez sur « Envoyer ».
Vous obtiendrez le résultat suivant :
3. Obtenir les objets multimédias du compte Instagram :
Copiez l'identifiant Instagram du résultat et exécutez le script suivant pour obtenir les identifiants de toutes les stories actuellement publiées sur le compte Instagram professionnel.
Le résultat contiendra un identifiant pour chaque article.
Ceci n'était qu'un exemple. Grâce à l'API Instagram Graph, vous pouvez également obtenir d'autres informations, telles que les métadonnées d'un utilisateur Instagram, et effectuer une recherche par hashtag.
Passons maintenant à une autre méthode pour extraire des données d'Instagram.
Scraping Instagram avec Cloud Scrapper sans code
Pour ceux qui n'ont pas de formation en codage, la méthode ci-dessus peut être difficile à comprendre, et encore moins à mettre en œuvre. Mais ne vous inquiétez pas. Il existe des scrapers Instagram qui font le travail sans nécessiter de code.
Voici comment scraper Instagram à l'aide de l'un des outils suivants : Apify.
Accédez à la page du scraper Instagram d'Apify :
Ouvrez la page du scraper Instagram d'Apify et cliquez sur Essai gratuit bouton.

Inscrivez-vous sur Apify avec votre adresse e-mail ou vos comptes Google ou GitHub. Vous accéderez alors à la console Apify, où se déroule le véritable scraping Instagram.
Collecter les URL Instagram cibles :
À l'aide de l'application ou du site Web Instagram, collectez toutes les URL de profil des comptes Instagram que vous souhaitez récupérer. Sur la console Apify, Collez toutes ces URL une par une dans les champs de saisie. Pour les saisir toutes en une seule fois, cliquez sur le bouton « Modification groupée ».
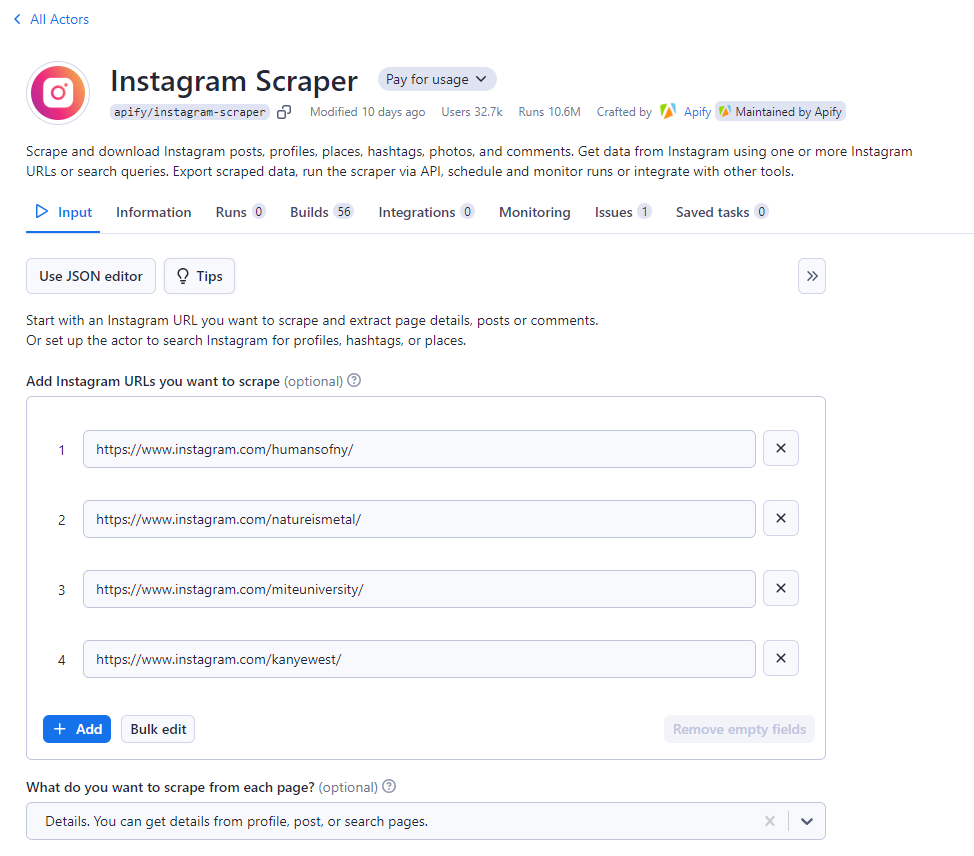
Apify propose trois options de scraping pour les URL fournies. Vous pouvez extraire les publications et les commentaires, ou obtenir différents détails à partir des profils.
Cliquez sur Enregistrer et démarrer :
Laissez le reste des paramètres inchangés, puis appuyez sur Enregistrer et Démarrer pour exécuter le scraper. Le résultat se présentera sous la forme d'un tableau contenant un nombre de lignes égal au nombre nbsp;d'URL de profil que vous avez fournies avec plusieurs colonnes contenant des métadonnées de profil telles que la biographie, le nombre d'abonnés, le nombre de publications, le nombre de bobines, l'ID de compte et le statut de vérification de quelques noms.

Enregistrer les résultats :
Appuyez maintenant sur le bouton « Exporter les résultats » et sélectionnez le format de fichier souhaité dans la fenêtre contextuelle. Vous pouvez également nettoyer les données en sélectionnant ou en omettant les champs dont vous n'avez pas besoin. Après cela, vous pouvez télécharger les résultats, les afficher dans un nouvel onglet ou les partager via un lien.

Scraper Instagram à l'aide d'un langage de programmation
Créer votre propre scraper Instagram peut être la solution la plus efficace si vos besoins sont atypiques et que vous disposez d'un programme solide. Vous pouvez utiliser n'importe quel langage de programmation associé à un framework de scraping web.
Ce guide explique comment scraper des données Instagram à l'aide de Python et de Selenium, un framework d'automatisation de navigateur.
Importer les bibliothèques essentielles :
Pour commencer, importez les bibliothèques de base, notamment Selenium, son pilote Web et Selenium-Stealth, afin d'empêcher toute détection.
La bibliothèque pprint nous aidera à imprimer le résultat proprement pour une meilleure lisibilité.
Collecter les noms d'utilisateur Instagram :
Créez une liste et ajoutez les noms d'utilisateur des profils Instagram que vous ciblez.
La variable de sortie est un dictionnaire que nous utiliserons pour stocker les résultats.
Définir la fonction principale :
La fonction principale parcourt la liste des noms d'utilisateur un par un et appelle la fonction de récupération sur chaque nom d'utilisateur.
Définissez une fonction pour gérer les paramètres du navigateur :
Cette fonction ajuste les paramètres du navigateur avant chaque demande de scraping afin d'ajouter l'anonymat et d'éviter la détection par Instagram. Ces modifications incluent la rotation des proxys, la configuration des paramètres Selenium-Stealth et la création d'un agent utilisateur artificiel.
Définir une fonction de scraping :
La fonction scrape() appelée dans la fonction principale prend un seul nom d'utilisateur Instagram comme argument et crée un Point de terminaison du profil que nous utiliserons pour envoyer une requête via le navigateur Chrome via la fonction prepare_browser().
Nous vérifierons également l'état de la demande. Si votre demande a été redirigée vers la page de connexion, cela signifie que la demande a échoué. Tandis que si la S'il n'y avait pas de chaîne de connexion, la demande a réussi et le résultat sera analysé au format JSON et envoyé à la fonction parse_data() avec le nom d'utilisateur.
Définissez la fonction parse_data() :
Cette fonction analyse les données JSON de l'argument user_data pour obtenir le champ de données souhaité. Dans cet exemple, nous récupérons le nom complet de l'utilisateur, la catégorie de compte, le nombre d'abonnés et les légendes des publications.
Écrivez le code du pilote :
Le code du pilote lance le processus de scraping, extrait les données dans la variable de sortie et appelle la fonction pprint() pour les afficher correctement.
Contournement de la détection grâce au navigateur AdsPower Antidetect
Instagram est strict en matière de scraping et offre un accès très limité aux données publiques sur sa plateforme. Cela inclut des informations de base telles que p;ID de profil, nombre d'abonnés, mentions « J'aime » et nombre de commentaires. Creuser plus profondément nécessite une connexion qui va à l'encontre des politiques d'Instagram et peut entraîner la suspension du compte.
C'est là qu'AdsPower entre en jeu : il vous aide à rester discret lorsque vous récupérez des données Instagram susceptibles d'enfreindre les politiques d'Instagram.AdsPower utilise des techniques d'anti-détection telles que la rotation d'adresses IP et la limitation de débit pour contourner les mesures anti-scraping.
Alors la prochaine fois que vous scraperez Instagram en utilisant un outil sans code ou des API Instagram non officielles, assurez-vous deUtilisez AdsPower le navigateur anti-détection pour contourner la détection.
Conclusion
Instagram autorise le scraping uniquement pour les données accessibles au public sur sa plateforme, pour lesquelles il fournit deux API. Mais Ces API offrent un niveau de scraping très basique, sans pour autant vous permettre d'extraire des données Instagram réellement pertinentes.
Cela nous laisse avec des scrapers Web tiers ou la création de votre propre scraper à l'aide de langages de programmation. Cependant, le scraping d'Instagram nous L'utilisation de ces méthodes non officielles présente de bonnes chances d'être détectée. Veillez donc à utiliser le navigateur anti-détection AdsPower pour une protection renforcée.

Les gens lisent aussi
- Les 10 meilleurs navigateurs headless pour le web scraping : Avantages et inconvénients

Les 10 meilleurs navigateurs headless pour le web scraping : Avantages et inconvénients
Découvrez les meilleurs navigateurs headless pour le web scraping. Apprenez en quoi ils diffèrent des navigateurs classiques et explorez des options légères pour une collecte de données efficace...
- Meilleures plateformes de publicité native pour les éditeurs

Meilleures plateformes de publicité native pour les éditeurs
Explorez les meilleures plateformes de publicité native pour les éditeurs. Découvrez comment optimiser vos annonces natives et utiliser AdsPower pour maximiser votre trafic.
- Meilleurs sites web musicaux débloqués pour l'école et le travail (2026)

Meilleurs sites web musicaux débloqués pour l'école et le travail (2026)
Découvrez les meilleurs sites web musicaux débloqués pour l'école et le travail.
- Meilleures idées de revenus passifs sur Reddit pour les débutants (Guide 2026)

Meilleures idées de revenus passifs sur Reddit pour les débutants (Guide 2026)
Vous cherchez des idées pour générer des revenus passifs ? Découvrez 5 méthodes éprouvées par les utilisateurs de Reddit pour gagner de l’argent en 2026.
- Peut-on consulter les stories Instagram anonymement ? Guide complet 2026

Peut-on consulter les stories Instagram anonymement ? Guide complet 2026
Apprenez comment consulter les Stories Instagram anonymement en 2026 et découvrez la méthode la mieux adaptée à vos besoins en matière de confidentialité et de navigation.
