
របៀបធ្វើ Web Scraping ដោយប្រើ Javascript: ការណែនាំដ៏ទូលំទូលាយ
ចង់រៀនពីរបៀបធ្វើ web scraping ដោយប្រើ Javascript ប៉ុន្តែមិនដឹងថាត្រូវចាប់ផ្តើមពីណា? កុំបារម្ភ។
នៅក្នុងប្លក់នេះ យើងនឹងផ្តល់ឱ្យអ្នកនូវព័ត៌មានចាំបាច់ទាំងអស់ដែលអ្នកត្រូវការដើម្បីចាប់ផ្តើមការ scraping Javascript ។ លើសពីនេះ យើងនឹងណែនាំអ្នកពីដំណើរការមួយជំហានម្តងមួយៗនៃការលុបគេហទំព័រដោយប្រើ JavaScript ជាមួយ Puppeteer។
តោះចាប់ផ្តើម។
តើអ្វីជា Javascript ការកោស?
ក្នុង យុគសម័យ ឌីជីថល នាពេលបច្ចុប្បន្ននេះ JavaScript សម្រាប់ បណ្ដាញ scraping បាន ក្លាយជា ជា សំខាន់ sk ឈឺ មិនមែនសម្រាប់តែ អ្នកអភិវឌ្ឍន៍ ទិន្នន័យ អ្នកចូលចិត្ត។ ប៉ុន្តែ ក៏សម្រាប់ អ្នកទីផ្សារ ដើម្បី រៀន។
នៅ ស្នូលរបស់វា JavaScript scraping គឺជា ដំណើរការ នៃ ដោយប្រើ បណ្ណាល័យដែលមានមូលដ្ឋានលើ JavaScript ឬ ឧបករណ៍&nb sp;ទៅ ស្រង់ចេញ ទិន្នន័យដ៏មានតម្លៃ ពីគេហទំព័រ ខណៈពេលដែល អ្នក អាច ប្រើ កម្មវិធី ភាសា ដូចជា Python to scrape a website, Javascript scraping មានប្រយោជន៍ជាពិសេសសម្រាប់ការប្រមូលព័ត៌មានពីគេហទំព័រដែលបង្ហាញមាតិកាខ្លាំងនៅលើ
JavaScript
មិនថាអ្នកកំពុងស្វែងរកការវិភាគនិន្នាការទីផ្សារ ប្រមូលផ្តុំភាពវៃឆ្លាតក្នុងការប្រកួតប្រជែង ឬប្រមូលទិន្នន័យដើម្បីបង្កើតការនាំមុខសម្រាប់អាជីវកម្មរបស់អ្នកទេ ការលុបចោលទិន្នន័យដោយប្រើ JavaScript អាចជាឧបករណ៍ដែលមិនអាចកាត់ថ្លៃបាន។ វិធីសាស្រ្តនេះប្រើប្រាស់សមត្ថភាពរបស់ JavaScript ដែលជាភាសាដែលបង្កប់យ៉ាងជ្រៅនៅក្នុងការអភិវឌ្ឍន៍គេហទំព័រ ដើម្បីរុករក ជ្រើសរើស និងទាញយកទិន្នន័យពីគេហទំព័រផ្សេងៗ។
ឥឡូវនេះ ដើម្បីឱ្យយើងយល់ថាអ្វីទៅជាការស្កែតគេហទំព័រ Javascript សូមរកឱ្យឃើញនូវវិធីណាខ្លះដែលអ្នកអាចប្រើ Javascript ដើម្បីបំបែកគេហទំព័រមួយ។
3 វិធីទូទៅ ដើម្បី កោស a គេហទំព័រ ការប្រើប្រាស់ Javascript
មានវិធីជាច្រើនដែលអ្នកអាចប្រើ Javascript ដើម្បីលុបគេហទំព័រមួយ។ ប៉ុន្តែតើអ្នកគួរប្រើមួយណា? ជាការប្រសើរណាស់, ចម្លើយទៅនឹងវាអាស្រ័យលើតម្រូវការ scraping របស់អ្នក។ នៅក្នុងផ្នែកនេះ យើងនឹងពន្យល់ពីវិធីទូទៅចំនួនបីដែលមនុស្សប្រើដើម្បីលុបគេហទំព័រដោយប្រើ Javascript។ rubik; ទំហំពុម្ពអក្សរ៖ 18pt; data-type="text">Cheerio សម្រាប់ គេហទំព័រសាមញ្ញ ឋិតិវន្ត គេហទំព័រ
តើអ្នកបានឃើញ HTML គេហទំព័រដែលមាតិកា ផ្ទុកយ៉ាងលឿន ក្នុង សំណើដំបូង ទេ? មែនហើយ នោះហើយជា ព្រោះថា ពួកវា មិន មាន មាតិកាធ្ងន់ ដូច វីដេអូ ឬ ចលនាស្មុគ្រស្មាញ។ class="forecolor" style="color: #1e4dff;">Cheerio គឺជាជម្រើសដ៏ល្អមួយ។
ដោយការទាញយក HTML ឆៅនៃទំព័រតាមរយៈម៉ាស៊ីនភ្ញៀវ HTTP Cheerio អនុញ្ញាតឱ្យអ្នកឆ្លងកាត់ និងរៀបចំ DOM យ៉ាងងាយស្រួល។
វាមានទម្ងន់ស្រាល និងលឿន ជាចម្បងព្រោះវាមិនចាំបាច់ផ្ទុកបរិយាកាសកម្មវិធីរុករកទាំងមូលទេ។ ដូចដែលយើងបានលើកឡើង វិធីសាស្ត្រនេះគឺល្អឥតខ្ចោះសម្រាប់គេហទំព័រសាមញ្ញ និងឋិតិវន្ត ដែលទិន្នន័យអាចរកបានយ៉ាងងាយស្រួលក្នុងកូដ HTML។
អ្នកធ្វើអាយ៉ង សម្រាប់ ការកោស ខ្លឹមសារថាមវន្ត
ប្រសិនបើអ្នកកំពុងដោះស្រាយជាមួយគេហទំព័រដែលស្មុគស្មាញជាង គេហទំព័រមួយដែលមានខ្លឹមសារថាមវន្តដូចជាវីដេអូ និងរូបភាព ឬគេហទំព័រ JavaScript-heavy ដែលមាតិកាត្រូវបានផ្ទុកដោយថាមវន្ត Puppeteer ដែលជាបណ្ណាល័យ Node គឺជាជម្រើសដ៏ល្អបំផុត។
Puppeteer ប្រើ a headless browser, a web browser ដោយគ្មាន a graphical user interface(GUI), ដើម្បី អន្តរកម្ម ជាមួយ web វា អាច ត្រាប់តាម អ្នកប្រើប្រាស់ សកម្មភាព ដូចជា ការចុច ប៊ូតុង ឬ រំកិល, ចាំបាច់ សម្រាប់ ការចូលប្រើ មាតិកា ដែល លេចឡើង ជា a លទ្ធផល នៃ />
Puppeteer គឺ មានថាមពល សម្រាប់ scraping web កម្មវិធីទំនើប ដែល ពឹងផ្អែកលើ AJAX&nb sp;និង ទាមទារ a កម្មវិធីរុករក បរិស្ថានពេញលេញ ដើម្បី ប្រតិបត្តិ JavaScript កូដ និង បង្ហាញ មាតិកា។
Scrape a គេហទំព័រ ការប្រើប្រាស់ jQuery
ពេលខ្លះ អ្នក អាច មិនត្រូវការ ដើម្បី ចំនួន ធំ នៃ ទិន្នន័យ។ អ្នក អាច ត្រូវការ ដើម្បី ស្រង់ចេញ ព័ត៌មានរហ័ស ម្តង ដូចជា ការដកយក អាសយដ្ឋានអ៊ីមែល ជាក់លាក់។ ក្នុង ករណីបែបនេះ jQuery អាចជា ឧបករណ៍ ងាយស្រួល។ ទោះបីជា វាជា ផ្នែកខាងអតិថិជន ស្គ្រីប កំពុងដំណើរការ នៅក្នុង កម្មវិធីរុករក , អ្នក អាច ប្រើ jQuery ដើម្បី ជ្រើសរើស និង ស្រង់ ទិន្នន័យ ពី គេហទំព័រ ទំព័រ យ៉ាងងាយស្រួល។
វិធីសាស្ត្រនេះមានប្រយោជន៍ជាពិសេសសម្រាប់កិច្ចការលុបបំបាត់ដោយការផ្សព្វផ្សាយ។ វាសាមញ្ញដូចជាការបើកកុងសូលរបស់អ្នក សរសេរកូដ jQuery ពីរបីបន្ទាត់ និងទាញយកព័ត៌មានដែលត្រូវការ។ ទោះជាយ៉ាងណាក៏ដោយ វិធីសាស្រ្តនេះមិនស័ក្តិសមសម្រាប់កិច្ចការបោសសម្អាតទ្រង់ទ្រាយធំ ឬស្វ័យប្រវត្តិទេ។
វិធីសាស្រ្តទាំងនេះនីមួយៗមានសំណុំគុណសម្បត្តិរបស់វា ហើយស័ក្តិសមសម្រាប់តម្រូវការការរើសអេតចាយផ្សេងៗគ្នា។ មិនថាវាជាការទាញយកទិន្នន័យតែមួយមុខ ឬកិច្ចការស្មុគ្រស្មាញដែលពាក់ព័ន្ធនឹងមាតិកាថាមវន្ត JavaScript ផ្ដល់នូវដំណោះស្រាយដ៏រឹងមាំ និងអាចបត់បែនបាន។
យ៉ាងណាក៏ដោយ បើតាមការណែនាំនេះ យើងនឹងធ្វើការលុបគេហទំព័រក្នុង Javascript ដោយប្រើ Puppeteer។ សូមណែនាំអ្នកពីដំណើរការមួយជំហានម្តង ៗ នៃរបៀបធ្វើវិបសាយដោយប្រើប្រាស់ Javascript ជាមួយ Puppeteer។
តើធ្វើដូចម្តេច ធ្វើ គេហទំព័រ ការខ្ចាត់ខ្ចាយ ដោយប្រើ Javascript អាយ៉ង?
គេហទំព័រ scraping អាច ពេលខ្លះ មានអារម្មណ៍ថា គួរឱ្យភ័យខ្លាច, ប៉ុន្តែ ភារកិច្ច ក្លាយជា 10x ងាយស្រួលជាង ប្រសិនបើ អ្នក ដឹង សិទ្ធិ ឧបករណ៍we's ។ រុករក របៀប ដើម្បី ប្រើ Puppeteer, a Node library, សម្រាប់ web scraping ។ Puppeteer គឺ a ល្អឥតខ្ចោះ Javascript ឧបករណ៍ សម្រាប់ ថាមវន្ត។ />
តោះ បំបែក ចុះ ដំណើរការ ចូលទៅក្នុង បី ជំហានសាមញ្ញ បង្ហាញ អ្នក របៀប ឆ្លាក់ រូបភាព ពី a Google ស្វែងរក "រីករាយ ឆ្កែ" តោះ មុជទឹក ចូល!
ជំហាន 1: បង្កើត a ថតថ្មី និង ការដំឡើង អាយ៉ង
ដំបូង រឿង ជាដំបូង តោះ កំណត់ គម្រោង បរិស្ថានរបស់យើង។ ដំបូង បង្កើត a គម្រោង ថ្មី ថត ចាប់ផ្ដើម
ចាប់ផ្ដើម style="line-height: 2;">បន្ទាប់មក ដំឡើង Puppeteer ដែល យើង នឹង ប្រើ សម្រាប់ scraping។ បើក របស់អ្នក កុងសូល និង ប្រតិបត្តិ រចនាប័ទ្ម ដូចខាងក្រោម line
: 2;">
- text-indent: 0;">សម្រាប់ បង្កើត a ថតឯកសារថ្មី៖ mkdir web-scraping-puppeteer
-
សម្រាប់ ផ្លាស់ទី ចូលទៅក្នុង the directory: -weight; data-type="text">cd web-scraping-puppeteer
-
ការចាប់ផ្ដើម a new Node.js project: span; data-type="text">npm init -y
-
ការដំឡើង Puppeteer: npm ដំឡើង puppeteer
ជំហាន 2: ការសរសេរ លេខកូដ ដំបូង
ឥឡូវនេះ តោះ សរសេរ កូដដំបូង ដើម្បី បើកដំណើរការ a កម្មវិធីរុករក រុករក ទៅ Google រូបភាព និង ស្វែងរក សម្រាប់ "រីករាយ g" យើងនឹង ប្រើ Puppeteer ដើម្បី បើក a កម្មវិធីរុករក បង្អួចថ្មី កំណត់ ច្រកមើល និង ធ្វើអន្តរកម្មជាមួយ ទំព័រ ធាតុ។ />
នេះគឺជា លេខកូដ សម្រាប់ នេះ ជំហាន៖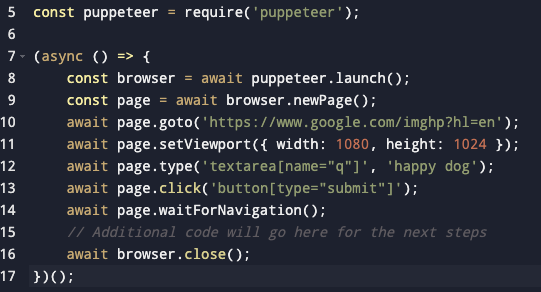
ការពន្យល់ នៃ កូដ៖
-
const puppeteer = require('puppeteer');
-
ចងចាំ នៅក្នុង ជំហានដំបូង យើង បានដំឡើង the Puppeteer នៅក្នុង ប្រព័ន្ធ របស់យើង? មែនហើយ បន្ទាត់ នេះ នាំចូល បណ្ណាល័យអាយ៉ង ទៅក្នុង អក្សរ វា បន្ទាប់មក nbsp;អនុញ្ញាតឱ្យ យើង ប្រើ មុខងារ របស់វា ដើម្បី គ្រប់គ្រង កម្មវិធីរុករក គ្មានក្បាល។
-
-
(async () => { ... })();
-
បន្ទាត់ នេះ នឹង ប្រកាស មុខងារអសមកាល មុខងារនេះ នឹង ចាត់ចែង បណ្ដាញ កិច្ចការ មុខងារអសមកាល ដើម្បីអនុគមន៍ រង់ចាំ សម្រាប់ សកម្មភាពជាក់លាក់ ដើម្បី បញ្ចប់ (ចូលចិត្ត ទំព័រ ផ្ទុក) មុន ផ្លាស់ទី លើ ទៅ ជំហានបន្ទាប់ ដែល សំខាន់ បណ្ដាញ ក្នុង
-
-
const browser = await puppeteer.launch();
-
បន្ទាត់ នេះ ប្រាប់ Puppeteer ដើម្បី ចាប់ផ្តើម a ថ្មី កម្មវិធីរុករក សម័យ។ ការរង់ចាំ ពាក្យគន្លឹះ ត្រូវបានប្រើ ដើម្បី ធានាថា កម្មវិធីរុករក ត្រូវបានបើកដំណើរការយ៉ាងពេញលេញ មុនពេល ស្គ្រីប ដំណើរការ។
-
-
const page = await browser.newPage();
-
បន្ទាប់ពី បើកដំណើរការ កម្មវិធីរុករកតាមអ៊ីនធឺណិត ពាក្យបញ្ជានេះ បើក a ទំព័រថ្មី (ឬ tab) នៅក្នុង the browser.
-
- 0;">រង់ចាំ page.goto('https://www.google.com/imghp?hl=en');
-
ស្គ្រីប រុករក ទំព័រ បានបើក ទៅកាន់ URL ដែលបានបញ្ជាក់ ដែលជា រូបភាព Google ស្វែងរក ទំព័រ ក្នុង ករណីនេះ។ ការរង់ចាំ ពាក្យគន្លឹះ ធានាថា ការរុករក គឺ បានបញ្ចប់ មុន បន្ត។
-
-
រង់ចាំ page.setViewport({ width: 1080, height: 1024 });
-
នេះ កំណត់ វិមាត្រ នៃ ទិដ្ឋភាព (ផ្នែក អាចមើលបាន នៃ ទំព័រ ) វាមានសារៈសំខាន់ សម្រាប់ រូបថតអេក្រង់ ឬ សម្រាប់ ទំព័រ ដែល ផ្លាស់ប្តូរ ប្លង់ ផ្អែកលើ នៅលើ ទំហំអេក្រង់ ។
-
-
រង់ចាំ page.type('textarea[name="q"]', 'happy dog');
-
ពាក្យបញ្ជានេះ ក្លែងធ្វើ វាយ អត្ថបទ 'រីករាយ dog' ទៅក្នុង an បញ្ចូល វាល នៅលើ ទំព័រ sp ecifically a text ជាមួយ ឈ្មោះ គុណលក្ខណៈ 'q' (ដែល នៅក្នុង Google រូបភាព ជា វាលស្វែងរក )។
-
-
រង់ចាំ page.click('button[type="submit"]');
-
បន្ទាត់ នេះ ក្លែងធ្វើ a ចុច នៅលើ ប៊ូតុង បញ្ជូន នៃ ទម្រង់បែបបទ កេះ ការស្វែងរក។
-
-
រង់ចាំ page.waitForNavigation();
-
បន្ទាប់ពី ចុច ប៊ូតុង បញ្ជូន ពាក្យបញ្ជានេះ រង់ចាំ សម្រាប់ ទំព័រ nbsp;ការរុករក ដើម្បី បញ្ចប់ (ឧ. រង់ចាំ សម្រាប់ លទ្ធផល ដើម្បី ផ្ទុក)។
-
-
រង់ចាំ browser.close();
-
នៅពេលដែល ទាំងអស់ ជំហានមុន ត្រូវបានបញ្ចប់ ពាក្យបញ្ជានេះ បិទ កម្មវិធីរុករក។
-
ជំហាន 3: ការទាញយក រូបភាព នៃ the "happy dog" ពី Google Images។
ឥឡូវនេះ គោលដៅ របស់យើង គឺ ដើម្បី ជ្រើសរើស រូបភាព យើង ចង់ ដើម្បី កោស និង កំណត់ ថ្នាក់របស់វា លេខសម្គាល់ និង ប្រភព URL side its />
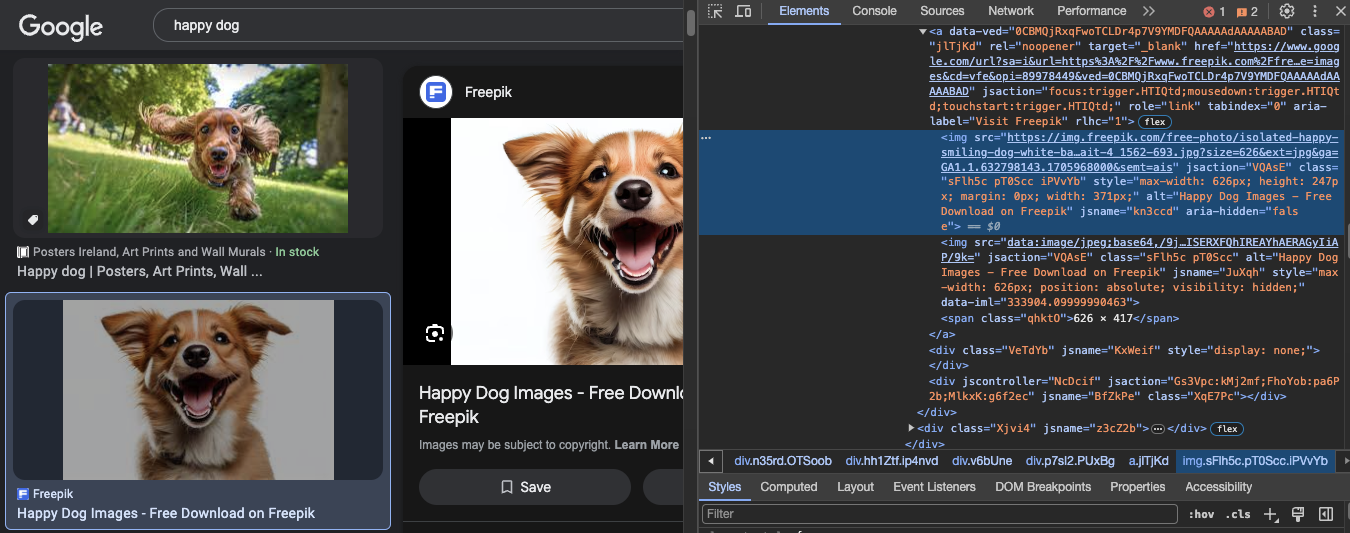
ដើម្បី ធ្វើ នោះ អ្នក ត្រូវការ ដើម្បី បើក កម្មវិធីរុករករបស់អ្នក ស្វែងរក "រីករាយ ឆ្កែ", និង ចុចលើ នេះ ima ge អ្នក ចង់ ដើម្បី កោស។ បន្ទាប់ពី រូបភាព ត្រូវបានពង្រីក ចុចកណ្ដុរស្ដាំលើ វា និង&&&&&&&&&&&&&&&&&& ជ្រើសរើស ជម្រើស "ពិនិត្យ"
ពិនិត្យ ជម្រើស នឹង បង្ហាញ អ្នក div កុងតឺន័រ នៃ រូបភាព ដែល នឹង មាន&nbs p;ថ្នាក់របស់វា លេខសម្គាល់ និង ប្រភព URL ដែល អ្នក ត្រូវការ ដើម្បី ចម្លង ទៅ រួមបញ្ចូល នៅក្នុង កូដ របស់យើង។
rubik;" data-type="text">នេះគឺជា អ្វីដែល កូដ ពេញលេញ នឹង មើលទៅដូច៖
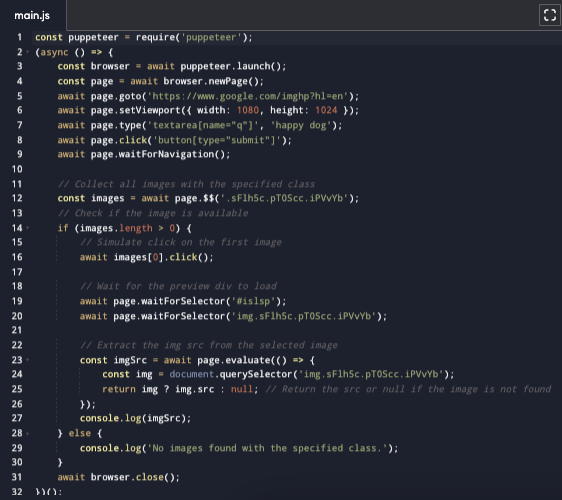
rubik;" data-type="text">ក្នុង កូដនេះ៖
-
ដំបូងយើង ធានា ថា Puppeteer រុករក ទៅកាន់ Google Images និង អនុវត្ត the search for "happy dog"
- 0;">នៅពេលដែល លទ្ធផល ត្រូវបាន បានផ្ទុក យើង ជ្រើសរើស រូបភាពទាំងអស់ ដែល ត្រូវនឹង the class '.sFlh5c.pT0Scc.iPVvYb'។
0;">យើង បន្ទាប់មក ចុចលើ រូបភាព ដែលចង់បាន នៅក្នុង បញ្ជី ដើម្បី កេះ ការមើលជាមុន។
-
យើង រង់ចាំ សម្រាប់ the មើលជាមុន កុងតឺន័រ (#islsp) រូបភាព ធំ ខាងក្នុង វា ដើម្បី ផ្ទុក។
-
ចុងក្រោយ ពួកយើង ស្រង់ចេញ src attribute of the large image, which មាន its URL។
ក្នុងករណី អ្នក កំពុងឆ្ងល់ យើង បានប្រើ “ប្រសិនបើ” ” ” សេចក្តីថ្លែងការណ៍ នៅក្នុង កូដនេះ ដើម្បី ធានា ត្រឡប់ “គ្មាន រូបភាព បានរកឃើញ ជាមួយ ថ្នាក់ បញ្ជាក់ ក្នុង ករណី នៃ ថ្នាក់ ខុស បើមិនដូច្នេះទេ ជួនកាល កូដ ខូច។
អ្នក បាន ឥឡូវនេះ បានរៀនដោយជោគជ័យ របៀប ដើម្បី ការ គេហទំព័រ ដោយប្រើ Javascript និង& nbsp;Puppeteer។ អ្នកអាចប្រើ វិធីដូចគ្នា ដើម្បី កោស រូបភាព ច្រើន ពី គេហទំព័រណាមួយ ។
ទោះជាយ៉ាងណាក៏ដោយ គេហទំព័រមួយចំនួន មិន មិនអនុញ្ញាត អ្នក ដើម្បី មាតិកា របស់ពួកគេ មាន បច្ចេកទេស ប្រឆាំងការកោស នៅក្នុង កន្លែង t មួក ធ្វើឱ្យ វា ពិបាក សម្រាប់ អ្នក ដើម្បីទទួលបាន ការងារ រួចរាល់។ ឬ កាន់តែអាក្រក់ អ្នក អាច បញ្ចប់ ឡើង ការបិទ ទាំងអស់គ្នា។ />
ប៉ុន្តែ នៅទីនោះ’s a ដំណោះស្រាយ ដើម្បី នេះ បញ្ហា ដូច ល្អ ទៅ ផ្នែក បន្ទាប់ ដើម្បី រៀន បន្ថែម អំពីថ្នាក់ របៀប style="color: #1e4dff;">scrape គេហទំព័រ without getting detected ឬ blocked style.
16pt; បន្ទាត់-កម្ពស់៖ 2; data-type="text">ប្រើ AdsPower សម្រាប់ ការរុករកដែលមិនបានរកឃើញ
ប្រសិនបើ អ្នក ចង់ ដើម្បី បន្ថែម ស្រទាប់ នៃ ការពារ ខណៈពេលដែល ទិន្នន័យ កំពុងដំណើរការ u ច្រៀងចាវ៉ាស្គ្រីប AdsPower ជា ល្អបំផុត ប្រឆាំងការរកឃើញ កម្មវិធីរុករក អ្នក អាចប្រើ។ AdsPower browser ensures a web scraping experience by effectively dodging anti-scraping>> style="line-height: 2;">អ្នក អាច ប្រើ វា ដើម្បី បង្កើត ទម្រង់ អ្នកប្រើប្រាស់ ច្រើន និង នៅសល់ អនាមិក នៅលើ រចនាប័ទ្ម សម្រាប់ #1e4dff;">ចុះឈ្មោះ ថ្ងៃនេះ ដើម្បី ធានា របស់អ្នក នៅថ្ងៃស្អែក។
រុំ ឡើង!
ការរៀន របៀប ដើម្បីធ្វើ បណ្ដាញ ការកោស ដោយប្រើ JavaScript បើក ឡើង a ពិភព នៃ ទិន្នន័យ លទ្ធភាព។ ថាតើ វា សម្រាប់ គម្រោង ផ្ទាល់ខ្លួន ឬ ការវិភាគវិជ្ជាជីវៈ ឧបករណ៍ ដូច អាយ៉ង ធ្វើឱ្យ វា អាចចូលប្រើបាន មានប្រសិទ្ធិភាព។
ប្រើ បច្ចេកទេស ដែលបានលើកឡើង នៅក្នុង ប្លក់នេះ និង កោស ព័ត៌មាន ព័ត៌មាន នៅលើ អ្នក ត្រូវការ។ ផងដែរ កុំភ្លេច ដើម្បី ប្រើ AdsPower សម្រាប់ សុវត្ថិភាព scraping។

មនុស្សក៏អានដែរ។
- ហ្គេមកំពូលទាំង 12 ដែលមិនត្រូវបានរារាំងដោយសាលារៀន (+ ការជួសជុលងាយៗ)

ហ្គេមកំពូលទាំង 12 ដែលមិនត្រូវបានរារាំងដោយសាលារៀន (+ ការជួសជុលងាយៗ)
ស្វែងរកហ្គេមចំនួន 12 ដែលមិនបិទសម្រាប់សាលារៀន រៀនវិធីជាក់ស្តែងដើម្បីចូលទៅកាន់គេហទំព័រហ្គេមដែលត្រូវបានបិទ
- របៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពនៅឆ្នាំ 2026

របៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពនៅឆ្នាំ 2026
ស្វែងយល់ពីរបៀបគ្រប់គ្រងគណនី Apple ច្រើនដោយសុវត្ថិភាពជាមួយនឹងគន្លឹះជាក់ស្តែង
- របៀបរកលុយលើ Substack ឆ្នាំ ២០២៦៖ យុទ្ធសាស្ត្ររកចំណូលសម្រាប់អ្នកបង្កើត

របៀបរកលុយលើ Substack ឆ្នាំ ២០២៦៖ យុទ្ធសាស្ត្ររកចំណូលសម្រាប់អ្នកបង្កើត
ចង់រកលុយលើ Substack ទេ? ការណែនាំនេះបំបែកវិធីសាស្រ្តរកប្រាក់ដែលបានបង្ហាញឱ្យឃើញ គន្លឹះក្នុងការរីកចម្រើន និងរបៀបដែលអ្នកបង្កើតប្រែក្លាយខ្លឹមសារទៅជាប្រាក់ចំណូល។
- ក្លូដចុះខ្សោយ ឬមិនអាចទាក់ទងក្លូដបាន? របៀបវិនិច្ឆ័យ និងជួសជុលបញ្ហាទូទៅ

ក្លូដចុះខ្សោយ ឬមិនអាចទាក់ទងក្លូដបាន? របៀបវិនិច្ឆ័យ និងជួសជុលបញ្ហាទូទៅ
តើ Claude មិនដំណើរការទេ ឬអ្នកកំពុងឃើញកំហុស "មិនអាចទាក់ទង Claude បាន"? ស្វែងយល់ពីរបៀបជួសជុលរង្វិលជុំចូល កំហុសផ្ទៀងផ្ទាត់ បញ្ហាបណ្តាញ និងច្រើនទៀត។
- Instagram ត្រូវបានចាក់សោរ ហើយត្រូវបានហាមឃាត់? តើធ្វើដូចម្តេចដើម្បីយកវាមកវិញ?

Instagram ត្រូវបានចាក់សោរ ហើយត្រូវបានហាមឃាត់? តើធ្វើដូចម្តេចដើម្បីយកវាមកវិញ?
Instagram បានចាក់សោគណនីរបស់អ្នក ហើយបន្ទាប់មកបានហាមឃាត់វា? ការណែនាំនេះគ្របដណ្តប់លើអ្វីដែលត្រូវធ្វើ និងរបៀបស្តារគណនីដែលត្រូវបានចាក់សោ ឬបិទជាបណ្ដោះអាសន្ន។
