
Zo scrap je Reddit op twee verschillende maar effectieve manieren
Neem een snelle blik
Ontdek verschillende methoden om Reddit te scrapen, kies de methode die het beste bij u past en leer hoe AdsPower u helpt onopgemerkt te blijven tijdens het proces.
Het is een no-brainer dat de door gebruikers gegenereerde gegevens van Reddit van onschatbare waarde zijn, zozeer zelfs dat Google en OpenAI gebruiken het om hun grote taalmodellen (LLM's) te trainen.
Maar hoe kun je Reddit doorzoeken en de waarde ervan benutten zonder dat het je geld kost?
Of je nu een ervaren programmeur bent of iemand die de complexe wereld van programmeren niet kent, er is een methode op maat voor jou.
In deze blog leer je hoe je op twee eenvoudige manieren Reddit kunt scrapen en toegang krijgt tot de schat aan informatie die Reddit te bieden heeft.
Maar voordat we ingaan op de details van hoe je Reddit kunt scrapen, kijken we eerst kort naar de soorten gegevens die je van Reddit kunt scrapen en wat je ermee kunt doen.
Welke gegevens kun je van Reddit scrapen?
Wanneer u Reddit scrapt, krijgt u toegang tot een breed scala aan waardevolle datapunten die voor diverse doeleinden kunnen dienen, van marktanalyse tot contentoptimalisatie. Dit zijn enkele van de belangrijkste soorten data die u van Reddit kunt scrapen:
-
Berichtinformatie: Dit omvat essentiële details zoals berichttitels, beschrijvingen, upvotes, downvotes, berichtdatum en de subreddit waarin het is geplaatst. Deze elementen zijn cruciaal wanneer u Reddit scrapt voor trendanalyse of om de betrokkenheid van gebruikers bij verschillende onderwerpen te meten.
-
Reactiegegevens: Reacties bieden uitgebreide inzichten in de mening van gebruikers. Door Reddit-reacties te scrapen, kun je de tekst, upvotes, downvotes en tijdstempels analyseren om de betrokkenheid te meten en belangrijke discussies te identificeren. Dit is handig om te begrijpen hoe gebruikers reageren op specifieke onderwerpen of merken.
-
Gebruikersprofielen: Door Reddit-gebruikersprofielen te scrapen, kun je informatie verzamelen over hun activiteiten, berichtgeschiedenis en subredditdeelname. Dit kan met name waardevol zijn bij het uitvoeren van demografisch onderzoek of het analyseren van hoe verschillende soorten gebruikers omgaan met content.
-
Subreddit-gegevens: Elke subreddit heeft zijn eigen unieke community en discussieset. Het scrapen van Reddit-subredditgegevens kan je helpen nichemarkten te identificeren, trends binnen specifieke communities te volgen en inzicht te krijgen in het algehele activiteitsniveau van verschillende subreddits.
-
Flair en tags: Veel subreddits gebruiken flairs of tags om berichten te categoriseren, waardoor het makkelijker wordt om Reddit-gegevens te scrapen voor contentanalyse. Hiermee kun je populaire onderwerpen, trends en interessegebieden binnen een specifieke subreddit of binnen meerdere communities identificeren.
Wat kun je doen met de gegevens van Reddit?
Reddit-scraping kan een krachtig hulpmiddel zijn voor diverse doeleinden, van bedrijfsanalyse tot contentcreatie. Zo kunt u de gegevens die u via Reddit-scraping verzamelt, effectief gebruiken:
-
Marktonderzoek: Met Reddit-scraping krijgt u toegang tot een schat aan marktinzichten door populaire berichten, reacties en discussies te analyseren. Door trending topics en belangrijke discussies te identificeren, kunt u op de hoogte blijven van opkomende trends en klantvoorkeuren.
-
Contentstrategie en SEO: Reddit-scraping kan een geweldige bron zijn voor zoekwoordenonderzoek en contentinspiratie. Door berichttitels, discussies en veelgebruikte trefwoorden in Reddit-threads te analyseren, kunt u uw contentstrategie verbeteren en uw SEO-ranking verbeteren met zeer relevante trefwoorden die al aantrekkelijk zijn voor uw publiek.
-
Klantenservice en -betrokkenheid: Door Reddit-gegevens te scrapen, kunnen merken veelvoorkomende zorgen of feedback van klanten over hun producten identificeren. Door Reddit-reacties en -berichten te analyseren, kunt u uw klantenservicestrategieën of productfuncties verfijnen op basis van echte gebruikersinput.
-
Productontwikkeling: Door gegevens van Reddit te scrapen, kunt u feedback verzamelen over bestaande producten of onvervulde behoeften in uw markt ontdekken. Door discussies te volgen en sentimenten te analyseren, kunt u weloverwogen beslissingen nemen over productverbeteringen of nieuwe functies.
-
Adverteren en marketing: Met Reddit-scraping kunt u gegevens verzamelen over de interesses en het gedrag van gebruikers. Dit helpt bij het maken van gerichte advertentiecampagnes die aanslaan bij specifieke Reddit-community's. Inzicht in de soorten berichten en reacties die betrokkenheid genereren, stelt u in staat uw marketinginspanningen af te stemmen op de juiste doelgroep.
-
Academisch en gedragsonderzoek: Onderzoekers gebruiken Reddit-scraping vaak om online gedrag, sociale interacties en taaltrends te bestuderen. Het analyseren van discussies op Reddit kan waardevolle inzichten opleveren in online discussies, groepsdynamiek en communitygedrag.
Verschillende manieren om Reddit te scrapen
Mensen scrapen Reddit op veel verschillende manieren. Elk van deze methoden heeft zijn voor- en nadelen.
Sommige zijn heel eenvoudig en vereisen geen technische vaardigheden, terwijl andere juist lastig zijn en gemiddelde tot hoge programmeerkennis vereisen.
Laten we je kort kennis laten maken met de verschillende manieren om gegevens van Reddit te scrapen.
Handmatig Reddit scrapen
Dit is misschien wel de gemakkelijkste en meest directe manier om Reddit of een ander platform te scrapen. Er is geen enkele expertise voor nodig, alleen de mogelijkheid om gegevens te kopiëren en te plakken in een spreadsheet.
Media zoals foto's en profielfoto's kunnen eenvoudig worden gedownload van het platform, terwijl video's kunnen worden geëxtraheerd met behulp van externe websites voor het downloaden van video's.
Bovendien kunt u elk gegevenspunt controleren en ervoor zorgen dat alleen de juiste en relevante gegevens in de spreadsheet terechtkomen.
Omdat het hele proces echter handmatig is, kost het je veel tijd als je grote eisen hebt. Bovendien vergroot handmatig scrapen op Reddit de kans op menselijke fouten.
Schraap Reddit met behulp van de API
Reddit biedt een API waarmee ontwikkelaars apps en andere producten kunnen bouwen op het Reddit-platform. Je kunt deze API ook gebruiken om gegevens van Reddit te scrapen. Maar om dat te doen, moet je over matige programmeervaardigheden beschikken.
Daarnaast zijn er nog andere beperkende regels die Reddit heeft vastgesteld en waaraan je je moet houden om de API te kunnen gebruiken. Bovendien, na de 2023 Reddit-controverse, de API is tegen betaling en blijft alleen gratis voor ontwikkelaars van moderatietools of academische doeleinden.
Maak een aangepaste Reddit-scraper
Uw volgende optie is om Reddit te scrapen zonder API door een aangepaste Reddit-scraper helemaal opnieuw te bouwen. Deze methode is lastig, omdat er geavanceerde programmeervaardigheden voor nodig zijn, maar het is zeer veelbelovend als het je lukt.
Met deze methode kunt u de scraper aanpassen om elk type gegevens te extraheren dat andere kant-en-klare scrapers mogelijk niet kunnen extraheren. Bovendien kunt u scripts schrijven om de scraping-taken naar wens op te schalen.
Het ontwikkelen van een aangepaste Reddit-scraper is echter geen eenvoudige opgave en kost veel geld en tijd.
Gebruik de No-Code Reddit Scraper
Heb je geen programmeerachtergrond? Geen probleem. Er zijn talloze click & scrape-tools waarvoor geen programmeren nodig is.
Deze tools zijn beschikbaar in de vorm van gebruiksvriendelijke software of browserextensies waarmee je binnen enkele minuten met slechts een paar muisklikken gegevens van Reddit kunt scrapen.
Het echte voordeel is dat de meeste van deze tools een gratis abonnement hebben dat voor de meeste gebruikers vaak voldoende is.
Hoe scrap je gegevens van Reddit met code en geen code?
Laten we nu zonder verder oponthoud aan de slag gaan en ontdekken hoe je Reddit kunt scrapen met een no-code Reddit Scraper en een Python-bibliotheek.
Scrape Reddit met Parsehub (geen code)
Het handmatig scrapen van gegevens van Reddit kan een eeuwigheid duren. Hoewel het vinden van berichten, ze openen, wachten tot ze geladen zijn en vervolgens handmatig de gegevens kopiëren en plakken naar de spreadsheet mogelijk is, is het nog steeds contraproductief, vooral bij honderden berichten.
Laat automatische webscrapers deze taak voor u doen. Met deze tools kun je automatisch bijna alle soorten gegevens van Reddit scrapen, waaronder gebruikersnamen, links, berichttitels, datums, afbeeldingen en reacties, om er maar een paar te noemen.
Enkele van de toonaangevende no-code scrapingtools van Reddit zijn ParseHub, Apify en Octoparse.
Zoals eerder vermeld, is het scrapen van Reddit met een no-codetool een fluitje van een cent, maar je hebt wel wat begeleiding nodig om te beginnen.
Laten we leren hoe we Reddit kunnen scrapen met ParseHub.
-
Download ParseHub:Ga naar de officiële ParseHub-website en kies de juiste downloadoptie voor uw besturingssysteem. De installatie wordt gedownload. Voer de installatie uit en ParseHub wordt binnen enkele minuten geïnstalleerd.
-
Account aanmaken: Als u ParseHub voor het eerst gebruikt, moet uMeld u aan en maak een account aan. Het proces is supersnel. Voer uw naam, e-mailadres en wachtwoord in en u bent ingelogd op uw nieuwe account.
-
Nieuw project starten: Klik op het startscherm op de knop Nieuw project.
-
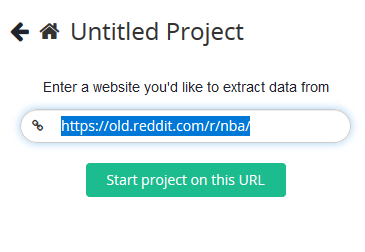
Plak op het nieuwe scherm de subreddit-link die u wilt scrapen. We raden u aan de oudere lay-out van Reddit te gebruiken, omdat deze het beste werkt voor scrapingdoeleinden.
-
We zullen de NBA-subreddit scrapen voor een demonstratie.
-
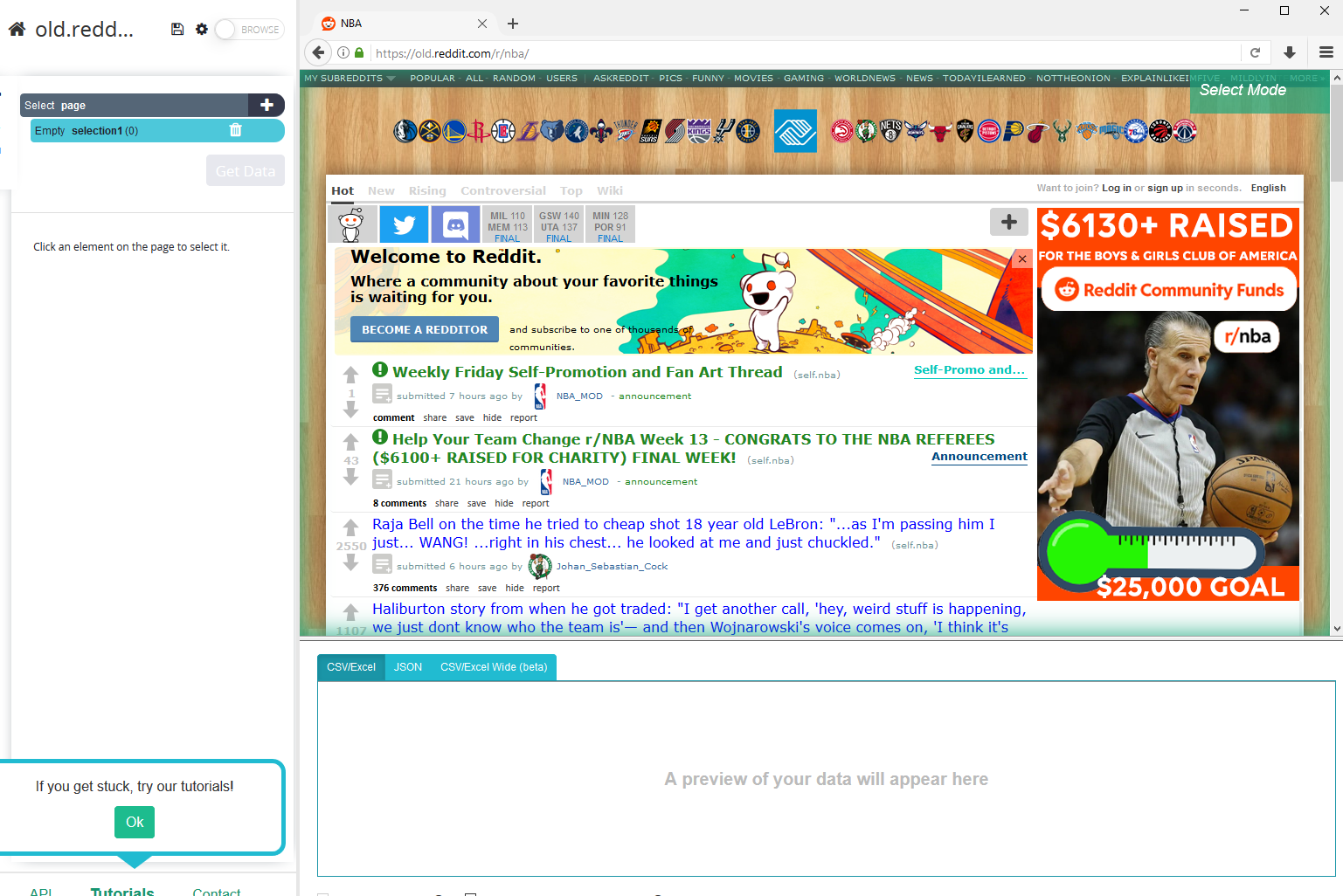
Druk op de startknop en de subreddit wordt geladen op het hoofdscherm.
-
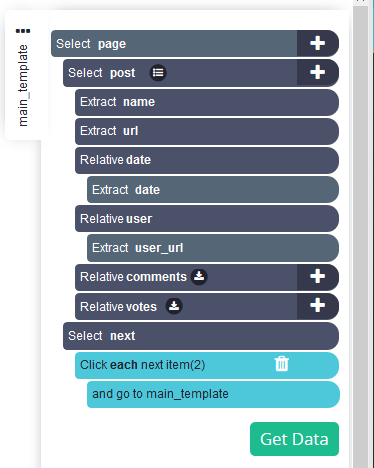
Selecteer relevante gegevens: Stel dat we de titels en links van alle berichten willen schrapen. Klik op de titel van het eerste bericht op de pagina. De geselecteerde berichttitel wordt groen en andere berichttitels worden geel. Selecteer nu de tweede berichttitel en alle titels worden groen, wat aangeeft dat alle zijn geselecteerd.
-
Geef in het zijpaneel een passende naam aan de selectie, bijvoorbeeld 'berichten'.
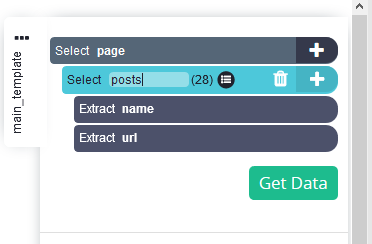
-
Maak meer selecties: Stel dat we ook de datum van elk bericht willen. Klik hiervoor op het "+"-symbool in de berichtenselectie en kies Relatieve selectie.
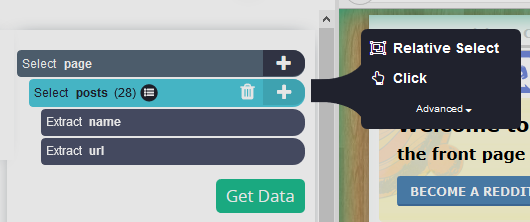
-
Klik nu op de titel van het eerste bericht en klik daarna op het tijdstempel van het bericht. De hele pagina begint er zo uit te zien.
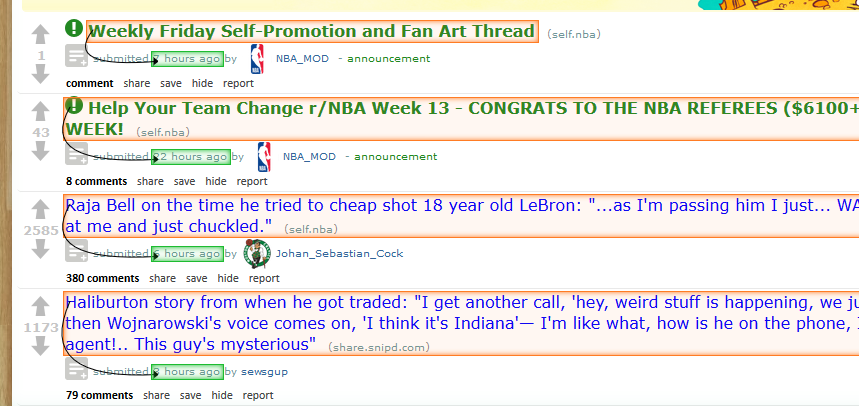
-
Hernoem de nieuw aangemaakte selectie naar datum.
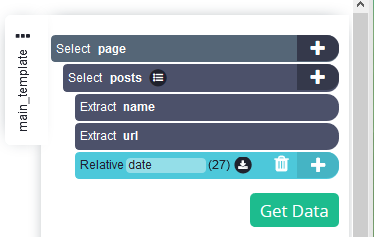
-
De datumselectie haalt het relevante tijdstempel eruit, maar we willen de datum en tijd van het bericht. Klik dus op de "+" symbool naast de datumselectie, klik op Geavanceerd om het volledige menu te openen en selecteer Uitpakken.
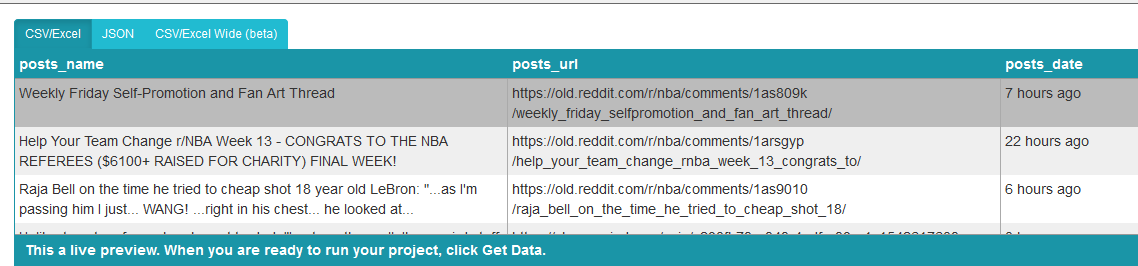
-
Open de vervolgkeuzelijst naast Uitpakken en selecteer "titelkenmerk".
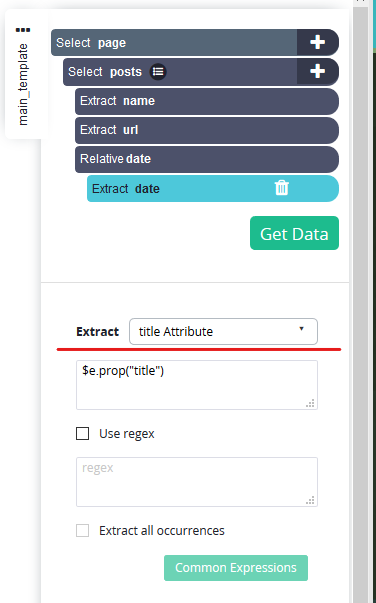
-
U zult merken dat de selectie nu de datums en tijden ophaalt.

-
Herhaal voor meer gegevenstypen: Herhaal de vorige stap voor gebruikersnamen, aantal reacties en upvotes.
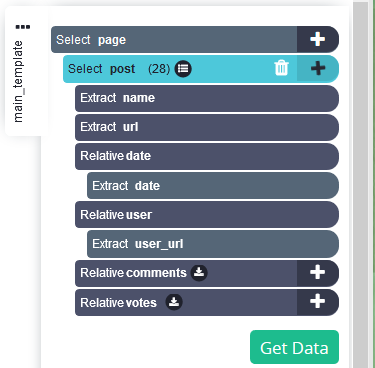
-
Paginering toevoegen: De selecties tot nu toe extraheren alleen de gegevens van de eerste pagina. Om naar de volgende pagina's te gaan, klikt u op het "+"-symbool van de paginaselectie en kiest u Selecteren.
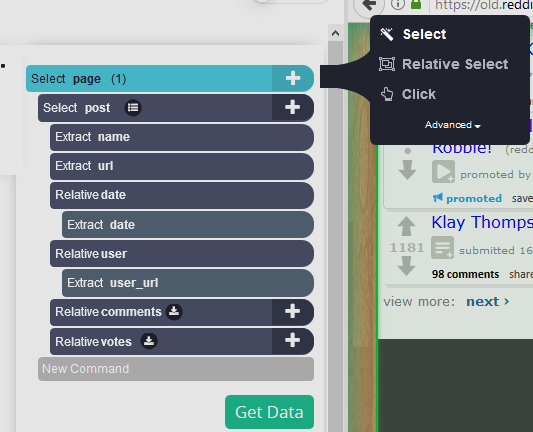
-
Scroll naar beneden en klik op Volgende.
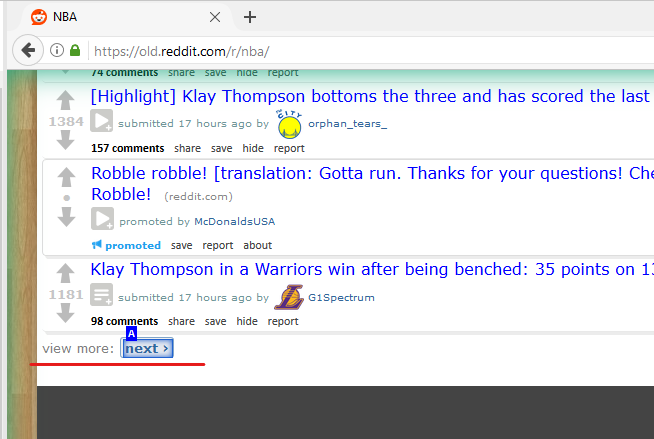
-
Klik op het "+"-symbool op de volgende selectie en kies Klikken.
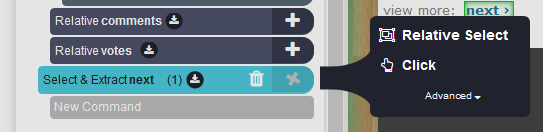
-
Er verschijnt een pop-up met de vraag of dit de knop voor de volgende pagina is. Selecteer Ja en voer het aantal pagina's in waarop moet worden geklikt. We hebben er 2 geschreven, dus in totaal scrapen we 3 pagina's. Klik nu op de knop Huidige sjabloon herhalen.
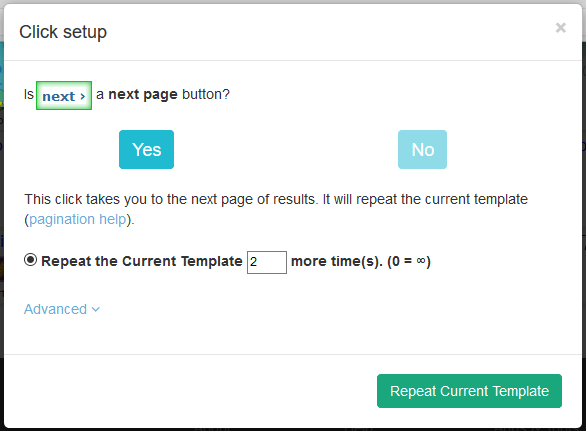
-
Het project is klaar.
-
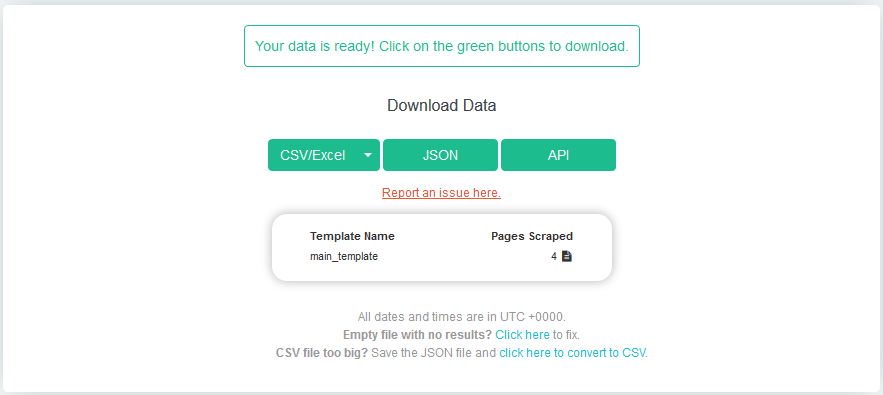
Het project uitvoeren: Druk op de knop Gegevens ophalen.

-
Selecteer Uitvoeren. Binnen een paar minuten zijn de gegevens klaar. Kies het gewenste bestandsformaat.
Schraap Reddit met Python (code)
Als je weet hoe je Reddit kunt scrapen met een no-codetool, vraag je je af waarom mensen voor dezelfde taak programmeerscripts schrijven.
Het antwoord ligt in de vrijheid die deze methode met zich meebrengt.
Met een Reddit-scraper zonder code kunt u alleen de gegevenstypen scrapen die het scrapen toestaat. Er kunnen ook andere beperkingen zijn, zoals paginalimieten of berichtlimieten.
Je kunt deze beperkingen mogelijk omzeilen door te upgraden naar het premium-abonnement. Maar dat kan een deuk in je portemonnee slaan, en bovendien, als je scrapingvereisten complex zijn, kunnen Reddit-scrappers zonder code dat niet. hulp.
Dit is het moment waarop je Reddit moet scrapen met Python of andere programmeertalen.
Als je Reddit scrapt met Python, kun je niet alleen alle gegevens en een willekeurig aantal pagina's extraheren, maar je kunt dit ook doen zonder ook maar een cent te betalen. Dit is alleen het geval als je zelf kunt coderen. Anders moet u een scraping-expert inhuren.
Laten we eens kijken hoe we Reddit kunnen scrapen met Python:
-
Installeer vereiste bibliotheken: Zorg ervoor dat u de benodigde bibliotheken hebt geïnstalleerd, zoals PRAW (Python Reddit API Wrapper) en Pandas.
-
Maak een Reddit-app: Ga naar de website van Reddit en maak een nieuwe applicatie. Verkrijg de client-ID, het clientgeheim, de gebruikersnaam en het wachtwoord.
-
Authenticeren: Gebruik de verkregen inloggegevens om te authenticeren met de API van Reddit met behulp van PRAW.
-
Kies Subreddit: Geef de subreddit op die u wilt scrapen.
-
Gegevens schrapen: Gebruik PRAW om berichten op te halen van de gekozen subreddit, d.w.z. geef het aantal berichten en de gewenste kenmerken op.
-
Gegevens opslaan: Sla de geschraapte gegevens op in een geschikt formaat, zoals een DataFrame met behulp van Pandas.
-
Analyseren of visualiseren: Analyseer of visualiseer de verzamelde gegevens zoals nodig voor uw project of analyse.
Voor een diepgaand begrip en codefragmenten voor elke stap, ga naar deze gedetailleerde blog.
Beveilig uw scrapingactiviteit tegen blokkering
Volgens Reddit's gebruikersovereenkomst, is het verboden om de site via automatisering te bezoeken en gegevens van Reddit te scrapen zonder voorafgaande toestemming.
Er is echter niet veel informatie te vinden over de preventieve maatregelen van Reddit tegen scrapen, zoals IP-blokkeringen of accountschorsingen.
Dit zou kunnen duiden op de soepele houding van Reddit ten opzichte van scrapen. Maar er is nog steeds een kans dat uw scraper obstakels tegenkomt, zoals CAPTCHA, snelheidslimieten of schorsingen.
Maar als u AdsPower gebruikt, kunt u uw Reddit-scrapingtaken vol vertrouwen uitvoeren zonder dat u zich zorgen hoeft te maken dat u wordt gedetecteerd of geblokkeerd.
Hoe AdsPower uw scrapingactiviteiten beveiligt:
- Vingerafdrukbeheer: Het browserprofiel van AdsPower isoleert uw activiteiten met behulp van aangepaste vingerafdrukken. U hoeft alleen de scrapingtools in de AdsPower-browser uit te voeren, waardoor het voor Reddit veel moeilijker wordt om geautomatiseerd scrapen te detecteren.
- Proxy-integratie: U kunt proxy's integreren met AdsPower om uw verzoeken via verschillende IP-adressen te routeren, waardoor uw anonimiteit verder wordt beschermd en de kans wordt verkleind dat u wordt geblokkeerd door het IP-detectiesysteem van Reddit.
Nu weet je hoe je Reddit kunt scrapen met en zonder codering,Meld je gratis aan voor AdsPower en scrap nuttige subreddits zonder onderbrekingen.
Als je naast Reddit ook geïnteresseerd bent in het scrapen van andere platforms, zoals Walmart, Instagram, TikTok, eBay, Reddit, Facebook en Twitter, klik gerust en ontdek onze uitgebreide handleidingen die speciaal voor elk platform zijn ontwikkeld!

Mensen lezen ook
- Top 12 games die niet door school geblokkeerd worden (+ eenvoudige oplossingen)

Top 12 games die niet door school geblokkeerd worden (+ eenvoudige oplossingen)
Ontdek 12 gratis, niet-geblokkeerde games voor school en leer praktische manieren om toegang te krijgen tot geblokkeerde gamesites.
- Hoe je in 2026 meerdere Apple-accounts veilig kunt beheren

Hoe je in 2026 meerdere Apple-accounts veilig kunt beheren
Leer hoe je meerdere Apple-accounts veilig beheert met praktische tips.
- Hoe verdien je geld met Substack in 2026: Inkomstenstrategieën voor contentmakers

Hoe verdien je geld met Substack in 2026: Inkomstenstrategieën voor contentmakers
Wil je geld verdienen met Substack? Deze gids legt bewezen methoden voor het genereren van inkomsten uit content uit, geeft tips voor groei en laat zien hoe contentmakers inkomsten genereren.
- Is Claude offline of niet bereikbaar? Zo kunt u veelvoorkomende problemen diagnosticeren en oplossen.

Is Claude offline of niet bereikbaar? Zo kunt u veelvoorkomende problemen diagnosticeren en oplossen.
Is Claude niet bereikbaar, of krijg je foutmeldingen zoals "Claude niet te bereiken"? Leer hoe je inlogproblemen, authenticatiefouten, netwerkproblemen en meer kunt oplossen.
- Is je Instagram-account eerst geblokkeerd en daarna verbannen? Zo krijg je het terug.

Is je Instagram-account eerst geblokkeerd en daarna verbannen? Zo krijg je het terug.
Is je Instagram-account geblokkeerd en vervolgens verbannen? Deze handleiding legt uit wat je moet doen en hoe je een tijdelijk geblokkeerd of uitgeschakeld account kunt herstellen.
