
How to Scrape Facebook: 2 Easy Methods for Coders & Non-Coders
Take a Quick Look
Want to scrape Facebook without coding? Tools like Bardeen make it easy! For a more hands-on approach, try Python scripts. Either way, AdsPower has your back, helping you dodge Facebook's anti-scraping blocks. Ready to start scraping?
The more users, the more data the platform has to offer. And with over 3B+ users, Facebook is the largest social media platform out there.

What does this mean for businesses? It's a goldmine to get customer/client insights, right? But how to scrape Facebook? Can someone with no coding experience or knowledge do it?
The answer is yes, and this is what today's blog is going to be about. You'll discover two methods on how to scrape Facebook, one that requires no coding experience and the other requiring a working knowledge of programming. Let's get scraping, shall we?
Understanding Facebook Scraping and its Limitations
Web scraping Facebook is the process of automatically collecting data from Facebook using web crawlers or scraping tools. It involves the collection of publicly available information, such as:
-
User posts
-
Comments
-
Likes
-
Followers
-
Hashtags
-
Etc
Scraping Facebook serves various purposes, including market analysis, customer sentiment analysis, brand monitoring, and competitive research.
Typically, people scrape Facebook either using a no-code Facebook data scraper or a coding script. Most of these techniques also let them convert the data into a structured format like JSON, Excel, or CSV for easier analysis.
However, before asking how to scrape Facebook, you should know the legal considerations associated with scraping Facebook.
Facebook does not allow the scraping of its data through automated means such as bots, robots, spiders, or scrapers without its explicit consent. Violating these terms can result in a ban and legal action.
Additionally, Facebook has a separate page for Terms of Service (TOS) regarding automated scraping, which covers the issue thoroughly.
However, using an anti-detect browser can help you bypass the limitations. We'll talk about how you can leverage it, but before that, let's understand the scraping process.
How to Scrape Data from Facebook?
Scraping Facebook can be tricky, yet it's achievable. Here are 2 methods to hit the ball rolling:
How to Scrape Facebook Using No-Code Scraper?
Not everyone is comfortable with coding or has the time to learn complex programming just for the sake of scraping Facebook. If you are also one of those, then this method is tailor-made for you.
Thankfully, the evolution of no-code tools has made the process of scraping Facebook extremely easy and accessible to all skill levels. Bardeen is one such Facebook scraper. It comes as a Chrome extension and provides 2 options, one where you can use their pre-built automations and the other which lets you customize your own scraper from scratch. 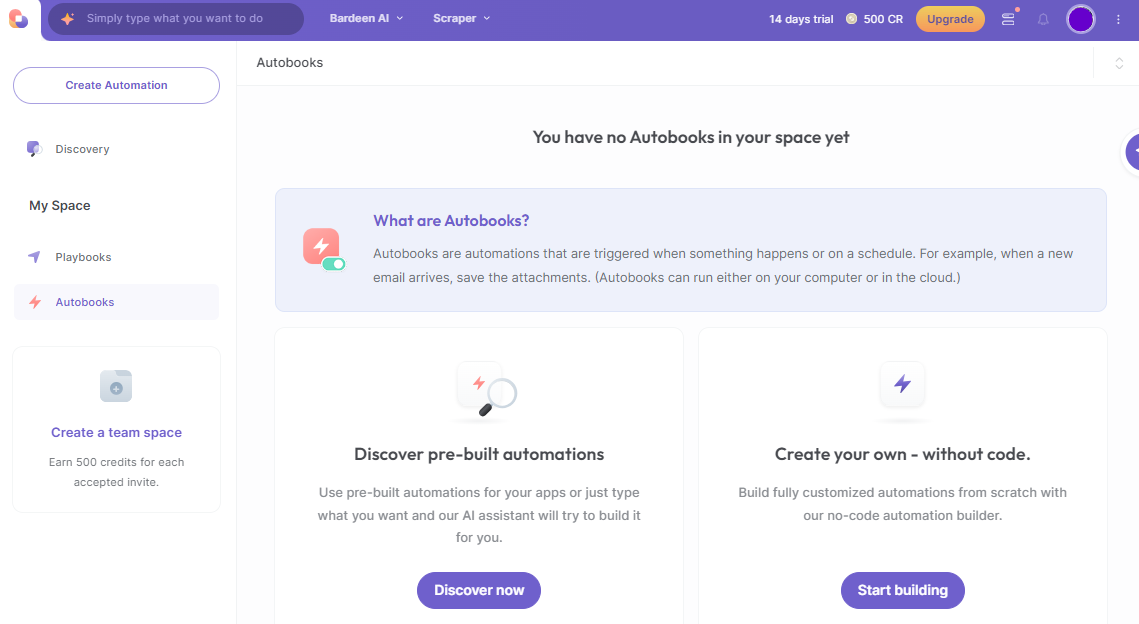
The Pre-built automations option lets you select from a list of templates for scraping different types of data. It may or may not have the template you are looking for.
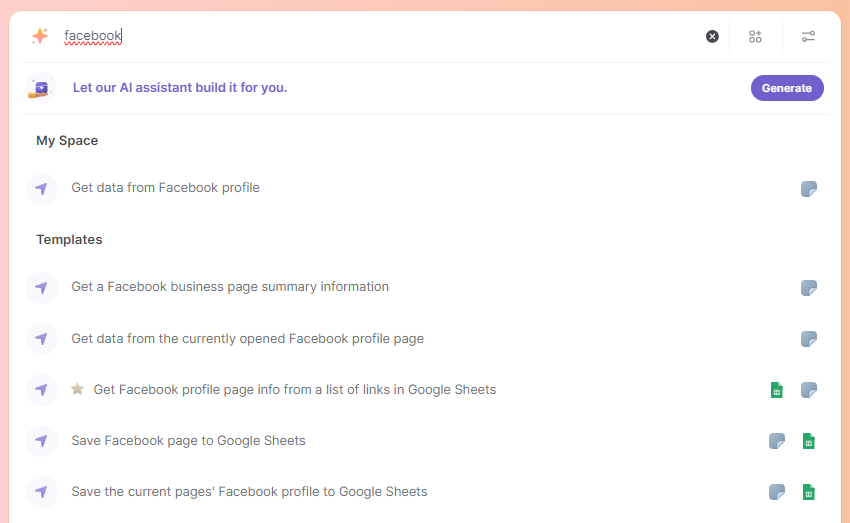
Let's say you want to scrape Facebook emails, and there's no template for it. You can simply build your own Facebook web scraper for that by choosing the 'Create your own' option.
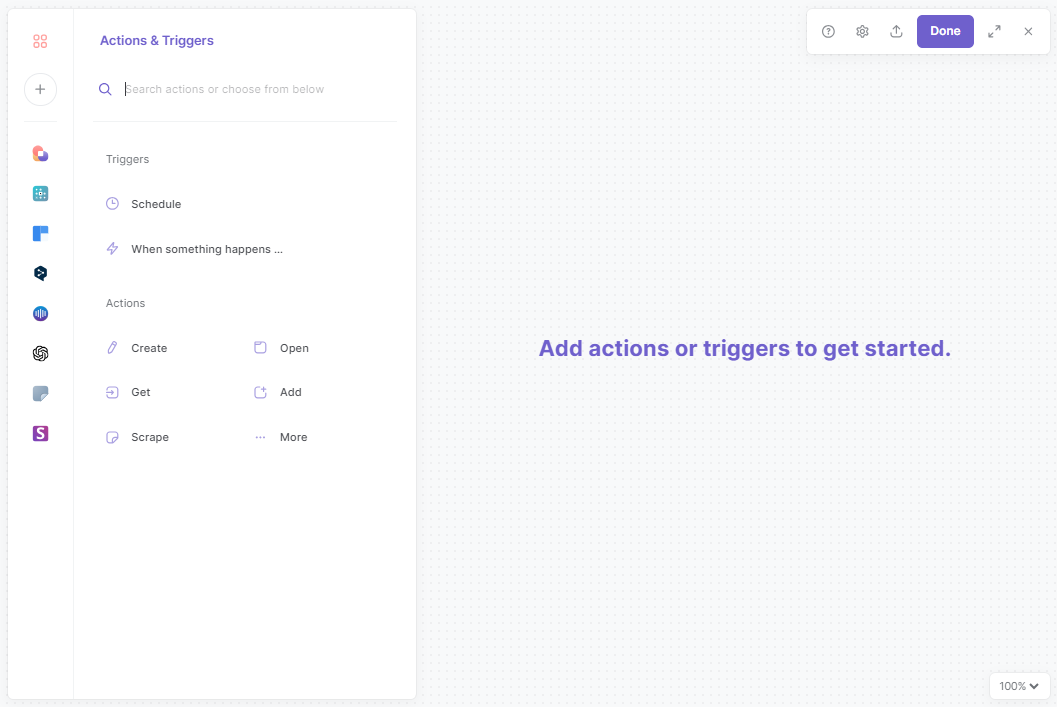
Here's how to scrape Facebook using different Pre-built Bardeen templates.
Step#1: Install Bardeen
Install Bardeen's Chrome extension from the Chrome Web store.
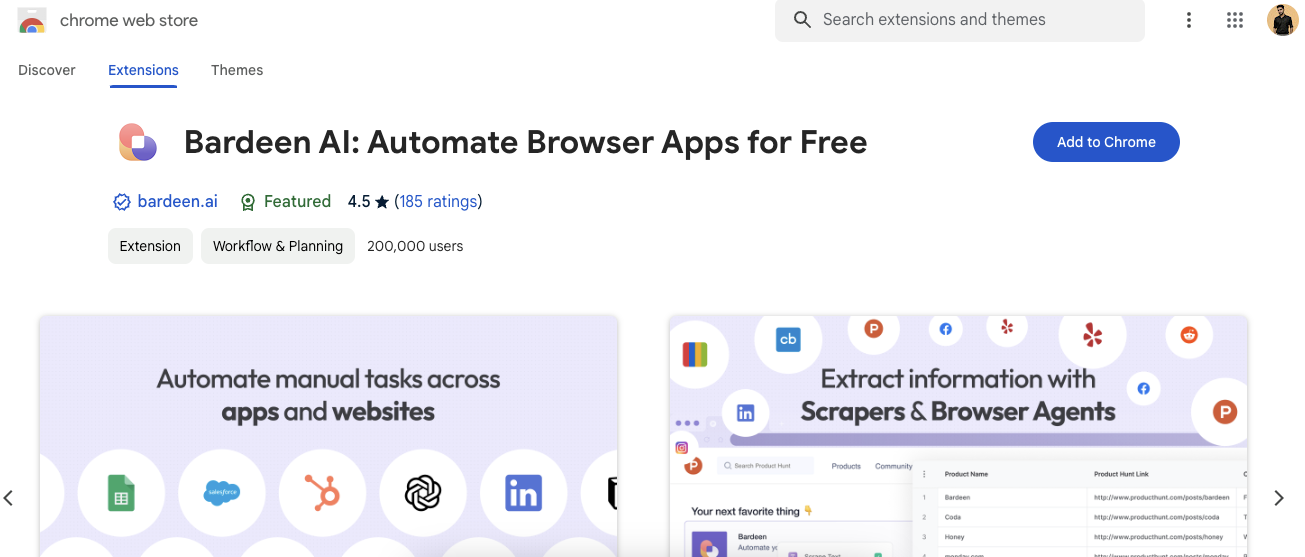
Step#2: Create an Account
Once Bardeen is installed, either create an account if you're a new user or log in using your account credentials.
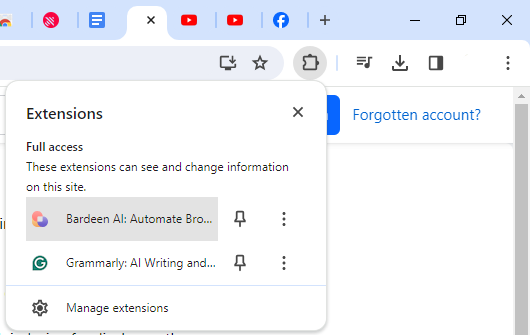
Step#3: Open Bardeen
On Chrome, open a new tab, and then open extensions. From the extensions menu, select Bardeen.
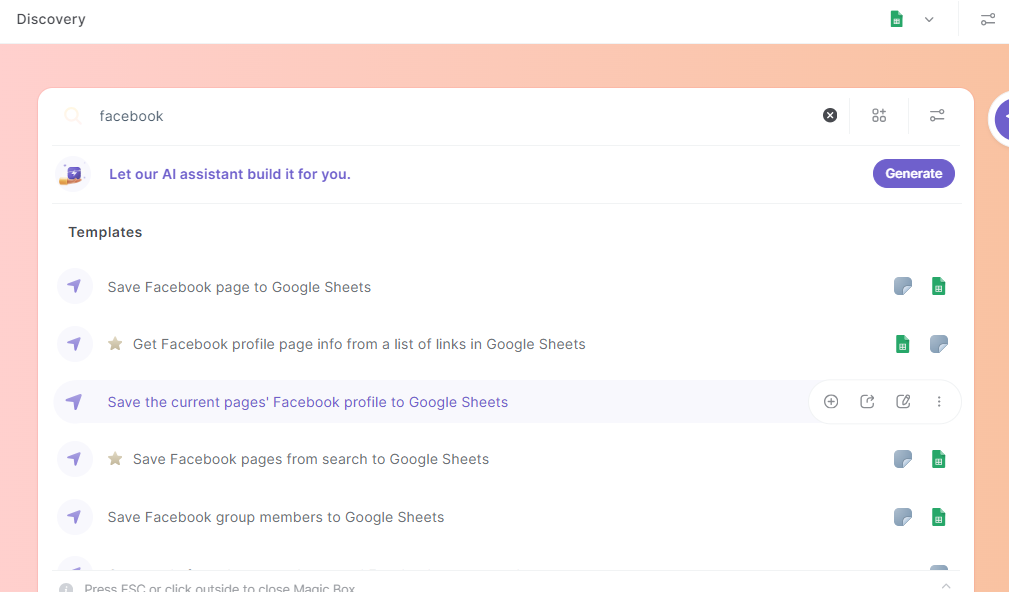
On the Bardeen window, open Autobooks from the left panel.
We will be using pre-built Facebook scraper templates, so press the Discover Now button. Type Facebook in the search bar, and all Facebook scrapers for extracting different data will show up.
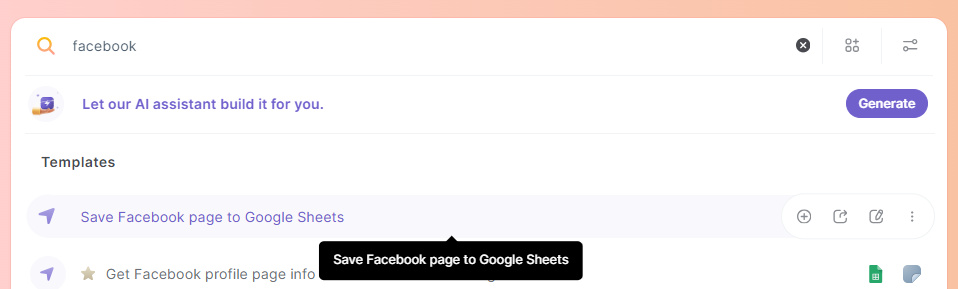
Step#4: Start Scraping
Let's scrape a Facebook page and save it to Google Sheets. Select the template shown in the screenshot below.
In the next window, type create in the search bar and select the option that appears.
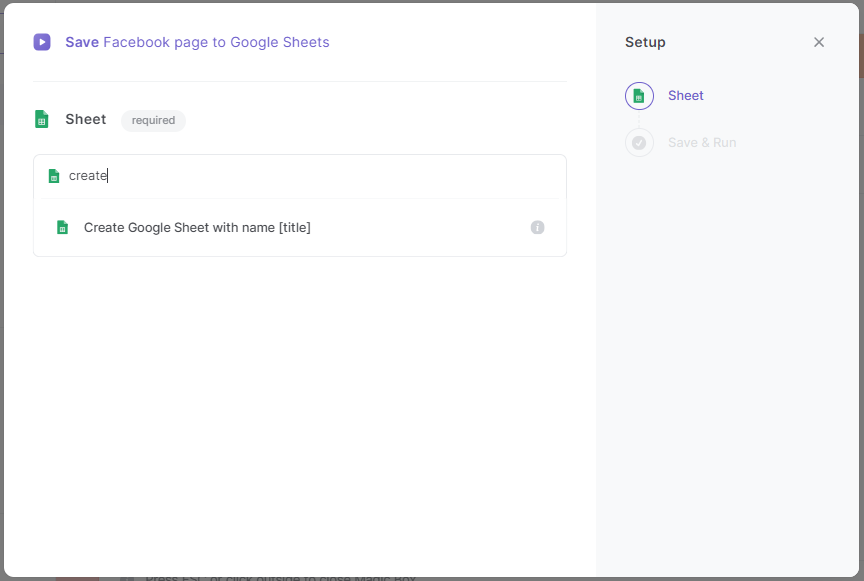
Now, name your Google Sheets file. We'd recommend naming the file after the type of scraping you're performing, for example, "Scrape Facebook Page." After typing the name, press enter.
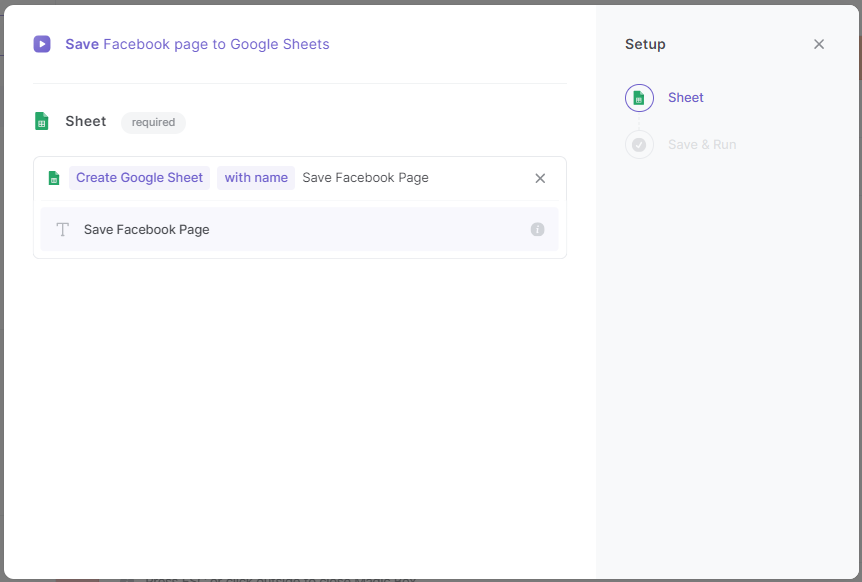
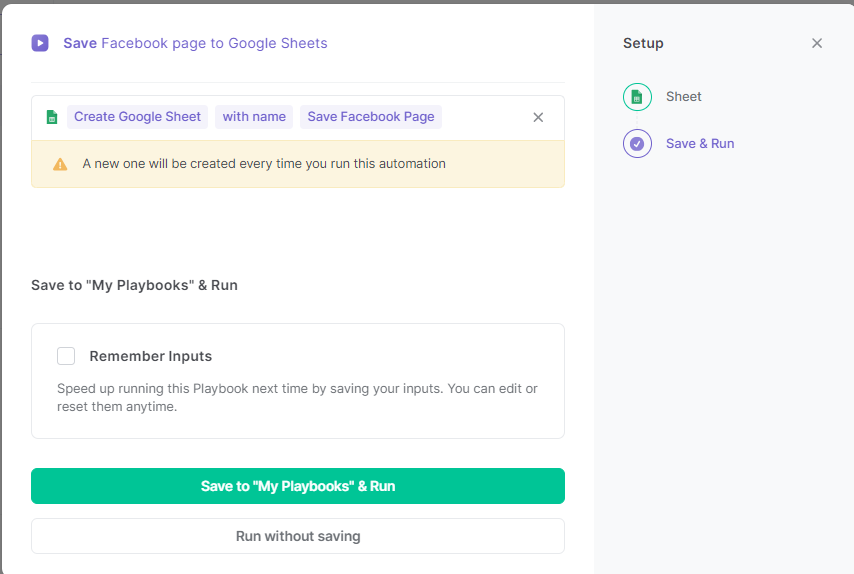
Start the scraping process by pressing any of the two buttons that appear.
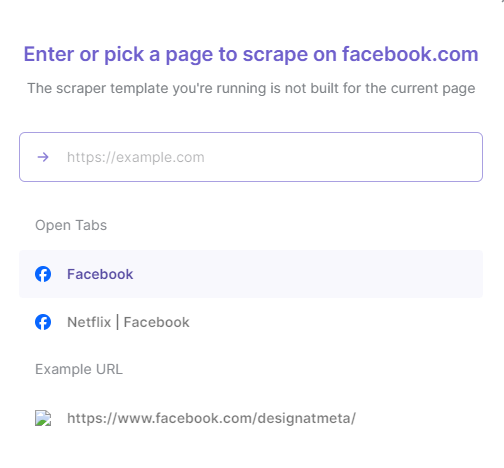
The next window will give you two options. Either paste the target Facebook page's URL or select from a list of opened Facebook tabs. So make sure the Facebook page you want to scrape is already opened in the browser if you're going for the second option.
Select the one where your target Facebook page is opened. In our case, we chose Netflix.
A popup window will appear containing a progress bar to show the progress of the scraping task.
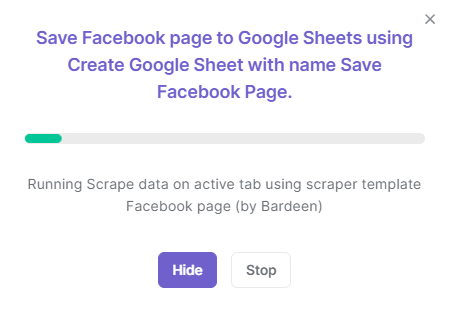
The task may take a few seconds to a few minutes, depending on the quantity of data. After completion, you'll be able to view the Google Sheet file or download the data as a CSV.
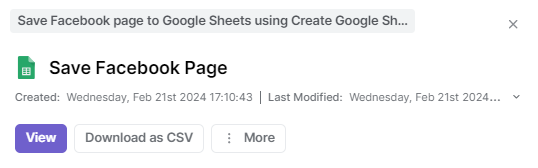
This was just one template. Other templates also have similar steps and scrape Facebook data in no time. Or, if these templates don't fulfill your requirements, build your own custom scraper using the 'Create Your Own' option.
How to Scrape Facebook Using Python?
Scraping Facebook through coding is easier than you might think, thanks to a handy Python library called Facebook-page-scraper.
As the name suggests, it's built to scrape Facebook page.
The library has pre-built functions and algorithms necessary for scraping Facebook pages. Plus, you don't have to worry about hitting any limits on how much data you can collect, and you don't need to sign up for anything or have a special API key to use it.
To make sure you don't run into any trouble with Facebook trying to stop or block you, you'll need two things: a proxy server and a headless browser library.
A proxy server hides where you're really connecting from, so Facebook doesn't realize it's you trying to collect lots of data. This is super important because Facebook tries to block or limit anyone it catches trying to scrape data from Facebook.
The headless browser lets you load dynamic Facebook content, like comments or posts that appear as you navigate any web page. Plus, it tricks Facebook into thinking a real person is browsing, not a robot, which helps avoid getting blocked.
Here's how to scrape Facebook using the Facebook page scraper library:
Step 1:
First, you need to install Python on your computer and JSON library, which helps us organize the data we collect.
Next, you'll install the Facebook-page-scraper. Open up your computer's terminal or command prompt and type this command:
Step 2:
Start by adding the scraper to your Python script.
Step 3:
Next, decide which Facebook pages you're interested in. Make a list of these pages in your code, like this:
Step 4:
Now, we'll write code that'll help us stay under the radar with proxies and load dynamic pages.
-
Proxy: You'll need to set a number for the proxy port.
-
How much to scrape: Decide how many posts you want to grab from each page. Maybe 100 posts is a good start.
-
Choosing a browser: You can use tools like Google Chrome or Firefox to do the scraping. Pick the one you like.
-
Timeout: Set a time limit for how long the scraper should try to collect data before taking a break. This is measured in seconds. 600 seconds (or 10 minutes) is a good default.
-
Headless browser: Choose whether you want to watch the scraper work (set to False) or let it run quietly in the background (set to True). If you're curious, you might start with it visible.
With these steps, your Python Facebook scraper is ready to go.
Step 5:
Before we kick off, if your proxy service needs a login, you'll need to add your username and password into the mix.
Here's how you set it up for each Facebook page you want to scrape:
Step 6:
Once the scraper is up and running, you'll decide how to view the results. There are two main ways to do this:
-
Option 1: For a quick look, you can have the scraper show you the results right in the console. This method is great for a fast check.
-
Option 2: If you're collecting a lot of data and want to organize it, you can save it to a CSV file. First, pick a place on your computer to store the results, like making a new folder.
Step 7:
Lastly, don't forget to change your proxy port after each scraping session to keep things smooth and avoid any trouble with IP bans.
Voilà! that's your quick guide on how to scrape Facebook page. For more specific data, the web offers tools like Facebook Marketplace Scraper for targeted market insights and Facebook email scraper for extracting contact details.
Use AdsPower for Secure Facebook Scraping
According to Facebook's ToS, scraping Facebook through automated means is a Big No. Facebook also actively keeps updating its scraping countermeasures to make the process even harder. You can lose your account in the crossfire, as this Reddit user warns.
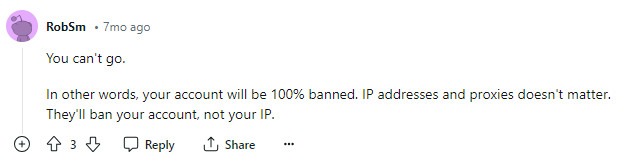
But there's still a way out. With anti-detect Browsers like AdsPower, anti-scraping measures are a non-issue.
By creating unique, customizable fingerprints for each session, AdsPower isolates your activities, making it harder for Facebook to detect automated scraping. It allows you to use scraping tools like Bardeen or Python scripts securely while avoiding account bans or blocks. Whether you're using a no-code Facebook scraper or a Python Facebook scraping library, AdsPower equips you with the necessary features to bypass these restrictions.
We hope this blog has provided you with all the necessary information on how to scrape Facebook. Happy Scraping!
In addition to Facebook, if you're also interested in scraping other platforms such as Instagram, TikTok, eBay, Reddit, Walmart, and Twitter, feel free to click and explore our comprehensive guides tailored for each platform!

People Also Read
- Can You View Instagram Stories Anonymously? A Complete 2026 Guide

Can You View Instagram Stories Anonymously? A Complete 2026 Guide
Learn how to view Instagram Stories anonymously in 2026 and discover the best method for your privacy and browsing needs.
- Can You Have Multiple Polymarket Accounts? Rules, Risks & Best Practices (2026)

Can You Have Multiple Polymarket Accounts? Rules, Risks & Best Practices (2026)
This guide explains Polymarket's rules on multiple accounts, the potential risks involved, and best practices for managing them safely and efficiently
- Top 12 Games Not Blocked by School (+ Easy Fixes)

Top 12 Games Not Blocked by School (+ Easy Fixes)
Discover 12 free unblocked games for school, learn practical ways to access blocked game sites
- How to Make Money on Substack 2026: Revenue Strategies for Creators

How to Make Money on Substack 2026: Revenue Strategies for Creators
Want to make money on Substack? This guide breaks down proven monetization methods, growth tips, and how creators turn content into income.
- Claude Down or Can't Reach Claude? How to Diagnose and Fix Common Issues

Claude Down or Can't Reach Claude? How to Diagnose and Fix Common Issues
Is Claude down, or are you seeing "Can't reach Claude" errors? Learn how to fix login loops, authentication errors, network issues, and more.
