
10 najlepszych przeglądarek bezgłowych do scrapowania stron internetowych: zalety i wady
Rzuć okiem
Chcesz udoskonalić swoje scrapowanie stron internetowych? Przeglądarki bez interfejsu graficznego to Twoja tajna broń. Dowiedz się, jak działają, dlaczego są niesamowite i które z nich przeniosą Twoje scrapowanie na wyższy poziom.
Czy kiedykolwiek musiałeś wydajnie wyodrębnić duże ilości danych online, a tradycyjne przeglądarki Cię spowalniały? Od śledzenia cen po analizę konkurencji, web scraping jest kluczowy w automatyzacji gromadzenia danych. Jednak korzystanie ze zwykłej przeglądarki do scrapingu może być powolne i nieefektywne. Kiedy liczy się szybkość i automatyzacja, jakie jest najlepsze rozwiązanie?
W tym przewodniku przyjrzymy się 10 najlepszym przeglądarkom bezgłowym do web scrapingu, omawiając ich mocne i słabe strony, aby pomóc Ci wybrać odpowiednie narzędzie do Twoich potrzeb.
Co to jest przeglądarka bez interfejsu graficznego?
Mówiąc wprost, przeglądarka bezgłowa to przeglądarka internetowa bez graficznego interfejsu użytkownika (GUI). Działa w tle, pobierając i renderując strony internetowe tak jak zwykła przeglądarka, ale bez wyświetlania ich na ekranie. Dzięki temu przeglądarki bezgłowe idealnie nadają się do zadań takich jak web scraping, automatyczne testowanie i monitorowanie wydajności.
Nawiasem mówiąc, tryb bezgłowy przeglądarki z funkcją antywykrywania, takiej jak AdsPower, oferuje podobne możliwości jak tradycyjne przeglądarki bezgłowe, ale z ulepszonym mechanizmem ukrywania się. Podczas gdy tradycyjne przeglądarki bezgłowe często są oznaczane flagą z powodu brakujących odcisków palców, tryb bezgłowy AdsPower pomaga ominąć wykrycie poprzez maskowanie i modyfikowanie cyfrowych odcisków palców, dzięki czemu Twoje żądania wyglądają, jakby pochodziły od unikalnych, legalnych użytkowników.
| Przypadek użycia | Tryb bezgłowy AdsPower | Tradycyjny tryb bezgłowy przeglądarki |
| Zarządzanie wieloma kontami | ✅ Tak | ❌ Nie |
| Omijanie wykrywania botów | ✅ Tak | ❌ Nie |
Jak uruchomić AdsPower w trybie bezgłowym?
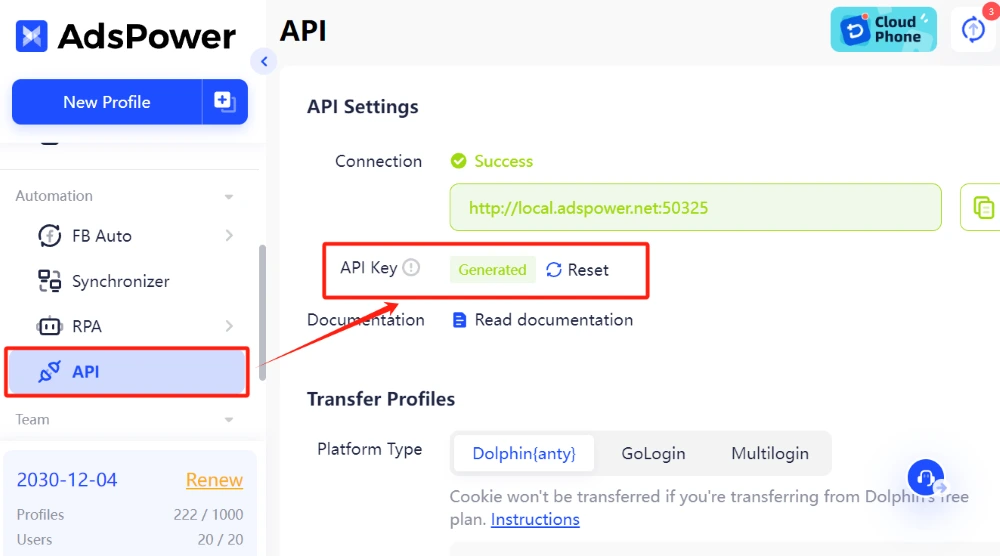
1. Przejdź do Ustawień API w AdsPower i kliknij Generuj lub Resetuj , aby uzyskać klucz API.
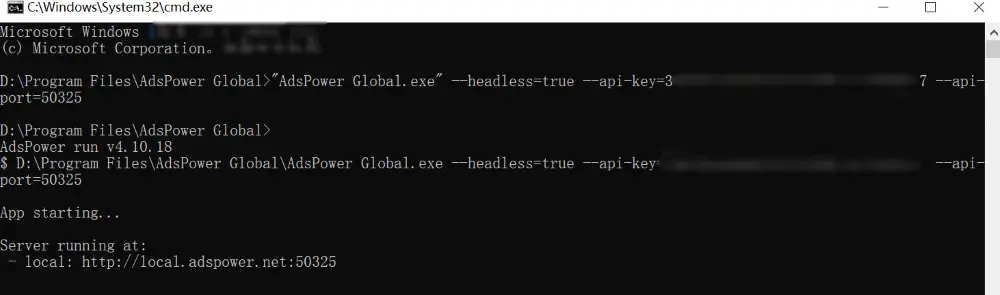
2. Uruchom AdsPower w trybie bezgłowym (Otwórz CMD lub Terminal w katalogu głównym AdsPower)
- Windows: "AdsPower Global.exe" --headless=true --api-key=XXXX --api-port=50325
- macOS: "/Applications/AdsPower Global.app/Contents/MacOS/AdsPower Global" --args --headless=true --api-key=XXXX --api-port=50325
- Linux: adspower_global --headless=true --api-key=XXX --api-port=50325
3. Sprawdź adres zwrotny w wierszu poleceń, aby potwierdzić pomyślne uruchomienie.
Pełny przewodnik: Dokumentacja interfejsu API AdsPower — tryb bezgłowy
Czym przeglądarki bezgłowe różnią się od zwykłych przeglądarek?
Pomyśl o tym w ten sposób: podczas gdy zwykłe przeglądarki są zaprojektowane z myślą o interakcji z człowiekiem – z przyciskami do klikania, stronami do przewijania i obrazami do podziwiania – przeglądarki bezgłowe pozbawiają się elementów wizualnych. Koncentrują się wyłącznie na funkcjonalności, umożliwiając programową interakcję ze stronami internetowymi. Istnieją kluczowe różnice, które sprawiają, że przeglądarki bezgłowe są szczególnie przydatne do zadań automatyzacji:
- Brak graficznego interfejsu użytkownika: Przeglądarki bezgłowe działają bez wizualnego wyświetlania strony internetowej, co jest korzystne dla środowisk serwerowych, ponieważ zmniejsza obciążenie obliczeniowe i zużycie zasobów. Brak wizualnego wsparcia może jednak utrudniać rozwiązywanie problemów, ponieważ nie ma wizualnych wskazówek, które pomogłyby w diagnozowaniu problemów.
- Prędkość i wydajność: Przeglądarki headless, bez konieczności renderowania komponentów wizualnych, mogą ładować i przetwarzać strony szybciej. Dzięki temu idealnie nadają się do pozyskiwania dużych ilości danych lub przeprowadzania zautomatyzowanych testów na dużą skalę.
- Gotowe do automatyzacji: Przeglądarki headless są tworzone z myślą o automatyzacji. Wiele z nich udostępnia interfejsy API lub struktury umożliwiające programistom symulowanie działań użytkownika, takich jak klikanie przycisków, wypełnianie formularzy czy nawigowanie po stronach.
- Skalowalność: Ponieważ są lekkie, można uruchomić wiele instancji przeglądarek bezgłowych jednocześnie, co czyni je idealnymi do zadań wymagających skalowalności, takich jak scrapowanie tysięcy stron.
10 najlepszych przeglądarek bez interfejsu graficznego do scrapowania stron internetowych
Jeśli chodzi o scraping stron internetowych, nie wszystkie przeglądarki bez interfejsu graficznego są sobie równe. Oto najważniejsze opcje, które warto rozważyć, aby uzyskać wydajne i skalowalne gromadzenie danych:
1. Puppeteer
Puppeteer to biblioteka JavaScript zapewniająca wysoki poziom API umożliwiające sterowanie przeglądarkami Chrome i Firefox za pośrednictwem protokołu DevTools lub WebDriver BiDi. Idealnie nadaje się do obsługi witryn intensywnie korzystających z JavaScript lub wykonywania złożonych zadań automatyzacji przeglądarki.
-
Obsługiwane języki: JavaScript, TypeScript, Python,.NET, Java
| Zalety | Wady |
| Zaawansowany interfejs API do automatyzacji przeglądarki Chrome | Ograniczone do przeglądarek opartych na Chromium |
| Obsługuje zaawansowane interakcje, takie jak klikanie przycisków, robienie zrzutów ekranu i wykonywanie kodu JavaScript. | Wymaga środowiska Node.js |
| Aktywna społeczność i regularne aktualizacje | Brak wbudowanej obsługi wielu przeglądarek |
2. Dramaturg

Dramaturg, Stworzony przez Microsoft, jest potężną alternatywą dla Puppeteer. Obsługuje wiele przeglądarek, w tym Chromium, Firefox i WebKit, co czyni go wszechstronnym narzędziem do scrapowania stron internetowych.
- Obsługiwane języki: JavaScript, TypeScript, Python,.NET, Java.
| Zalety | Wady |
| Wbudowane funkcje przechwytywania sieci | Bardziej wymagający proces nauki dla nowicjuszy |
| Wbudowana emulacja mobilna | Wymaga więcej konfiguracji w porównaniu do Puppeteer |
| Potężny mechanizm automatycznego oczekiwania | Mniej integracji z rozwiązaniami innych firm niż w przypadku Selenium |
3. Selen
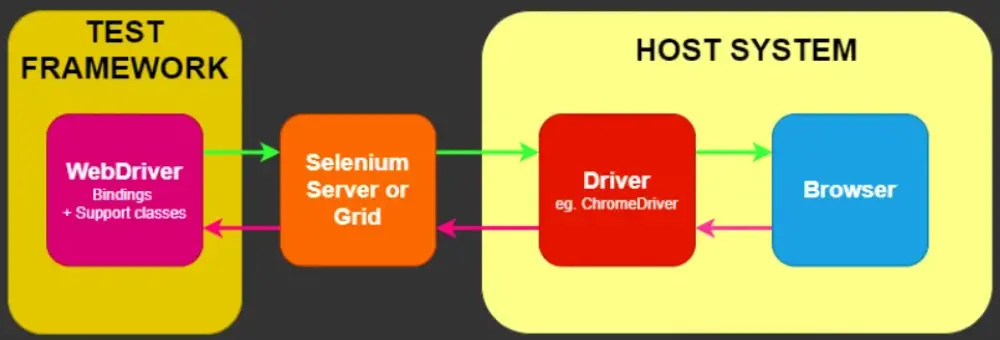
Selen to potężny framework automatyzacji przeglądarek, który integruje różne narzędzia i biblioteki do automatyzacji stron internetowych. Zaprojektowany zgodnie ze specyfikacją W3C WebDriver, oferuje wielojęzykowe API kompatybilne ze wszystkimi głównymi przeglądarkami internetowymi. Choć znany jest przede wszystkim z automatycznego testowania, tryb bezgłowy sprawia, że jest doskonałym wyborem do scrapowania stron internetowych, zwłaszcza w przypadku zadań obejmujących przesyłanie formularzy i złożone interakcje użytkowników.
- Obsługiwane języki: Python, Java, C#, Ruby, JavaScript.
| Zalety | Wady |
| Obsługuje wiele przeglądarek (Chrome, Firefox, Safari, Edge) | Wolniejszy niż Puppeteer lub Playwright |
| Duża społeczność i obszerna dokumentacja | Większe zużycie zasobów |
| Szeroko uznawane w branży | Wymaga zewnętrznych sterowników (np. GeckoDriver, ChromeDriver) |
4. Przeglądarka Bright Data Scraping
Bright Data Scraping Browser to wydajna, bezgłowa przeglądarka klasy korporacyjnej przeznaczona do scrapowania stron internetowych na dużą skalę. Oferuje wbudowane zarządzanie proxy, zaawansowane omijanie wykrywania botów oraz narzędzia automatyzacji usprawniające gromadzenie danych. Dzięki temu jest doskonałym wyborem dla firm potrzebujących niezawodnych i wydajnych rozwiązań do scrapowania stron internetowych.
- Obsługiwane języki: Python, Node.js (JavaScript) i Java/C#
| Zalety | Wady |
| Zaawansowane omijanie zabezpieczeń antybotowych | Usługa płatna |
| Zintegrowana obsługa proxy | Wymaga instalacji i konfiguracji |
| Zoptymalizowany pod kątem scrapowania na dużą skalę | Nie jest to oprogramowanie typu open source |
5. Headless Chrome
Headless Chrome to nie niezależna przeglądarka, a raczej tryb Google Chrome działający bez graficznego interfejsu. Jako część Google Chrome, jest to jedno z najpopularniejszych narzędzi do web scrapingu. Jest niezawodny, szybki i łatwy w konfiguracji.
- Obsługiwane języki: JavaScript, Python (za pośrednictwem Puppeteer lub Selenium), Java, C#, Ruby, Go i . NET.
| Zalety | Wady |
| Szybkie i niezawodne | Ograniczone do scrapowania w Chrome |
| Bezpośrednie wsparcie Google | Wymaga ręcznej konfiguracji dla zaawansowanych funkcji |
| Obsługuje wiele języków za pośrednictwem bibliotek zewnętrznych | Może być zasobochłonny w przypadku operacji na dużą skalę |
6. Headless Firefox
Headless Firefox to tryb przeglądarki Mozilla Firefox, który działa bez graficznego interfejsu użytkownika, umożliwiając zautomatyzowaną interakcję ze stronami internetowymi za pomocą skryptów. Podobnie jak Headless Chrome, jest szeroko stosowany do web scrapingu, automatycznego testowania i automatyzacji przeglądarek. Można nim sterować za pomocą Selenium, SlimmerJS i W3C WebDriver. To potężne narzędzie dla programistów pracujących nad projektami internetowymi.
- Obsługiwane języki: JavaScript, Python (za pośrednictwem Selenium).
| Zalety | Wady |
| Działa z silnikiem Gecko przeglądarki Firefox | Wolniejsze niż przeglądarki bezgłowe oparte na Chrome |
| Obsługuje wykonywanie JavaScript | Wymaga dodatkowej konfiguracji |
| Podobna funkcjonalność do Headless Chrome | Mniej popularne niż inne narzędzia |
7. chromedp
Chromedp to szybszy i prostszy sposób na obsługę przeglądarek Protokół Chrome DevTools w języku Go bez zewnętrznych zależności. Jest to doskonały wybór do lekkich zadań scrapowania i automatyzacji. Jednak brak obsługi wielu przeglądarek ogranicza jego elastyczność dla niektórych użytkowników.
- Obsługiwane języki: Go.
| Zalety | Wady |
| Natywna implementacja Go | Ograniczone do scrapowania w oparciu o Chrome |
| Lekki i wydajny | Wymagana znajomość programowania w Go |
| Minimalne zależności | Brak obsługi wielu przeglądarek |
8. Cypress
Cypress to przede wszystkim framework do testowania, ale w określonych scenariuszach może być również używany do scrapowania stron internetowych. Oferuje wbudowaną automatyzację, debugowanie w czasie rzeczywistym oraz zaawansowane API do interakcji ze stronami internetowymi. Nie jest jednak zoptymalizowana pod kątem scrapowania na dużą skalę, tak jak niektóre inne przeglądarki bezgłowe.
- Obsługiwane języki: JavaScript.
| Zalety | Wady |
| Łatwe w użyciu środowisko testowe | Nie jest przeznaczone do scrapowania na dużą skalę |
| Wbudowane mechanizmy oczekiwania i ponawiania | Ograniczona obsługa przeglądarek (opartych na Chrome) |
| Silne możliwości debugowania | Wymaga interfejsu graficznego dla niektórych interakcji |
9. Zombie.js
Zombie.js to lekki, zgodny z Node.js framework do automatycznego testowania JavaScript po stronie klienta. Idealny do podstawowego scrapowania stron internetowych, zawiera kompleksowy interfejs API z wbudowaną obsługą plików cookie, kart, uwierzytelniania i asercji, zapewniając wydajne i solidne scenariusze testowe.
- Obsługiwane języki: JavaScript.
| Zalety | Wady |
| W pełni funkcjonalny interfejs API | Przestarzały i mniej aktywny rozwój w ostatnich latach |
| Lekkość i szybkość | Ograniczone funkcje przeglądarki |
| Integracja z projektami Node.js | Nieodpowiednie w scenariuszach wymagających rzeczywistego renderowania w przeglądarce |
10. Jednostka HTML
HtmlUnit to oparta na Javie przeglądarka bez interfejsu graficznego, która umożliwia zaawansowaną interakcję ze stronami internetowymi za pośrednictwem aplikacji Java. Umożliwia ona takie zadania, jak przesyłanie formularzy, nawigacja po hiperłączach oraz szczegółowy dostęp do zawartości i struktury stron internetowych, umożliwiając kompleksową manipulację stronami internetowymi i ich analizę.
- Obsługiwane języki: Java.
| Zalety | Wady |
| Lekki i szybki | Ograniczone wsparcie JavaScript |
| Ciągłe udoskonalanie | Mniej aktywna społeczność |
| Obsługuje złożone biblioteki AJAX; symuluje Chrome, Firefox lub Edge w zależności od konfiguracji | Mogą wystąpić trudności z obsługą nowoczesnych witryn internetowych z intensywnym wykonywaniem kodu JavaScript |
Najczęściej zadawane pytania
1. Jak kontrolować przeglądarkę bez interfejsu graficznego na potrzeby testowania i web scrapingu?
Kontrolowanie przeglądarki bez interfejsu graficznego zwykle wiąże się z użyciem interfejsów API lub struktur. Na przykład:
- Puppeteer: Użyj biblioteki Node.js do tworzenia skryptów interakcji, takich jak nawigacja po stronach i wyodrębnianie danych.
- Selenium: Twórz skrypty w preferowanym języku programowania, aby automatyzować działania przeglądarki.
- Autor: Skorzystaj z obsługi wielu przeglądarek, aby poradzić sobie ze złożonymi scenariuszami.
2. Jaka jest najlepsza lekka przeglądarka bez interfejsu graficznego?
Jeśli priorytetem jest dla Ciebie szybkość i wydajność zasobów, rozważ użycie Headless Chrome lub PhantomJS. Chociaż przeglądarka Headless Chrome jest aktywnie rozwijana i obsługuje nowoczesne standardy internetowe, PhantomJS nadal jest przydatny do podstawowych zadań.
3. Czy przeglądarka odcisków palców (tryb bez interfejsu graficznego) może być używana jako prawdziwa przeglądarka bez interfejsu graficznego?
Przeglądarka odcisków palców w trybie bezgłowym oferuje podobne funkcjonalności jak tradycyjna przeglądarka bezgłowa, ale nie jest do końca taka sama. Chociaż umożliwia automatyczne przeglądanie bez widocznego interfejsu użytkownika, zachowuje i modyfikuje odciski palców, aby zmniejszyć ryzyko wykrycia. Jednak niektóre zaawansowane funkcje automatyzacji dostępne w tradycyjnych przeglądarkach bezgłowych mogą nie być w pełni obsługiwane.
Podsumowanie
Przeglądarki bezgłowe to niezbędne narzędzia do web scrapingu, oferujące szybkość, wydajność i skalowalność. Niezależnie od tego, czy jesteś początkującym, czy doświadczonym programistą, wybór odpowiedniej przeglądarki headless może znacząco wpłynąć na Twoje projekty scrapingowe. W przypadku scrapowania stron internetowych na dużą skalę, połączenie przeglądarki headless z AdsPower może pomóc Ci uniknąć wykrycia poprzez maskowanie cyfrowych odcisków palców, zapewniając płynniejszą automatyzację. Wypróbuj AdsPower za darmo już dziś i przenieś swoją wydajność scrapowania na wyższy poziom!

Ludzie czytają także
- 12 najlepszych gier, których nie blokuje szkoła (+ proste rozwiązania)

12 najlepszych gier, których nie blokuje szkoła (+ proste rozwiązania)
Odkryj 12 darmowych, odblokowanych gier do szkoły i poznaj praktyczne sposoby uzyskiwania dostępu do zablokowanych witryn z grami
- Jak bezpiecznie zarządzać wieloma kontami Apple w 2026 roku

Jak bezpiecznie zarządzać wieloma kontami Apple w 2026 roku
Dowiedz się, jak bezpiecznie zarządzać wieloma kontami Apple, korzystając z praktycznych wskazówek
- Jak zarabiać na Substacku w 2026 roku: strategie generowania przychodów dla twórców

Jak zarabiać na Substacku w 2026 roku: strategie generowania przychodów dla twórców
Chcesz zarabiać na Substacku? Ten poradnik przedstawia sprawdzone metody monetyzacji, wskazówki dotyczące rozwoju i sposoby, w jakie twórcy przekształcają treści w dochód.
- Claude nie działa lub nie można się z nim skontaktować? Jak zdiagnozować i rozwiązać typowe problemy

Claude nie działa lub nie można się z nim skontaktować? Jak zdiagnozować i rozwiązać typowe problemy
Czy Claude jest niedostępny, czy też wyświetlają się błędy „Nie można się z nim skontaktować”? Dowiedz się, jak rozwiązać problemy z pętlami logowania, błędami uwierzytelniania, problemami z siecią i nie tylko.
- Instagram zablokowany, a potem zbanowany? Jak go odzyskać?

Instagram zablokowany, a potem zbanowany? Jak go odzyskać?
Instagram zablokował Twoje konto, a następnie je zablokował? Ten poradnik wyjaśnia, co zrobić i jak odzyskać tymczasowo zablokowane lub wyłączone konto.
