
Un ghid detaliat pentru utilizarea Amazon Scraper
Extragerea de date web de pe Amazon poate fi extrem de profitabilă pentru companii dacă este făcută inteligent. Nu ne credeți? Luați în considerareaceastă povestedespre un site web care a generat o sumă uluitoare de 800.000 de dolari în doar două luni, în timp ce tot ce au făcut a fost să adune zilnic recenzii de pe Amazon. Tare, nu-i așa?
Nu vă putem promite că veți face o grămadă de bani peste noapte, dar vă putem învăța cum să adunați date de pe Amazon pentru a încerca să ajungeți acolo.
Așadar, citiți acest blog pentru a afla două modalități de a aduna date de pe Amazon: una folosind un scraper Amazon fără cod și alta în care construim un scraper Amazon Python prin cod.
/>
Dar mai întâi, haideți să aflăm dacă este în regulă să extragi date de pe Amazon.
Este legal să extragi date de pe Amazon?
Când vine vorba de extragerea datelor de pe Amazon, regulile sunt puțin vagi. Amazon robots.txtdefinește parametrii permiși de extragere a datelor într-o listă lungă care specifică ce este posibil prin extragerea datelor și care zone sunt strict interzise.
Cu toate acestea, fișierul robots.txt servește doar ca ghid etic și nu este obligatoriu din punct de vedere juridic. Așadar, scraperul dvs. Amazon poate accesa zone inaccesibile fără a întâmpina neapărat probleme.
Cu toate acestea, Amazon nu se oprește aici. Merge mai departe prin implementarea de bariere tehnice pentru a împiedica boții să supraîncarce serverele sale.
De exemplu, folosește măsuri anti-scraping, cum ar fi testele CAPTCHA și limitarea ratei. Pentru a depăși aceste obstacole, scraperul dvs. Amazon trebuie să posede tehnici avansatecum ar fi spoofing-ul agentului utilizatorului,Rezolvarea CAPTCHA sau întârzierea solicitărilor; altfel, încercarea dvs. de a extrage informații de pe Amazon ar rămâne un vis.
Prin urmare, pentru a răspunde pe scurt„Permite Amazon extragerea datelor de pe web?”: legalitatea extragerii datelor de pe web de pe Amazon nu este clară și depinde de diverși factori, inclusiv
-
tipul de date extrase
-
metodele utilizate pentru extragere
-
și scopul datelor extrase
Atâta timp cât extragerea nu implică acces neautorizat, de exemplu, datele din spatele unei autentificări sau nu suprasolicită infrastructura site-ului, aceasta se încadrează de obicei în categoria „sigur”. Curtea Supremă a apărat, de asemenea,o firmă de Data Analytics care a fost dată în judecată de LinkedInîn temeiul CFAA, invocând extragerea neautorizată de date pe web.
Mai mult, ar trebui să vă asigurați că utilizarea datelor extrase este legală, adică nu le revindeți sau reproduceți, deoarece acest lucru poate avea repercusiuni legale grave.
Acum întrebarea de un milion de dolari, cum să extragi datele de pe Amazon?
Cum să extragi date de pe Amazon?
În ciuda provocărilor tehnice, este ușor să extragi date de pe Amazon. Există numeroase instrumente de cod și fără cod pe Amazon pentru extragerea datelor, cu soluții pentru abordarea măsurilor anti-boți ale Amazon. Puteți extrage cu ușurință recenzii, produse și prețuri de pe Amazon, printre alte date, folosind aceste instrumente.
Așadar, să începem mai întâi cu Amazon Scraper, fără cod.
Scraper Amazon fără cod:
Să fim sinceri, sunt șanse mari ca cititorul actual care citește acest lucru să nu aibă abilități de codare. Dar asta nu este o problemă. Nu aveți nevoie de cunoștințe de codare atunci când sunt disponibile scrapere Amazon fără cod.
Cu aceste instrumente, trebuie doar să furnizați adresele URL ale paginii produsului sau categoriei, iar scraperul vă va oferi tot conținutul Amazon datele despre produs de pe pagina respectivă. După ce au terminat de extras date web de pe Amazon, vi se oferă și mai multe opțiuni de salvare a fișierelor.
Am ales Amazon Scraper de la Apify pentru această demonstrație. Apify are instrumente separate pentru extragerea datelor de pe diferite zone ale Amazon, inclusiv Amazon Product Scraper, Amazon Review Scraper și Amazon Bestsellers Scraper.
În acest ghid, vom folosi Amazon Product Scraper de la Apify. Amazon Product Scraper are funcții pentru a rezolva CAPTCHA-uri și a seta proxy-uri pentru a ajuta la evitarea măsurilor anti-boți.
Așadar, haideți să începem demonstrația.
Pasul 1: Vizitați pagina de extragere a produselor Amazon
AccesațiAmazon Product Scraperîn Magazinul Apify și apăsați butonul „Încercați gratuit”. Acest instrument vă permite să extrageți date despre produsele Amazon, inclusiv prețuri, recenzii, descrieri ale produselor, imagini și multe alte atribute.
Pasul 2: Creați-vă contul Apify
Dacă sunteți nou, înregistrați-vă gratuit pentru un cont Apify. Platforma oferă opțiuni de înscriere prin e-mail, Google sau GitHub.
Pasul 3: Lipiți adresele URL Amazon ale conținutului țintă
În consola Apify, introduceți adresa URL a produsului sau categoriei Amazon pe care doriți să o extrageți. Am folositConsole de jocuri video și accesoriișiMobilăcategoria din acest exemplu.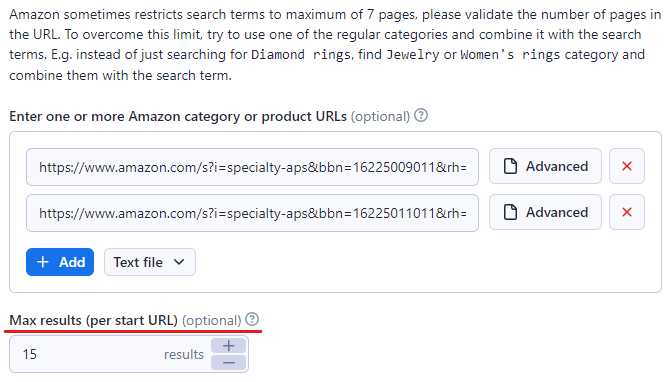
Puteți insera mai multe linkuri apăsând butonul „+ Adăugare”. Sau, dacă există multe linkuri, le puteți adăuga pe toate într-un fișier text și îl puteți încărca în Amazon Scraper.
De asemenea, decideți numărul maxim de elemente pe care doriți să le extrageți prin setarea unei limite în câmpul „Număr maxim de elemente”. Noi am setat-o la 15, dar o puteți seta cât de mare doriți.
Pasul 4: Activați Rezolvitorul CAPTCHA
Nu puteți extrage date de pe Amazon fără un rezolvitor CAPTCHA. Amazon este cunoscut pentru eficiența sa mare în detectarea roboților. De îndată ce suspectează activitatea unui bot, acesta trimite un CAPTCHA botului.
Așadar, pentru a vă asigura că Amazon Scraper funcționează fără probleme, activați rezolvarea CAPTCHA.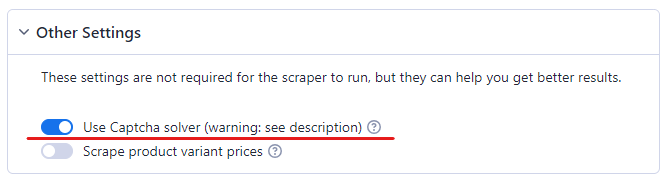
Pasul 5: Configurați proxy-ul
Utilizarea unui proxy este esențială pentru ocolirea măsurilor anti-scraping. Scraper-ul Amazon oferă diverse opțiuni de proxy, inclusiv Rezidențial, Centru de date sau propriul dvs., pentru a masca activitățile de scraping și a naviga în jurul restricțiilor. Citiți despre diferențe între proxy-urile rezidențiale și cele pentru centre de dateîn celălalt blog al nostru.
Opțiunea de proxy rezidențial este selectată în mod implicit, deoarece este cea mai bună pentru sistemele anti-scraping.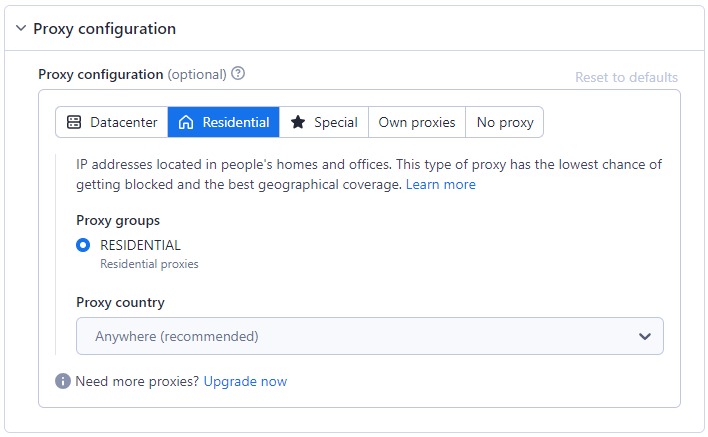
Pasul 6: Lansați Scraper-ul
Cu parametrii setați, porniți Amazon Product Scraper apăsând butonul „Start” butonul din partea de jos a paginii.
Starea se va schimba de la „În desfășurare” la „Reușit” după finalizare.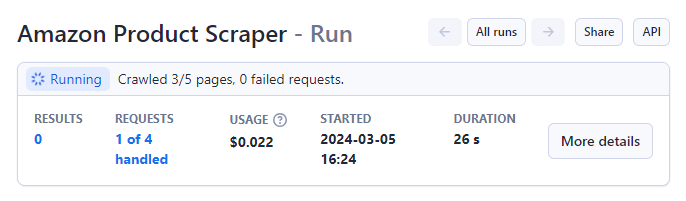
După finalizare, veți vedea previzualizarea datelor pe ecran.
Pasul 7: Exportați fișierul
Apăsați butonul „Exportați rezultatele” pentru a descărca datele colectate. Platforma acceptă mai multe formate, inclusiv CSV, JSON și Excel.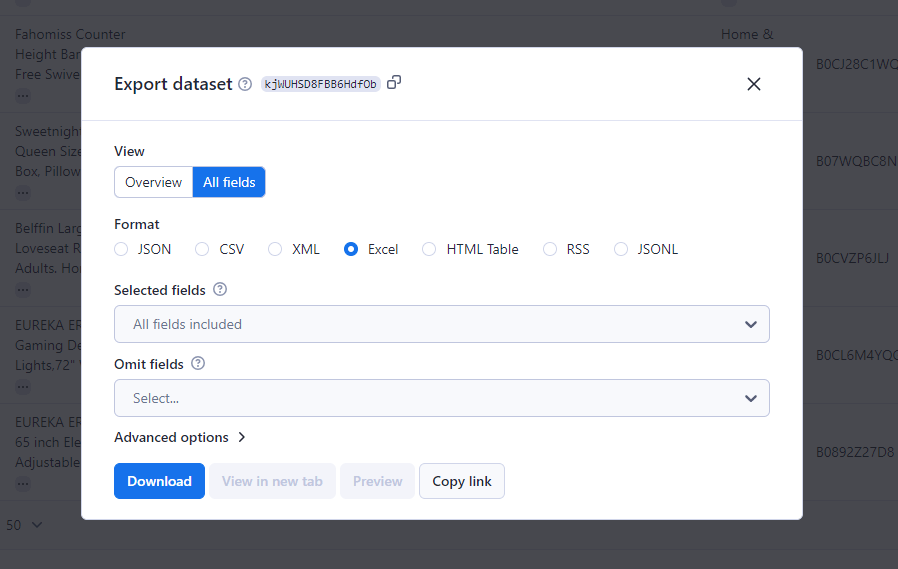
Scraperul Amazon Python folosind programarea
În Scraperul Amazon fără cod pe care l-am folosit mai sus, dacă vă uitați cu atenție la pasul 6 menționat anterior, 69 din 173 de solicitări au eșuat. Acest lucru se datorează faptului că Amazon blochează aceste solicitări.
Pentru a ocoli această problemă, va trebui să programați propriul script de scraping. În acest ghid, vom crea un scraper de produse Amazon în Python.
Așadar, să începem.
Pasul 1: Instalați Python
Pentru a programa scraperul nostru Amazon în Python, este esențial să aveți Python instalat pe computer. Se recomandă sădescărcați cea mai recentă versiunesau versiuni recente pentru compatibilitate cu bibliotecile necesare.
Pasul 2: Importarea bibliotecilor necesare
Punctul central al oricărui scraper Amazon implică preluarea și analizarea conținutului web. Pentru aceasta, folosim o combinație de biblioteci Python.
-
Cereri:pentru trimiterea de cereri HTTP către site-ul web Amazon
-
BeautifulSoup:Pentru a naviga și a analiza conținutul HTML returnat
-
lxml:pentru analiză
-
Pandas:pentru organizarea și exportarea datelor
Înainte de a le importa, va trebui să le instalați folosind următoarea comandă:
Acum le vom importa în scriptul nostru Python pentru scraper-ul Amazon:
Pasul 3: Configurarea anteturilor HTTP
Un obstacol comun în extragerea datelor web de pe Amazon îl reprezintă măsurile defensive ale Amazon împotriva accesului automat. Pentru a evita acest lucru, scriptul nostru Python pentru extragerea datelor de pe Amazon imită o solicitare a unui browser web prin includerea de anteturi HTTP personalizate, cum ar fi'User-Agent'și'Accept-Language'.
Este o practică mai bună să adăugați mai multe anteturi.
Pentru a obține aceste anteturi pentru browserul dvs.,
-
apăsați F12 pe o pagină Amazon pentru a deschide instrumentele pentru dezvoltatori,
-
Deschideți fila Rețele și selectați Anteturi
-
Reîncărcați pagina
-
Selectați prima solicitare
-
În fila Anteturi, derulați în jos până la secțiunea Anteturi Cerere și copiați valorile anteturilor menționate mai sus.
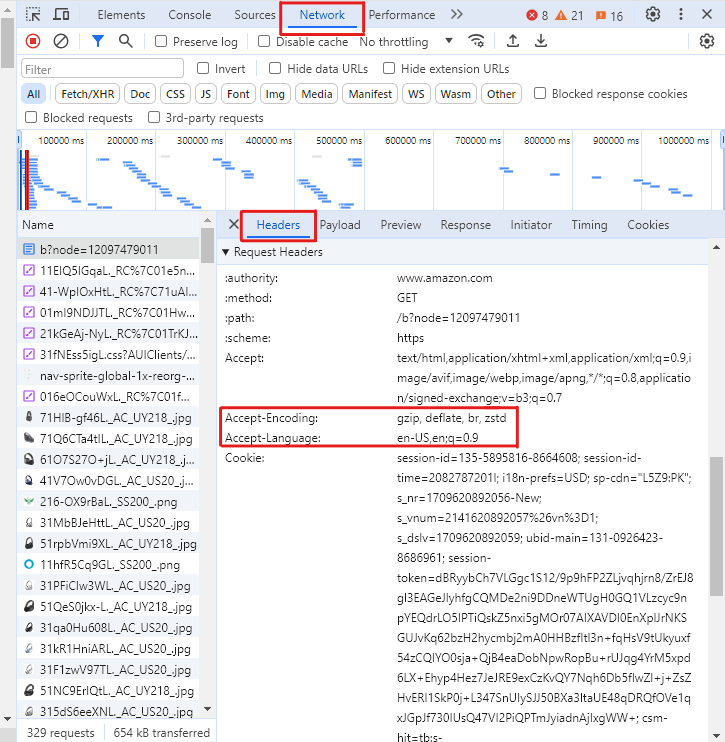
Fără aceste anteturi, există șanse mari ca Amazon să blocheze cererile get și să returneze un răspuns precum următorul, cu un status_code 503 (eroare) în loc de 200 (succes).
Pasul 4: Extragerea informațiilor despre produs
Scraperul nostru de produse Amazon include funcțiascrape_amazon_productcare îndeplinește sarcina critică de extragere a detaliilor produsului. Funcția preia adresa URL a paginii de categorie Amazon ca intrare și returnează un dicționar cu informațiile despre produs.
Metoda trimite apoi o solicitare către Amazon folosind adresa URL și variabila de anteturi personalizate pe care le-am creat mai sus.
După aceea, folosind selectorii CSS BeautifulSoup, vom prelua titlul, prețul, adresa URL a imaginii și descrierea produsului de pe paginile individuale ale produsului.
Pasul 5: Gestionarea listărilor de produse și Paginare
Pentru ca scriptul nostru Python de tip scraper Amazon să colecteze date extinse prin parcurgerea paginilor de categorii și gestionarea paginației, scriptul navighează prin paginile cu lista de produse Amazon.
Identifică linkurile către produse folosind selectori CSS și urmărește paginarea prin detectarea linkului către pagina „Următoare”.
Pasul 6: Salvarea datelor extrase
În final, datele extrase sunt agregate într-o listă de dicționare, care este apoi convertită într-un Pandas DataFrame. Acest DataFrame este apoi exportat ca fișier CSV.
Utilizați Amazon Scraper pe furiș
Extragerea datelor de pe Amazon este de obicei simplă. Cu toate acestea, s-ar putea să vă confruntați cu mai multe provocări, cum ar fi CAPTCHA-uri, blocări de solicitări și limite de rată.
Pentru a evita întâmpinarea acestor probleme, ar trebui să utilizați un browser anti-detecție, cum ar fiAdsPower. AdsPower se asigură că scraperul dvs. Amazon rămâne nedetectat, oferind funcții precum falsificarea amprentelor digitale și rotațiile proxy.
Așadar, Înscrie-te gratuit acum și începe să explorezi Amazon fără probleme.

Oamenii citesc și
- Top 12 jocuri neblocate de școală (+ soluții simple)
")
Top 12 jocuri neblocate de școală (+ soluții simple)
Descoperă 12 jocuri deblocate populare pentru școală, învață modalități practice de a accesa site-urile de jocuri blocate și vezi cum AdsPower te ajută să-ți menții browserul de jocuri blocat.
- Cum să gestionezi în siguranță mai multe conturi Apple în 2026

Cum să gestionezi în siguranță mai multe conturi Apple în 2026
Învață cum să gestionezi mai multe conturi Apple în siguranță cu sfaturi practice
- Cum să câștigi bani pe Substack în 2026: Strategii de venituri pentru creatori

Cum să câștigi bani pe Substack în 2026: Strategii de venituri pentru creatori
Vrei să câștigi bani pe Substack? Acest ghid prezintă metode de monetizare dovedite, sfaturi de creștere și cum transformă creatorii conținutul în venituri.
- Claude a căzut sau nu-l poți contacta? Cum să diagnostichezi și să remediezi problemele comune

Claude a căzut sau nu-l poți contacta? Cum să diagnostichezi și să remediezi problemele comune
Claude nu funcționează sau vezi erorile „Nu se poate contacta Claude”? Află cum să remediezi buclele de conectare, erorile de autentificare, problemele de rețea și multe altele.
- Instagram blocat și apoi interzis? Cum să-l recuperezi

Instagram blocat și apoi interzis? Cum să-l recuperezi
Instagram ți-a blocat contul și apoi l-a interzis? Acest ghid prezintă ce trebuie să faci și cum să recuperezi un cont blocat temporar sau dezactivat.
