
วิธีการขูด Facebook: 2 วิธีง่ายๆ สำหรับนักเขียนโค้ดและผู้ที่ไม่ใช่นักเขียนโค้ด

ผู้ใช้มากกว่า 3 พันล้านคนFacebook เป็นแพลตฟอร์มโซเชียลมีเดียที่ใหญ่ที่สุด
สิ่งนี้มีความหมายอย่างไรต่อธุรกิจ? การหาข้อมูลเชิงลึกของลูกค้า/ลูกค้าเปรียบเสมือนเหมืองทอง ใช่ไหม? แต่จะขูด Facebook ได้อย่างไร? คนที่ไม่มีประสบการณ์หรือความรู้ด้านการเขียนโค้ดจะสามารถทำได้หรือไม่?
คำตอบคือ ใช่ และนี่คือสิ่งที่บล็อกในวันนี้จะพูดถึง คุณจะค้นพบสองวิธีในการขูด Facebook อันหนึ่งไม่จำเป็นต้องมีประสบการณ์การเขียนโค้ด ส่วนอีกอันต้องมีความรู้ในการเขียนโปรแกรมเบื้องต้น มาเริ่มขูดกันเลยดีกว่า
ทำความเข้าใจ Facebook Scraping และข้อจำกัด
การรวบรวมข้อมูลบนเว็บ Facebook คือกระบวนการรวบรวมข้อมูลจาก Facebook โดยอัตโนมัติโดยใช้โปรแกรมรวบรวมข้อมูลบนเว็บหรือเครื่องมือรวบรวมข้อมูลบนเว็บ เกี่ยวข้องกับการรวบรวมข้อมูลที่เปิดเผยต่อสาธารณะ เช่น:
-
โพสต์ของผู้ใช้
-
ความคิดเห็น
-
การถูกใจ
-
ผู้ติดตาม
-
แฮชแท็ก
-
ฯลฯ
การรวบรวมข้อมูลบน Facebook มีวัตถุประสงค์หลากหลาย รวมถึงการวิเคราะห์ตลาด การวิเคราะห์ความรู้สึกของลูกค้า การติดตามแบรนด์ และการวิจัยคู่แข่ง
โดยทั่วไปแล้ว ผู้คนจะทำการสแครปข้อมูลบน Facebook โดยใช้โปรแกรมสแครปข้อมูลของ Facebook แบบไม่ต้องเขียนโค้ดหรือสคริปต์การเขียนโค้ด เทคนิคเหล่านี้ส่วนใหญ่ยังช่วยให้สามารถแปลงข้อมูลเป็นรูปแบบที่มีโครงสร้าง เช่น JSON, Excel หรือ CSV เพื่อการวิเคราะห์ที่ง่ายขึ้น
อย่างไรก็ตาม ก่อนที่จะถามถึงวิธีการสแครปข้อมูลบน Facebook คุณควรทราบข้อควรพิจารณาทางกฎหมายที่เกี่ยวข้องกับการสแครปข้อมูลบน Facebook
Facebook ไม่อนุญาตให้มีการสแครปข้อมูลผ่านระบบอัตโนมัติ เช่น บอท โรบอต สไปเดอร์ หรือสแครปข้อมูล โดยไม่ได้รับความยินยอมอย่างชัดแจ้ง การละเมิดข้อกำหนดเหล่านี้อาจส่งผลให้ถูกแบนและดำเนินคดี
นอกจากนี้ Facebook ยังมีหน้าแยกต่างหากสำหรับข้อกำหนดในการให้บริการ (TOS) เกี่ยวกับการขูดข้อมูลอัตโนมัติ ซึ่งครอบคลุมประเด็นต่างๆ อย่างครอบคลุม
อย่างไรก็ตาม การใช้เบราว์เซอร์ป้องกันการตรวจจับสามารถช่วยให้คุณหลีกเลี่ยงข้อจำกัดได้ เราจะพูดคุยเกี่ยวกับวิธีใช้ประโยชน์จากมัน แต่ก่อนหน้านั้น มาทำความเข้าใจกระบวนการขูดข้อมูลกันก่อน
วิธีการดึงข้อมูลจาก Facebook?
การดึงข้อมูลจาก Facebook อาจเป็นเรื่องยุ่งยาก แต่ก็สามารถทำได้ นี่คือ 2 วิธีที่จะทำให้สำเร็จ:
การขูดข้อมูล Facebook โดยใช้ No-Code Scraper
ไม่ใช่ทุกคนจะคุ้นเคยกับการเขียนโค้ดหรือมีเวลาเรียนรู้การเขียนโปรแกรมที่ซับซ้อนเพียงเพื่อขูดข้อมูล Facebook หากคุณเป็นหนึ่งในนั้น วิธีนี้เหมาะสำหรับคุณโดยเฉพาะ
โชคดีที่วิวัฒนาการของเครื่องมือที่ไม่ต้องใช้โค้ดทำให้กระบวนการขูดข้อมูลบน Facebook ง่ายและเข้าถึงได้ง่ายอย่างยิ่งสำหรับทุกระดับทักษะBardeen คือเครื่องมือขูดข้อมูลบน Facebook ตัวหนึ่ง ซึ่งมาในรูปแบบส่วนขยายของ Chrome และมีตัวเลือก 2 แบบ โดยแบบหนึ่งคุณสามารถใช้ระบบอัตโนมัติที่สร้างไว้ล่วงหน้าได้ และอีกแบบหนึ่งให้คุณปรับแต่งเครื่องมือขูดข้อมูลของคุณเองได้ตั้งแต่ต้น

ตัวเลือกการทำงานอัตโนมัติที่สร้างไว้ล่วงหน้าช่วยให้คุณเลือกจากรายการเทมเพลตสำหรับการรวบรวมข้อมูลประเภทต่างๆ ซึ่งอาจมีหรือไม่มีเทมเพลตที่คุณต้องการก็ได้

สมมติว่าคุณต้องการรวบรวมข้อมูลอีเมลจาก Facebook และไม่มีเทมเพลตสำหรับสิ่งนี้ คุณสามารถสร้างเครื่องมือรวบรวมข้อมูลเว็บ Facebook ของคุณเองได้ง่ายๆ เพียงเลือกตัวเลือก "สร้าง" ของคุณเอง

นี่คือวิธีการดึงข้อมูล Facebook โดยใช้เทมเพลต Bardeen สำเร็จรูปต่างๆ
ขั้นตอนที่ 1: ติดตั้ง Bardeen
ติดตั้งส่วนขยาย Chrome ของ Bardeen จากร้านค้าเว็บ Chrome

ขั้นตอนที่ 2: สร้างบัญชี
เมื่อติดตั้ง Bardeen แล้ว ให้สร้างบัญชีหากคุณเป็นผู้ใช้ใหม่ หรือเข้าสู่ระบบโดยใช้ข้อมูลประจำตัวบัญชีของคุณ

ขั้นตอนที่ 3: เปิด Bardeen
บน Chrome ให้เปิดแท็บใหม่ แล้วเปิดส่วนขยาย จากเมนูส่วนขยาย ให้เลือก Bardeen

ในหน้าต่าง Bardeen ให้เปิด Autobooks จากแผงด้านซ้าย
เราจะใช้เทมเพลตเครื่องมือสแกน Facebook ที่สร้างไว้ล่วงหน้า ดังนั้นให้กดปุ่ม Discover Now พิมพ์ Facebook ในแถบค้นหา เครื่องมือสแกน Facebook ทั้งหมดสำหรับดึงข้อมูลต่างๆ จะปรากฏขึ้น

ขั้นตอนที่ 4: เริ่มการขูด
มาขูดเพจ Facebook แล้วบันทึกลงใน Google Sheets กันเถอะ เลือกเทมเพลตที่แสดงในภาพหน้าจอด้านล่าง

ในหน้าต่างถัดไป ให้พิมพ์ create ในแถบค้นหา แล้วเลือกตัวเลือกที่ปรากฏขึ้น

ตอนนี้ ให้ตั้งชื่อไฟล์ Google Sheets ของคุณ เราขอแนะนำให้ตั้งชื่อไฟล์ตามประเภทการขูดข้อมูลที่คุณกำลังดำเนินการ เช่น การขูดเพจ Facebook หลังจากพิมพ์ชื่อแล้ว ให้กด Enter
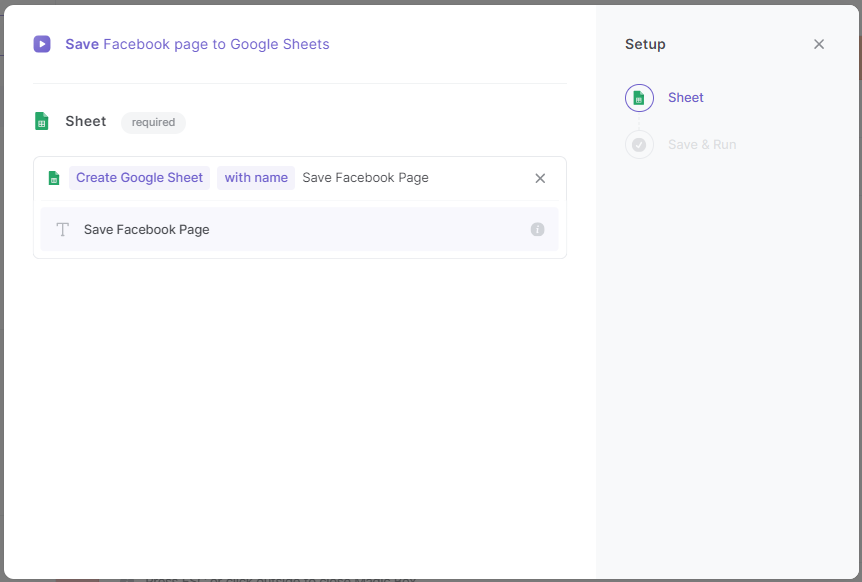
เริ่มกระบวนการขูดข้อมูลโดยการกดปุ่มใดๆ จากสองปุ่มที่ปรากฏ

หน้าต่างถัดไปจะให้คุณเลือกสองตัวเลือก คือ วาง URL ของเพจ Facebook เป้าหมาย หรือเลือกจากรายการแท็บ Facebook ที่เปิดอยู่ ดังนั้น ตรวจสอบให้แน่ใจว่าเพจ Facebook ที่คุณต้องการจะสแกนนั้น เปิดในเบราว์เซอร์หากคุณกำลังเลือกตัวเลือกที่สอง
เลือกอันที่เปิดเพจ Facebook เป้าหมายของคุณ ในกรณีของเรา เราเลือก Netflix

หน้าต่างป๊อปอัปจะปรากฏขึ้นพร้อมแถบความคืบหน้าเพื่อแสดงความคืบหน้าของงานการขูดข้อมูล

งานนี้อาจใช้เวลาไม่กี่วินาทีถึงไม่กี่นาที ขึ้นอยู่กับปริมาณข้อมูล หลังจากเสร็จสิ้น คุณจะสามารถดูไฟล์ Google Sheet หรือดาวน์โหลดข้อมูลเป็น CSV ได้

นี่เป็นเพียงเทมเพลตเดียว เทมเพลตอื่นๆ ก็มีขั้นตอนคล้ายกัน และรวบรวมข้อมูล Facebook ได้อย่างรวดเร็ว หรือหากเทมเพลตเหล่านี้ไม่ตรงตามความต้องการของคุณ คุณสามารถสร้างเครื่องมือรวบรวมข้อมูลแบบกำหนดเองของคุณเองโดยใช้ตัวเลือก "สร้าง" ของคุณเอง
วิธีการขูดข้อมูล Facebook โดยใช้ Python
การขูดข้อมูล Facebook ด้วยการเขียนโค้ดนั้นง่ายกว่าที่คุณคิด ขอบคุณไลบรารี Python ที่มีประโยชน์ที่เรียกว่าFacebook-page-scraper.
ดังที่ชื่อบอกไว้ มันถูกสร้างมาเพื่อสแกนเพจ Facebook
ไลบรารีนี้มีฟังก์ชันและอัลกอริทึมสำเร็จรูปที่จำเป็นสำหรับการรวบรวมข้อมูลเพจ Facebook นอกจากนี้ คุณไม่ต้องกังวลว่าจะถึงขีดจำกัดของปริมาณข้อมูลที่สามารถรวบรวมได้ และคุณไม่จำเป็นต้องสมัครใช้งานใดๆ หรือมีคีย์ API พิเศษเพื่อใช้งาน
เพื่อให้แน่ใจว่าคุณจะไม่ประสบปัญหาใดๆ เมื่อ Facebook พยายามหยุดหรือบล็อกคุณ คุณจะต้องมีสองสิ่ง: พร็อกซี เซิร์ฟเวอร์และไลบรารีเบราว์เซอร์แบบไม่มีส่วนหัว
พร็อกซีเซิร์ฟเวอร์จะซ่อนตำแหน่งที่คุณเชื่อมต่ออยู่จริง ทำให้ Facebook ไม่รู้ว่าคุณกำลังพยายามรวบรวมข้อมูลจำนวนมาก สิ่งนี้สำคัญมากเพราะ Facebook พยายามบล็อกหรือจำกัดผู้ที่พยายามขโมยข้อมูลจาก Facebook
นี่คือวิธีการขูดข้อมูล Facebook โดยใช้ไลบรารีเครื่องมือขูดข้อมูลหน้า Facebook:
ขั้นตอนที่ 1:
ขั้นแรก คุณต้องติดตั้ง Python บนคอมพิวเตอร์ของคุณและไลบรารี JSON ซึ่งช่วยให้เราจัดระเบียบข้อมูลที่เราเก็บรวบรวม
ถัดไป คุณจะติดตั้งFacebook-page-scraper. เปิดเทอร์มินัลหรือพรอมต์คำสั่งของคอมพิวเตอร์ แล้วพิมพ์คำสั่งนี้:
ขั้นตอนที่ 2:
เริ่มต้นด้วยการเพิ่มเครื่องมือขูดข้อมูลลงในสคริปต์ Python ของคุณ
ขั้นตอนที่ 3:
ขั้นตอนต่อไป ตัดสินใจว่าคุณสนใจเพจ Facebook ใดสร้างรายการหน้าเหล่านี้ในโค้ดของคุณ เช่นนี้:
ขั้นตอนที่ 4:
ตอนนี้ เราจะเขียนโค้ดที่จะช่วยให้เราอยู่ภายใต้เรดาร์ด้วยพร็อกซีและโหลดหน้าไดนามิก
-
พร็อกซี: คุณจะต้องกำหนดหมายเลขสำหรับพอร์ตพร็อกซี
-
จะดึงข้อมูลได้มากแค่ไหน: ตัดสินใจว่าคุณต้องการดึงโพสต์จำนวนเท่าใดจากแต่ละหน้า บางที 100 โพสต์อาจเป็นจุดเริ่มต้นที่ดี
-
การเลือกเบราว์เซอร์:คุณสามารถใช้เครื่องมือเช่น Google Chrome หรือ Firefox เพื่อทำการขูดข้อมูล เลือกสิ่งที่คุณชอบ
-
หมดเวลา: ตั้งค่าขีดจำกัดเวลาที่เครื่องมือสแกนควรพยายามรวบรวมข้อมูลก่อนที่จะหยุดพัก ซึ่งวัดเป็นวินาที 600 วินาที (หรือ 10 นาที) เป็นค่าเริ่มต้นที่ดี
-
เบราว์เซอร์แบบไม่มีส่วนหัว: เลือกว่าคุณต้องการดูการทำงานของเครื่องมือสแกนข้อมูล (ตั้งค่าเป็น False) หรือปล่อยให้ทำงานเงียบๆ ในพื้นหลัง (ตั้งค่าเป็น True) หากคุณอยากรู้ คุณอาจเริ่มต้นด้วยการให้มันมองเห็นได้
ด้วยขั้นตอนเหล่านี้ เครื่องมือขูดข้อมูล Python Facebook ของคุณก็พร้อมใช้งานแล้ว
ขั้นตอนที่ 5:
นี่คือวิธีการตั้งค่าสำหรับแต่ละเพจ Facebook ที่คุณต้องการสเครป:
ขั้นตอนที่ 6:
เมื่อโปรแกรมสแกนเริ่มทำงานแล้ว คุณจะตัดสินใจได้ว่าจะดูผลลัพธ์อย่างไร มีสองวิธีหลักในการทำเช่นนี้:
-
ตัวเลือกที่ 1: เพื่อดูอย่างรวดเร็ว คุณสามารถใช้เครื่องมือสแกนเพื่อแสดงผลลัพธ์ในคอนโซลได้โดยตรง วิธีนี้เหมาะสำหรับการตรวจสอบอย่างรวดเร็ว
-
ตัวเลือกที่ 2: หากคุณกำลังรวบรวมข้อมูลจำนวนมากและต้องการจัดระเบียบ คุณสามารถบันทึกลงในไฟล์ CSV ได้ ขั้นแรก ให้เลือกตำแหน่งที่จะเก็บผลลัพธ์ในคอมพิวเตอร์ของคุณ เช่น การสร้างโฟลเดอร์ใหม่
ขั้นตอนที่ 7:
สุดท้าย อย่าลืมเปลี่ยนพอร์ตพร็อกซีของคุณหลังจากแต่ละเซสชันการขูดข้อมูลเพื่อให้ทุกอย่างราบรื่นและหลีกเลี่ยงปัญหาใดๆ กับการแบน IP
Voilà! นี่คือคู่มือฉบับย่อของคุณเกี่ยวกับวิธีการขูดเพจ Facebook หากต้องการข้อมูลที่เฉพาะเจาะจงมากขึ้น เว็บไซต์มีเครื่องมือต่างๆ เช่น Facebook Marketplace Scraper สำหรับข้อมูลเชิงลึกของตลาดเป้าหมายและ Facebook email scraper สำหรับดึงข้อมูลรายละเอียดการติดต่อ
ใช้ AdsPower เพื่อการขูดข้อมูลบน Facebook อย่างปลอดภัย
ตามข้อกำหนดในการให้บริการของ Facebook การขูดข้อมูล Facebook ผ่านระบบอัตโนมัติถือเป็นเรื่องใหญ่ Facebook ยังคงอัปเดตข้อมูลของตนอย่างต่อเนื่อง sp;การขูดข้อมูล มาตรการรับมือ เพื่อทำให้กระบวนการนี้ยากขึ้นไปอีก คุณอาจสูญเสียบัญชีของคุณในการต่อสู้ครั้งนี้ได้ ดังที่ผู้ใช้ Reddit รายนี้เตือนไว้

แต่ก็ยังมีทางออกอยู่ สำหรับเบราว์เซอร์ป้องกันการตรวจจับ เช่น AdsPower มาตรการป้องกันการขูดข้อมูลไม่ใช่ปัญหา
ไม่ว่าคุณจะใช้โปรแกรมสแกน Facebook แบบไม่ต้องใช้โค้ดหรือไลบรารีโปรแกรมสแกน Facebook โดยใช้ Python AdsPower ก็มอบฟีเจอร์ที่จำเป็นให้กับคุณเพื่อหลีกเลี่ยงข้อจำกัดเหล่านี้
เราหวังว่าบล็อกนี้จะให้ข้อมูลทั้งหมดที่จำเป็นแก่คุณเกี่ยวกับวิธีการขูดข้อมูลบน Facebook ขอให้สนุกกับการขูดข้อมูล!

คนยังอ่าน
- บัญชี Instagram ถูกล็อกแล้วถูกแบน? จะกู้คืนได้อย่างไร

บัญชี Instagram ถูกล็อกแล้วถูกแบน? จะกู้คืนได้อย่างไร
Instagram ล็อกบัญชีของคุณแล้วแบนทิ้งใช่ไหม? คู่มือนี้จะอธิบายสิ่งที่คุณควรทำและวิธีการกู้คืนบัญชีที่ถูกล็อกหรือปิดใช้งานชั่วคราว
- ฉันจะหารายได้จาก Kwai ในปี 2026 ได้อย่างไร?

ฉันจะหารายได้จาก Kwai ในปี 2026 ได้อย่างไร?
เรียนรู้วิธีสร้างรายได้โดยใช้ Kwai ในปี 2026 ผ่านโปรแกรมครีเอเตอร์ การไลฟ์สตรีม การตลาดแบบพันธมิตร การสนับสนุน และเคล็ดลับการขยายธุรกิจด้วย AdsPower
- บัญชี Avakin Life ของคุณถูกระงับใช่ไหม? นี่คือสิ่งที่คุณควรทำ

บัญชี Avakin Life ของคุณถูกระงับใช่ไหม? นี่คือสิ่งที่คุณควรทำ
สงสัยไหมว่าทำไมบัญชี Avakin Life ของคุณถึงถูกระงับในปี 2026? เรียนรู้สาเหตุที่เป็นไปได้ ตั้งแต่ปัญหาการเข้าสู่ระบบและการกู้คืน ไปจนถึงการละเมิดกฎ และอื่นๆ อีกมากมาย
- วิธีดู TikTok แบบไม่ถูกบล็อกในโรงเรียน?

วิธีดู TikTok แบบไม่ถูกบล็อกในโรงเรียน?
เรียนรู้วิธีดู TikTok ได้โดยไม่ถูกบล็อกในโรงเรียนโดยใช้ VPN, พร็อกซี, การเปลี่ยน DNS หรือเบราว์เซอร์ AdsPower - วิธีที่ปลอดภัย ถูกกฎหมาย และมีประสิทธิภาพในการหลีกเลี่ยงข้อจำกัด
- Discord จะถูกปลดบล็อกในปี 2026: 7 วิธีที่ได้รับการพิสูจน์แล้วสำหรับทุกอุปกรณ์

Discord จะถูกปลดบล็อกในปี 2026: 7 วิธีที่ได้รับการพิสูจน์แล้วสำหรับทุกอุปกรณ์
ไม่ต้องกังวลหาก Discord ถูกบล็อก คู่มือนี้จะอธิบายวิธีการปลดบล็อก Discord เรียนรู้วิธีหลีกเลี่ยงข้อจำกัดทั่วไปได้อย่างง่ายดายและปลดบล็อก Discord ได้ในวันนี้
