
วิธีขูด Instagram? 3 วิธีที่จะได้รับประโยชน์สูงสุดจากความพยายามในการขูดของคุณ
ด้วย ผู้ใช้ 1.3 พันล้านคน และ Instagram เปรียบเสมือนเหมืองทองแห่งข้อมูลอันทรงคุณค่าสำหรับธุรกิจต่างๆ เพื่อใช้ในการวิจัยตลาด การสร้างลูกค้าเป้าหมาย และการติดตามผลการปฏิบัติงาน แต่การรวบรวมข้อมูลบน Instagram เพื่อให้ได้มาซึ่งข้อมูลเหล่านี้ถือเป็นส่วนที่ยุ่งยาก
ขั้นตอนนี้ไม่ตรงไปตรงมาและมีความซับซ้อนมากมาย ทั้งเนื่องจากนโยบายของ Instagram หรือความคลุมเครือทางเทคนิค
คู่มือนี้จะตอบคำถามวิธีการดึงข้อมูลบน Instagram โดยแนะนำสามวิธีที่เกี่ยวข้องกับวิธีเขียนโค้ดน้อยและหนัก และวิธีที่ไม่ต้องเขียนโค้ด
การขูดข้อมูลบน Instagram ถูกกฎหมายหรือไม่?
คำตอบของคำถามที่ว่า การขูดข้อมูลบน Instagram ถูกกฎหมายหรือไม่? คือ ใช่ และ ไม่ใช่ ในเวลาเดียวกัน เมื่อมันเกิดขึ้น ตามประเภทของข้อมูลที่คุณต้องการรวบรวม หากคุณต้องการรวบรวมข้อมูลจาก Instagram สู่สาธารณะ คำตอบคือ ใช่
แต่ถ้าคุณกำลังรวบรวมข้อมูลส่วนตัวบน Instagram ซึ่งจำเป็นต้องมีการเข้าสู่ระบบบน Instagram นั่นถือเป็นสิ่งต้องห้ามอย่างชัดเจน และคุณก็จะย้าย ht จะถูกระงับบัญชี และในกรณีที่เลวร้ายที่สุด จะมีการดำเนินคดีทางกฎหมาย แต่แม้กระทั่งข้อมูลสาธารณะ คุณต้องแน่ใจว่าได้ใช้วิธีการขูดข้อมูลอย่างถูกกฎหมาย
ในการรวบรวมข้อมูล Instagram ให้เป็นข้อมูลที่ถูกต้องตามกฎหมาย คุณสามารถใช้ API ที่ Instagram จัดเตรียมไว้ให้ได้ ซึ่งรวมถึง Instagram Graph API และ Instagram Basic API
Graph API ช่วยให้คุณสามารถจัดการและดึงข้อมูลเกี่ยวกับบัญชีธุรกิจและผู้สร้าง ในขณะที่ Basic API ช่วยให้คุณอ่านอย่างเดียว การเข้าถึงข้อมูลพื้นฐานของผู้ใช้ API ทั้งสองนี้เป็นไปตามนโยบายของ Instagram เกี่ยวกับการรวบรวมข้อมูล ดังนั้นการรวบรวมข้อมูลบน Instagram จึงถูกกฎหมายอย่างสมบูรณ์
ดังนั้นก่อนที่คุณจะเริ่มขูดข้อมูลบน Instagram ลองถอยกลับมาและคิดทบทวนตัวเองก่อนว่า Instagram อนุญาตให้ขูดข้อมูลได้หรือไม่ และต้องแน่ใจว่าคุณดำเนินการอย่างระมัดระวังในขณะที่กำลังทำอยู่
ข้อมูล Instagram ไหนที่คุณสามารถดึงได้ง่ายๆ?
ก่อนที่จะแสดงวิธีรวบรวมข้อมูลจาก Instagram เรามาค้นหาก่อนว่าข้อมูลใดที่สามารถรวบรวมข้อมูลจากแพลตฟอร์มได้อย่างถูกกฎหมาย การรวบรวมข้อมูลบนเว็บ Instagram อย่างถูกกฎหมายสามารถทำให้คุณเข้าถึงข้อมูลสามหมวดหมู่ต่อไปนี้:
-
แฮชแท็ก: คุณสามารถดูรูปภาพหรือวิดีโอที่กำลังได้รับความนิยมสูงสุดหรือล่าสุด ซึ่งถูกแท็กด้วยแฮชแท็กเฉพาะในคำบรรยายภาพ
-
โปรไฟล์: คุณสามารถดูข้อมูลโปรไฟล์ เช่น โพสต์ จำนวนสื่อ และจำนวนผู้ติดตาม
-
โพสต์: คุณสามารถดูเมตริกต่างๆ เช่น จำนวนความคิดเห็น จำนวนการกดไลก์ รหัสโปรไฟล์ วันที่เผยแพร่ และ URL
3 วิธีในการดึงข้อมูลบน Instagram
นี่คือสามวิธีในการดึงข้อมูลบน Instagram เลือกวิธีที่เหมาะสมกับความต้องการและทรัพยากรของคุณ:
การขูดข้อมูลบน Instagram โดยใช้ Instagram API
นี่คือคำแนะนำทีละขั้นตอนเกี่ยวกับวิธีการขูดข้อมูลบน Instagram แต่ให้แน่ใจว่าคุณปฏิบัติตามข้อกำหนดต่อไปนี้ก่อน:
-
บัญชีธุรกิจ/ผู้สร้างบน Instagram
-
เพจ Facebook ที่เชื่อมโยงกับบัญชีธุรกิจ/ผู้สร้างบน Instagram
-
บัญชีนักพัฒนา Facebook เพื่อใช้ Instagram Graph API
-
การตั้งค่าแอป Facebook ที่ลงทะเบียนแล้วพร้อมการตั้งค่าขั้นต่ำ
เมื่อคุณทำสิ่งที่จำเป็นเหล่านี้เสร็จแล้ว ขั้นตอนถัดไปจะเป็นแบบนี้
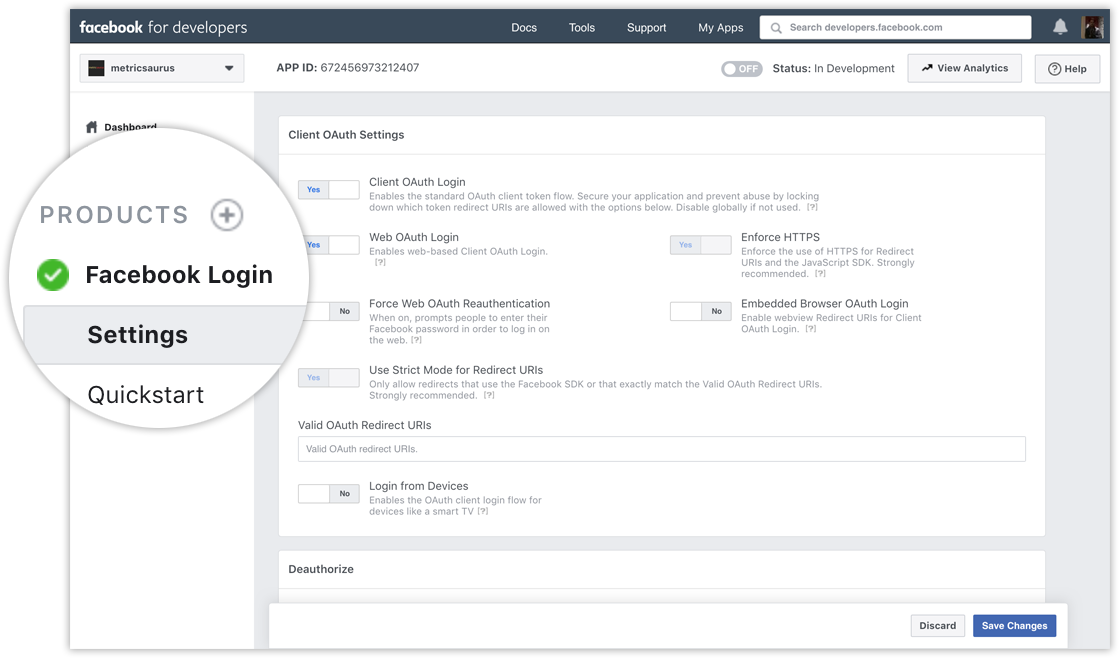
เพิ่มฟังก์ชันการเข้าสู่ระบบ Facebook:
ต่อไป คุณจะต้องเข้าสู่ระบบ Facebook ในแอปของคุณด้วยความช่วยเหลือของเอกสารประกอบการเข้าสู่ระบบ Facebook และตรวจสอบให้แน่ใจว่าคำขอการเข้าสู่ระบบของคุณมีสิทธิ์พื้นฐานสองประการต่อไปนี้:
สร้างโทเค็นการเข้าถึง:
การดำเนินการต่างๆ จากแดชบอร์ดแอปบนบัญชี Instagram จำเป็นต้องมีโทเค็นการเข้าถึงของผู้ใช้ ทางด้านขวาของหน้าแดชบอร์ด ให้เปิดผู้ใช้หรือเพจ และเลือก "รับโทเค็นการเข้าถึงของผู้ใช้"
หน้าต่างป๊อปอัปจะปรากฏขึ้นเพื่อแจ้งว่าแอป (ในกรณีนี้คือแอปของคุณ) กำลังขอสิทธิ์ตามที่กล่าวไว้ข้างต้น เพียงแค่กดปุ่ม "ดำเนินการต่อ" หรือ "ตกลง" คุณก็จะได้รับโทเค็นการเข้าถึงของผู้ใช้ในช่อง "โทเค็นการเข้าถึง" ในแดชบอร์ดของคุณ
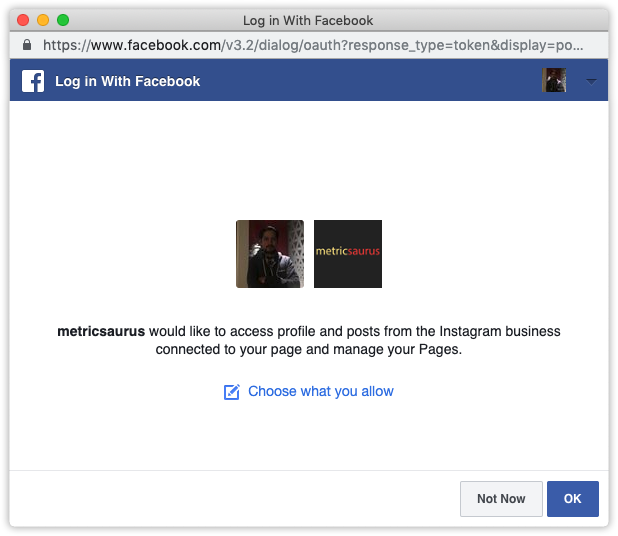
ขณะนี้เราจะใช้โทเค็นการเข้าถึงของผู้ใช้เพื่อดำเนินการค้นหาข้อมูลพื้นฐานบางอย่างบนบัญชี Instagram
1. รับ ID เพจ Facebook:
ก่อนอื่น เราต้องมี ID ของเพจ Facebook ที่เชื่อมต่อกับบัญชีธุรกิจ Instagram โดยให้เรียกใช้ Get query ต่อไปนี้ในแดชบอร์ด
ข้อมูลนี้จะแสดงชื่อและ ID ของเพจ Facebook ที่เป็นของผู้ใช้ Facebook ผลลัพธ์ที่ได้จะมีลักษณะดังนี้
คัดลอก ID ของเพจที่เชื่อมโยงกับบัญชีธุรกิจ Instagram
2. รับ ID บัญชีธุรกิจ Instagram:
การใช้ ID ของ Facebook พิมพ์สคริปต์ต่อไปนี้ในแถบคำสั่ง และกด "ส่ง"
คุณจะได้ผลลัพธ์ต่อไปนี้
3. รับวัตถุสื่อของบัญชี Instagram:
คัดลอก ID Instagram จากผลลัพธ์ และรันสคริปต์ต่อไปนี้เพื่อรับ ID ของทุกเรื่องราวที่กำลังโพสต์อยู่ในบัญชีธุรกิจ Instagram ในปัจจุบัน
เอาต์พุตจะมี ID สำหรับแต่ละเรื่องราว
นี่เป็นเพียงตัวอย่างหนึ่ง การใช้ Instagram Graph API คุณยังสามารถรับข้อมูลอื่นๆ เช่น เมตาดาต้าของผู้ใช้ Instagram และทำการวิจัยแฮชแท็กได้อีกด้วย
ตอนนี้เรามาดูวิธีอื่นในการดึงข้อมูลจาก Instagram กันดีกว่า
การขูดข้อมูลบน Instagram โดยใช้โปรแกรมขูดข้อมูลบนคลาวด์แบบไม่ต้องเขียนโค้ด
สำหรับผู้ที่ไม่มีพื้นฐานการเขียนโค้ดมาก่อน วิธีการข้างต้นอาจเข้าใจยาก ไม่ต้องพูดถึงการทำเลย แต่ไม่ต้องกังวล มีเครื่องมือสแกนบน Instagram มากมายที่ทำงานได้สำเร็จโดยไม่ต้องใช้โค้ดใดๆ
ไปที่หน้า Apify Instagram Scraper:
เปิดหน้า Apify Instagram Scraper แล้วคลิกลองใช้ฟรีปุ่ม

ลงทะเบียน Apify โดยใช้อีเมลของคุณ หรือบัญชี Google หรือ Github การดำเนินการนี้จะนำคุณไปยังคอนโซล Apify ซึ่งเป็นที่ที่การรวบรวมข้อมูล Instagram เกิดขึ้นจริง
รวบรวม URL เป้าหมายของ Instagram:
การใช้แอปหรือเว็บไซต์ Instagram เพื่อรวบรวม URL โปรไฟล์ทั้งหมดของบัญชี Instagram ที่คุณต้องการรวบรวม บนคอนโซล Apify วาง URL เหล่านี้ทั้งหมดลงในช่องป้อนข้อมูลที่กำหนดทีละรายการ หากต้องการป้อน URL ทั้งหมดพร้อมกัน คุณสามารถคลิกปุ่มแก้ไขเป็นกลุ่มได้
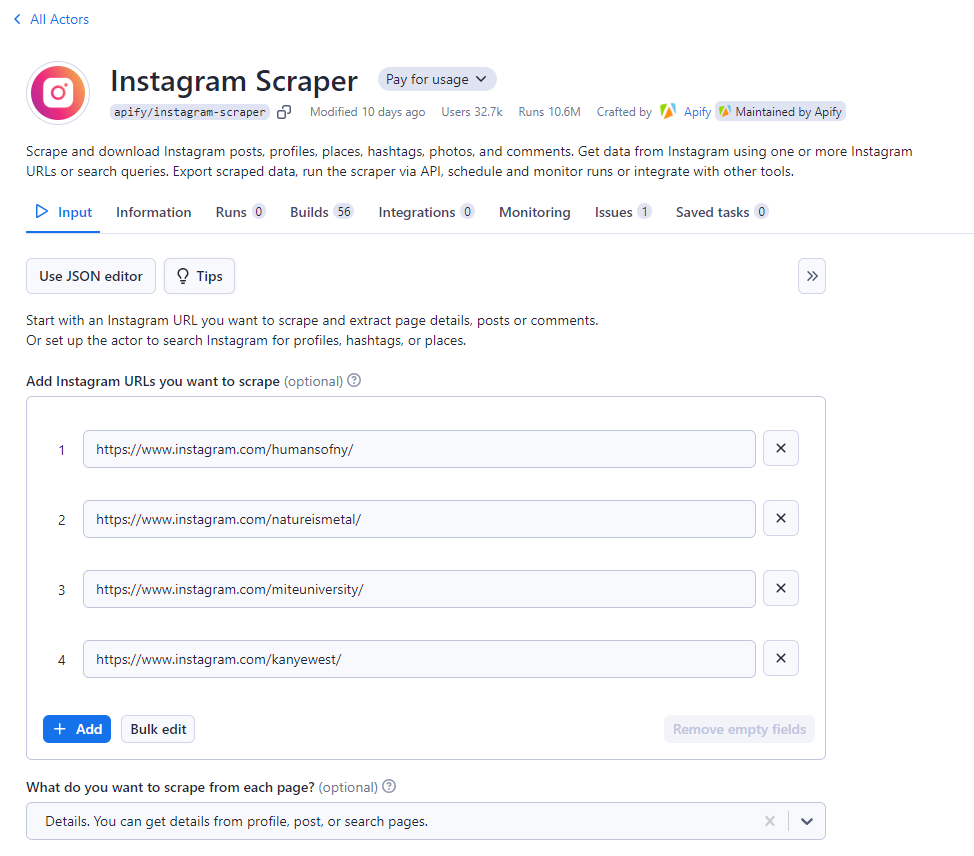
Apify มีตัวเลือกการดึงข้อมูลสามแบบสำหรับ URL ที่ให้มา คุณสามารถดึงข้อมูลโพสต์ ความคิดเห็น หรือรับรายละเอียดอื่นๆ จากโปรไฟล์ได้
คลิกบันทึกและเริ่ม:
ปล่อยการตั้งค่าที่เหลือไว้ตามเดิม แล้วกดบันทึกและเริ่มต้นเพื่อเรียกใช้เครื่องมือขูดข้อมูล ผลลัพธ์จะอยู่ในรูปแบบของตารางที่มีแถวเท่ากับจำนวน ของ URL โปรไฟล์ที่คุณให้ไว้ พร้อมด้วยคอลัมน์หลายคอลัมน์ที่มีข้อมูลเมตาโปรไฟล์ เช่น ประวัติ, จำนวนผู้ติดตาม, จำนวนโพสต์, จำนวนรีล, รหัสบัญชี และสถานะการยืนยัน เพื่อระบุชื่อไม่กี่ชื่อ

จัดเก็บผลลัพธ์:
ตอนนี้กดปุ่มส่งออกผลลัพธ์และเลือกรูปแบบไฟล์ที่คุณต้องการจากหน้าต่างป๊อปอัป คุณยังสามารถทำความสะอาดข้อมูลได้โดยการเลือกหรือ การละเว้นช่องที่คุณไม่ต้องการ หลังจากนั้น คุณสามารถดาวน์โหลดผลลัพธ์ ดูผลลัพธ์ในแท็บใหม่ หรือแชร์ผ่านลิงก์ได้

การดึงข้อมูล Instagram โดยใช้ภาษาการเขียนโปรแกรม
คู่มือนี้สาธิตวิธีการดึงข้อมูลจาก Instagram โดยใช้ Python และ Selenium ซึ่งเป็นเฟรมเวิร์กอัตโนมัติของเบราว์เซอร์
นำเข้าไลบรารีที่จำเป็น:
ในการเริ่มต้น ให้นำเข้าไลบรารีพื้นฐาน ได้แก่ Selenium, webdriver และ Selenium-Stealth เพื่อป้องกันการตรวจจับ
ไลบรารี pprint จะช่วยเราพิมพ์ผลลัพธ์ออกมาได้อย่างเรียบร้อย เพื่อให้อ่านง่ายขึ้น
รวบรวมชื่อผู้ใช้ Instagram:
สร้างรายการและเพิ่มชื่อผู้ใช้ของโปรไฟล์ Instagram ที่คุณต้องการกำหนดเป้าหมาย
ตัวแปรเอาต์พุตคือพจนานุกรมที่เราจะใช้เพื่อจัดเก็บผลลัพธ์
กำหนดฟังก์ชันหลัก:
ฟังก์ชันหลักจะข้ามรายการชื่อผู้ใช้ทีละคน และเรียกใช้ฟังก์ชัน "scrape" ในชื่อผู้ใช้แต่ละชื่อ
กำหนดฟังก์ชันสำหรับจัดการการตั้งค่าเบราว์เซอร์:
ฟังก์ชันนี้จะปรับการตั้งค่าเบราว์เซอร์ก่อนการร้องขอการดึงข้อมูลแต่ละครั้ง เพื่อเพิ่มการไม่เปิดเผยตัวตนเพื่อหลีกเลี่ยงการตรวจจับโดย Instagram การเปลี่ยนแปลงเหล่านี้รวมถึงพร็อกซีแบบหมุนเวียน การกำหนดค่าการตั้งค่า Selenium-Stealth และการสร้างเอเจนต์ผู้ใช้เทียม
กำหนดฟังก์ชันสำหรับการสแกน:
ฟังก์ชัน scrape() ที่เรียกใช้ในฟังก์ชันหลัก รับชื่อผู้ใช้ Instagram หนึ่งชื่อเป็นอาร์กิวเมนต์ และสร้างโปรไฟล์ปลายทางที่เราจะใช้ในการส่งคำขอโดยใช้เบราว์เซอร์ Chrome ที่สร้างผ่านฟังก์ชัน prepare_browser()
เราจะตรวจสอบสถานะของคำขอด้วย หากคำขอของคุณถูกส่งไปที่หน้าเข้าสู่ระบบ นั่นหมายความว่าคำขอนั้นล้มเหลว ในขณะที่หาก หากไม่ได้เข้าสู่ระบบอีกครั้ง คำขอจะสำเร็จ และผลลัพธ์จะถูกแยกวิเคราะห์เป็น JSON และส่งไปยังฟังก์ชัน parse_data() พร้อมกับชื่อผู้ใช้
กำหนดฟังก์ชัน parse_data() :
ฟังก์ชันนี้จะแยกวิเคราะห์ข้อมูล JSON ในอาร์กิวเมนต์ user_data เพื่อรับฟิลด์ข้อมูลที่ต้องการ ในตัวอย่างนี้ เรากำลังรวบรวมข้อมูลชื่อเต็ม หมวดหมู่บัญชี จำนวนผู้ติดตาม และคำบรรยายภาพของผู้ใช้
เขียนโค้ดไดรเวอร์:
โค้ดไดรเวอร์จะเริ่มกระบวนการสแกนข้อมูล ดึงข้อมูลลงในตัวแปรเอาต์พุต และเรียกใช้ฟังก์ชัน pprint() เพื่อแสดงผลในรูปแบบที่สวยงาม
ข้ามการตรวจจับด้วย AdsPower Antidetect Browser
นี่คือจุดที่ AdsPower เข้ามาช่วย โดยช่วยให้คุณรักษาความเป็นส่วนตัวเมื่อรวบรวมข้อมูลจาก Instagram ซึ่งอาจมีโอกาสละเมิดนโยบายของ Instagram AdsPower ใช้เทคนิคป้องกันการตรวจจับ เช่น การหมุนเวียน IP และการจำกัดอัตรา เพื่อหลบเลี่ยงมาตรการป้องกันการคัดลอก
ใช้เบราว์เซอร์ AdsPower เพื่อป้องกันการตรวจจับ
สรุป
Instagram อนุญาตให้ทำการขูดข้อมูลเฉพาะข้อมูลที่เปิดเผยต่อสาธารณะบนแพลตฟอร์ม ซึ่งมี API ให้เลือกสองแบบ แต่ API เหล่านี้มีระดับการขูดข้อมูลพื้นฐานมาก โดยไม่อนุญาตให้คุณขูดข้อมูลจาก Instagram ซึ่งจริงๆ แล้วเกี่ยวข้องกัน
สิ่งนี้ทำให้เรามีเว็บสแครปเปอร์จากบุคคลที่สาม หรือสร้างสแครปเปอร์ของคุณเองโดยใช้ภาษาการเขียนโปรแกรม อย่างไรก็ตาม การสแครปเปอร์บน Instagram โดยใช้วิธีการที่ไม่เป็นทางการเหล่านี้มีโอกาสถูกตรวจจับได้ ดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณใช้เบราว์เซอร์ AdsPower antidetect เพื่อเพิ่มการป้องกัน

คนยังอ่าน
- 10 อันดับ Headless Browser ที่ดีที่สุดสำหรับการทำ Web Scraping: ข้อดีและข้อเสีย

10 อันดับ Headless Browser ที่ดีที่สุดสำหรับการทำ Web Scraping: ข้อดีและข้อเสีย
พบกับ Headless Browser ที่ดีที่สุดสำหรับ Web Scraping เรียนรู้ความแตกต่างจากเบราว์เซอร์ทั่วไป และสำรวจตัวเลือกขนาดเล็กที่มีประสิทธิภาพ...
- สุดยอดแพลตฟอร์มโฆษณา Native Ads สำหรับ Publisher

สุดยอดแพลตฟอร์มโฆษณา Native Ads สำหรับ Publisher
สำรวจแพลตฟอร์มโฆษณา Native Ads ชั้นนำสำหรับ Publisher เรียนรู้วิธีปรับปรุงประสิทธิภาพโฆษณาของคุณ และวิธีใช้ AdsPower เพื่อเพิ่มยอดทราฟฟิกให้สูงสุด
- เว็บไซต์เพลงที่ดีที่สุดที่เข้าถึงได้โดยไม่ถูกบล็อกสำหรับโรงเรียนและที่ทำงาน (2026)

เว็บไซต์เพลงที่ดีที่สุดที่เข้าถึงได้โดยไม่ถูกบล็อกสำหรับโรงเรียนและที่ทำงาน (2026)
ค้นพบเว็บไซต์เพลงที่ดีที่สุดที่สามารถเข้าถึงได้โดยไม่ถูกบล็อกสำหรับการเรียนและการทำงาน
- ไอเดียสร้างรายได้แบบ Passive Income จาก Reddit ที่ดีที่สุดสำหรับมือใหม่ (คู่มือปี 2026)

ไอเดียสร้างรายได้แบบ Passive Income จาก Reddit ที่ดีที่สุดสำหรับมือใหม่ (คู่มือปี 2026)
กำลังมองหาไอเดียสร้างรายได้แบบ Passive Income อยู่ใช่ไหม? มาดู 5 วิธีที่พิสูจน์แล้วว่าผู้ใช้ Reddit สามารถสร้างรายได้ในปี 2026 กัน
- คุณสามารถดู Instagram Stories โดยไม่เปิดเผยตัวตนได้หรือไม่? คู่มือฉบับสมบูรณ์ปี 2026

คุณสามารถดู Instagram Stories โดยไม่เปิดเผยตัวตนได้หรือไม่? คู่มือฉบับสมบูรณ์ปี 2026
เรียนรู้วิธีดู Instagram Stories แบบไม่เปิดเผยตัวตนในปี 2026 และค้นพบวิธีการที่ดีที่สุดสำหรับความเป็นส่วนตัวและความต้องการในการท่องเว็บของคุณ
