
Bester Anti-Detect-Browser für Web Scraping im Jahr 2026
Werfen Sie einen kurzen Blick
Hier kommen Browser mit Anti-Erkennungsschutz ins Spiel. Anstatt Erkennungsprobleme erst im Nachhinein zu beheben, ermöglichen sie einen realistischeren Start mit separaten Identitäten, stabilen Sitzungen und einem Verhalten, das dem echter Nutzer ähnelt. In diesem Leitfaden erklären wir die Funktionsweise und welche Tools im Jahr 2026 tatsächlich relevant sein könnten.
Warum modernes Web-Scraping einen Browser mit Anti-Erkennungsschutz benötigt
Was sich beim Web-Scraping wirklich verändert hat, sind nicht die verwendeten Tools, sondern die Art und Weise, wie Websites sich wehren.
Die meisten Plattformen kombinieren mittlerweile mehrere Erkennungsebenen gleichzeitig. Anstatt nur Anfragen zu prüfen, betrachten sie den Gesamtkontext Ihrer Aktivitäten, einschließlich:
- Browser-Fingerabdruckdetails wie Canvas, WebGL, Schriftarten und Gerätespezifikationen
- Verhaltenssignale wie Mausbewegungen und Scrollmuster
- IP-Reputation und Anfragehäufigkeit
- Sitzungskontinuität, einschließlich Konsistenz von Cookies und Headern
Das Problem ist, dass alles perfekt zusammenpassen muss. Man kann zwar völlig gültige Anfragen senden, aber wenn etwas an der Konfiguration nicht stimmt, fällt es sofort auf. Schon eine einfache Diskrepanz zwischen User-Agent und WebGL-Fingerabdruck kann Alarm auslösen. Wenn das passiert, während man wiederholt Anfragen von derselben IP-Adresse sendet, folgen Sperrungen meist recht schnell.
Hier kommen Browser mit Anti-Erkennungs-Funktion ins Spiel. Sie reduzieren diese Inkonsistenzen, indem sie Ihnen mehr Kontrolle über die Umgebung geben:
- Jedes Browserprofil hat seinen eigenen Fingerabdruck.
- Sitzungen bleiben über Cookies, Speicher und Header hinweg konsistent.
- Die Gesamtkonfiguration verhält sich eher wie eine reale Benutzerumgebung.
Letztendlich ist das Ziel einfach. Anstatt wie ein im Hintergrund laufendes Skript auszusehen, fügt sich Ihre Einrichtung nahtlos in die normale Benutzeraktivität ein, was genau den Erfolg von Web-Scraping-Workflows sichert und deren Laufzeit verlängert.
Was ist ein Browser, der Web-Scraping vor Erkennung schützt?
Ein Anti-Detect-Browser ist ein Browser, mit dem Sie mehrere isolierte Profile ausführen können, von denen jedes über einen eigenen Fingerabdruck und eigene Sitzungsdaten verfügt, sodass Ihre Aktivitäten den Anschein erwecken, von verschiedenen echten Benutzern zu stammen.
Wie es sich von Standardbrowsern unterscheidet
Ein herkömmlicher Browser ist nicht für die Trennung von Identitäten ausgelegt. Selbst wenn Sie das Konto wechseln oder Cookies löschen, bleiben viele zugrundeliegende Signale unverändert, was es Websites erleichtert, Sitzungen miteinander zu verknüpfen.
- Zeigt einen einheitlichen Fingerabdruck über alle Tabs und Sitzungen hinweg.
- Begrenzte Kontrolle über Fingerabdruckelemente wie WebGL, Schriftarten oder Gerätespezifikationen.
- Cookies und Speicher können zurückgesetzt werden, aber tieferliegende Identifikatoren bleiben erhalten.
- Nicht ausgelegt für den Betrieb mehrerer unabhängiger Identitäten in großem Umfang.
Ein Browser mit Anti-Erkennungsfunktion ändert dies, indem er alles auf Profilebene isoliert, sodass die einzelnen Sitzungen unabhängig voneinander erscheinen.
Wie es sich von kopflosen Schabwerkzeugen unterscheidet
Headless-Tools konzentrieren sich auf Automatisierung und Geschwindigkeit, nicht darauf, wie „realistisch“ die Browserumgebung aussieht. Sie sind leistungsstark, können aber standardmäßig dennoch erkennbare Muster hinterlassen.
- Optimiert für automatisierte Arbeitsabläufe und Skripte
- Schneller und leichter für großflächige Abtragsarbeiten
- Leichter zu erkennen ohne zusätzliche Tarnkonfiguration
- Begrenzte integrierte Kontrolle über realistische Browser-Fingerabdrücke
Antidetect-Browser konzentrieren sich auf die andere Seite des Problems und sorgen für konsistentere Umgebungen, die schwerer miteinander zu verknüpfen sind.
Deshalb werden sie in vielen realen Umgebungen zusammen eingesetzt. Das eine System übernimmt die Automatisierung, das andere die Identitäts- und Tarnfunktion.
Hauptmerkmale eines Web-Scraping-Browsers
Nicht jeder Browser mit Anti-Erkennungs-Funktion eignet sich tatsächlich zum Web-Scraping. Manche sind eher für die Kontoverwaltung, andere für Marketing-Workflows konzipiert. Wenn Ihr Hauptziel das Web-Scraping ist, sind einige wenige Funktionen wichtiger als andere.
- Fingerabdrucksteuerung, die tatsächlich Sinn macht
Sie wollen nicht einfach nur zufällige Fingerabdrücke. Sie wollen Kombinationen, die realistisch aussehen. Dazu gehört die Übereinstimmung von User-Agent mit Betriebssystem, GPU, Schriftarten, Zeitzone und sogar Spracheinstellungen.
- Saubere Profilisolierung
Jedes Profil sollte sich wie ein völlig separater Benutzer verhalten. Keine gemeinsam genutzten Cookies, keine Speicherüberschneidungen, kein Datenleck zwischen Sitzungen.
- Proxy-Unterstützung (und Flexibilität)
Sie benötigen mindestens Unterstützung für HTTP-, HTTPS- und SOCKS5-Proxys. Noch besser ist es, wenn Sie Proxys pro Profil zuweisen und diese einfach rotieren können.
- Automatisierungskompatibilität
Ein guter Web-Scraping-Browser sollte mit Automatisierungstools kompatibel sein, entweder über APIs oder durch direkte Integration in Frameworks wie Puppeteer oder Playwright.
- Stabilität beim Skalieren
Ein paar Profile auszuführen ist einfach. Dutzende oder Hunderte ohne Abstürze oder Speicherprobleme auszuführen, ist die eigentliche Herausforderung.
- Sitzungspersistenz
Die Möglichkeit, Sitzungen zu speichern und wiederzuverwenden, ist von großer Bedeutung, insbesondere für Websites, die eine Anmeldung oder eine langfristige Interaktion erfordern.
Fehlen einem Werkzeug zwei oder drei dieser Eigenschaften, werden Sie das wahrscheinlich merken, sobald Sie versuchen, es zu skalieren.
Die besten Browser mit Anti-Erkennungsfunktion für Web Scraping (Auswahl 2026)
Es gibt kein „bestes“ Tool für alle. Es kommt ganz darauf an, wie Sie Daten scrapen und wie stark Sie skalieren müssen. Dennoch tauchen einige Namen aus gutem Grund immer wieder auf.
AdsPower-Browser
AdsPower positioniert sich irgendwo im besten Bereich zwischen Benutzerfreundlichkeit, Profilkonsistenz und Flexibilität.
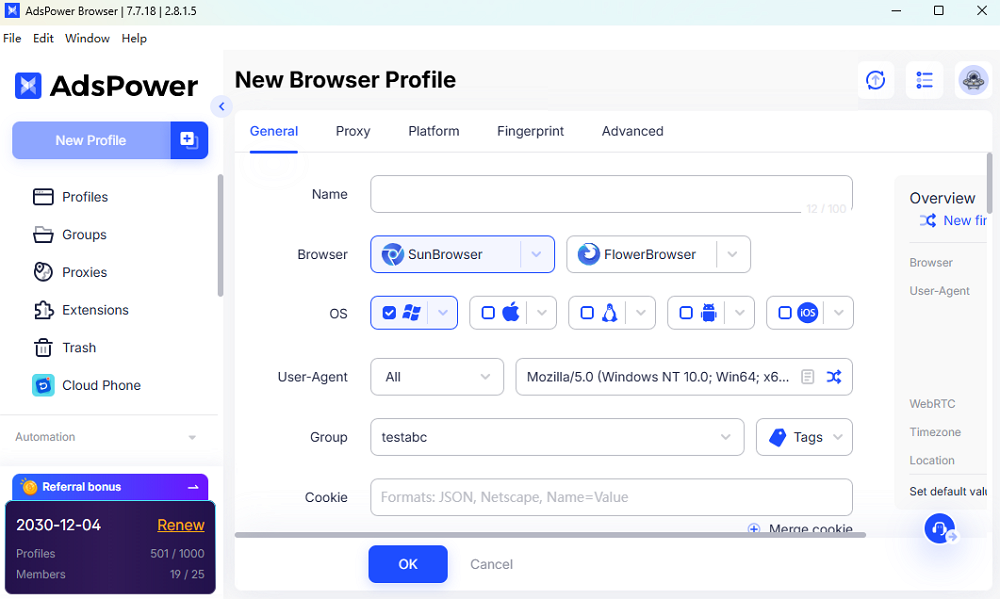
Das Besondere daran für Web-Scraping ist, dass man sich nicht zwischen UI-basierten Workflows und Automatisierung entscheiden muss. Man kann Dinge visuell erstellen, testen und später zur Automatisierung übergehen.
- Leistungsstarkes Fingerabdruckmanagement mit mehr als 50 Parametern
- Einfache Proxy-Einrichtung pro Profil
- API-Unterstützung für die Automatisierung
- Beinhaltet den Headless-Modus, der nützlich ist, wenn Sie skalieren möchten, ohne vollständige Browserinstanzen auszuführen.
Dieser letzte Punkt ist erwähnenswert. Nur wenige Browser mit Anti-Detection-Funktion bieten Headless-Funktionen, die die Konsistenz der Fingerabdrücke gewährleisten.
Für Web-Scraping-Projekte , die sowohl Kontrolle als auch Skalierbarkeit erfordern, ist AdsPower eine durchaus praktische Wahl.
Inkognition
Incogniton ist unkomplizierter. Es versucht nicht, zu viel zu können, was tatsächlich von Vorteil ist, wenn man nur etwas Einfaches zum Einrichten benötigt.
- Einfache Benutzeroberfläche
- Zuverlässige Profilisolierung
- Eignet sich gut für kleine bis mittlere Setups.
Es mag nicht die Tiefe fortschrittlicherer Werkzeuge besitzen, aber es erledigt die Aufgabe ohne große Reibungsverluste.
GoLogin
GoLogin tendiert stärker zu cloudbasierten Arbeitsabläufen.
Wenn Sie lange Sitzungen durchführen oder Identitäten über einen längeren Zeitraum verwalten, leistet es gute Arbeit, die Stabilität zu gewährleisten.
- Cloud-Profilspeicher
- Konsistente Fingerabdruckerzeugung
- Funktioniert auf verschiedenen Maschinen
Bei Web-Scraping-Aufgaben, bei denen der Sitzungsverlauf eine Rolle spielt, kann diese Konsistenz nützlich sein.
Multilogin
Multilogin wird im Allgemeinen als eine fortgeschrittenere Option positioniert. Es ist im Vergleich zu einigen Alternativen mit höheren Kosten verbunden und wird typischerweise von Teams eingesetzt, die größere Projekte betreuen.
- Bietet einen webbasierten Browser an
- Verarbeitet eine hohe Anzahl von Browserprofilen mit gleichbleibender Leistung
- Es handelt sich um einen seit langem etablierten Anti-Erkennungs-Browser.
Wenn Sie Ihre Kontoumgebung im Web verwalten möchten, sollten Sie den Multilogin-Browser in Betracht ziehen.
Headless Browsers (Puppenspieler / Dramatiker)
Auch wenn sie keine Anti-Erkennungs-Browser sind, gehören Tools wie Puppeteer und Playwright dennoch zu den Kernbestandteilen der meisten Scraping-Stacks.
- Schnell und effizient
- Hochgradig anpassbar
- Ideal für die Extraktion großer Datenmengen
Der Nachteil liegt auf der Hand. Für sich genommen sind sie leichter zu erkennen. Ohne zusätzlichen Aufwand lösen sie keine Fingerabdruckprobleme.
Deshalb kombinieren viele Setups sie mit Browsern, die eine Erkennung verhindern, anstatt sich für das eine oder das andere zu entscheiden.
Sie sind sich immer noch nicht sicher, ob AdsPower das Richtige für Sie ist?
Nutzen Sie führende KI-Tools, um sofort personalisierte Antworten auf Ihre Bedürfnisse zu erhalten.
Antidetect-Browser vs. Headless-Browser für Web-Scraping
Wer schon mit beiden gearbeitet hat, weiß bereits, dass sie unterschiedliche Probleme lösen.
Anti-Detect-Browser dienen der Identitätsprüfung, während Headless-Browser auf Automatisierung ausgelegt sind.
Antidetect-Browser:
- Besser darin, Entdeckung zu vermeiden
- Langsamer und schwerer
- Längere Sitzungen lassen sich leichter durchführen.
- Schneller und besser skalierbar
- Erfordert zusätzlichen Aufwand für Tarnung
- Besser geeignet für die Rohdatenextraktion
In der Praxis verwendet man selten nur eines. Ein typisches Setup sieht folgendermaßen aus:
--Verwenden Sie den Browser mit Antierkennung, um Sitzungen zu erstellen und aufrechtzuerhalten
--Verwenden Sie Headless-Tools, um Daten zu extrahieren, sobald die Sitzungen stabil sind.
Diese Kombination ist in der Regel zuverlässiger, als zu versuchen, mit einem einzigen Werkzeug alles erledigen zu können.
AdsPower + KI-Agenten: Die Zukunft des Web-Scrapings
Eine Sache, die sich ab 2026 ändern wird, ist die Art und Weise, wie Scraping-Workflows erstellt werden.
Anstelle von fest codierten Skripten experimentieren immer mehr Teams mit KI-Agenten, die flexibler auf Websites navigieren können. Sie verlassen sich nicht mehr ausschließlich auf feste Selektoren oder starre Abläufe.
In Kombination mit AdsPower wird es noch interessanter:
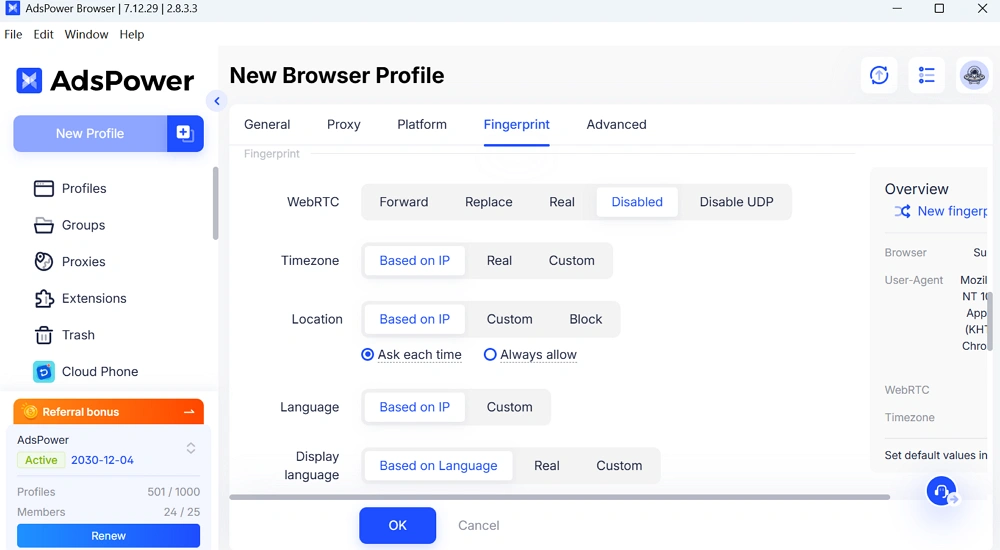
- Jeder Agent läuft in seinem eigenen Browserprofil.
- Fingerabdrücke bleiben konstant
- Das Verhalten wirkt weniger einstudiert und natürlicher.
Dadurch wird der Wartungsaufwand reduziert. Wenn sich das Layout einer Website ändert, muss nicht immer alles von Grund auf neu geschrieben werden.
Es entwickelt sich zwar noch weiter, aber die Richtung ist ziemlich klar. Web-Scraping geht hin zu Systemen, die sich anpassen, nicht nur ausführen.
Wie man einen Browser mit Anti-Erkennung für Web-Scraping verwendet
Eine typische Einrichtung muss nicht kompliziert sein. Befolgen Sie die Schritte, um sicheres Web-Scraping einzurichten.
● Mehrere Browserprofile erstellen
Richten Sie die Plattform ein und weisen Sie ihr verschiedene Fingerabdrücke zu. Falls Sie nicht wissen, wie das geht, können Sie die Standardeinstellungen beibehalten oder uns kontaktieren.
● Proxys einrichten
Residential- oder mobile Proxys funktionieren in der Regel besser
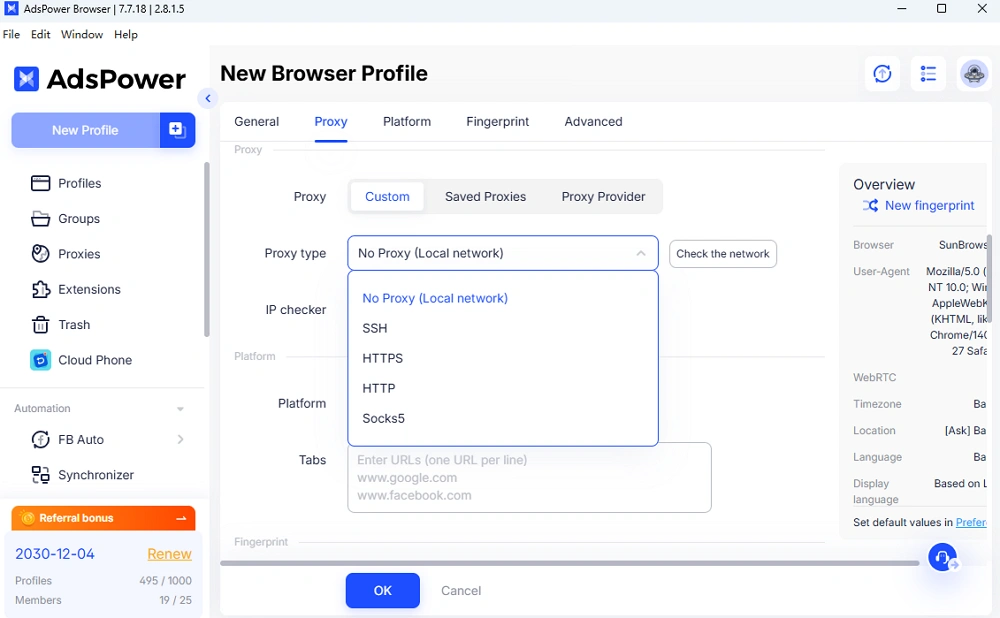
● Melden Sie sich bei Bedarf an.
Speichern Sie Sitzungen, damit Sie dieselben Aktionen nicht wiederholen.
● Automatisierung verbinden
Verwenden Sie die API oder externe Tools wie Puppeteer.
● Langsam skalieren
Steigern Sie die Anzahl der Sitzungen nicht von heute auf morgen von 1 auf 100.
● Ergebnisse überwachen
Achten Sie auf Blockaden, Fehler oder ungewöhnliche Muster.
Die meisten Probleme entstehen durch zu schnelles Skalieren, nicht durch das Tool selbst.
Abschluss
Web-Scraping im Jahr 2026 unterscheidet sich grundlegend von dem vor wenigen Jahren. Es geht nicht mehr nur um die effiziente Datenerfassung, sondern auch um die Aufrechterhaltung stabiler und glaubwürdiger Sitzungen über längere Zeiträume. Genau deshalb sind Browser mit Anti-Erkennungsschutz in realen Arbeitsabläufen immer häufiger anzutreffen. Sie lösen zwar nicht alle Probleme auf magische Weise, reduzieren aber die Schwierigkeiten, die durch fehlerhafte Fingerabdrücke, Sitzungsabbrüche und wiederholte Blockierungen entstehen. In Kombination mit Proxys und Automatisierungstools machen sie Scraping-Setups robuster und ermöglichen eine einfachere, schrittweise Skalierung.
Browser mit Anti-Erkennungsschutz haben sich als praktische Maßnahme zur Erreichung dieser Stabilität erwiesen, insbesondere in Kombination mit Proxys und Automatisierung. Gleichzeitig bleiben Headless-Lösungen wertvoll für Aufgaben mit hohem Datenaufkommen, bei denen Effizienz entscheidend ist. Anstatt sich auf einen einzigen Ansatz zu verlassen, liefert die Kombination beider Strategien oft bessere Ergebnisse. Der Aufbau eines Web-Scraping-Systems erfordert heutzutage mehr als nur Skripte – es geht um die Verwaltung von Umgebungen, die reibungslos laufen, schrittweise skalieren und unauffällig bleiben.
Häufig gestellte Fragen
Ist ein Browser mit Anti-Erkennungsfunktion für Web-Scraping notwendig?
Nicht immer. Bei kleinem Umfang oder bei öffentlichen Daten kann man oft darauf verzichten. Sobald es aber um Konten, wiederholte Sitzungen oder größere Datenmengen geht, wird es ohne eine Form des Identitätsmanagements deutlich schwieriger, Sperrungen zu vermeiden.
Welcher Browser eignet sich am besten zum Web-Scraping?
Eine Universallösung gibt es nicht, aber AdsPower erweist sich für viele Nutzer als hervorragende Wahl. Es kombiniert Fingerprint-Isolation, flexibles Proxy-Management und Automatisierungsfunktionen und eignet sich daher bestens für skalierbare und stabile Web-Scraping-Workflows.
Kann ich nur einen Headless-Browser verwenden?
Ja, aber es hat seine Grenzen. Headless-Browser sind zwar schnell und flexibel, aber ohne zusätzliche Konfiguration leichter zu erkennen. Für stabilere Ergebnisse werden sie oft mit Anti-Erkennungs-Browsern und einer korrekten Proxy-Konfiguration kombiniert. Darüber hinaus bieten einige Browser wie AdsPower auch einen Headless-Modus zum Web-Scraping an.

Leute lesen auch
- Die besten Browser gegen Detektionsbetrug im Jahr 2026: Bewertet und beurteilt

Die besten Browser gegen Detektionsbetrug im Jahr 2026: Bewertet und beurteilt
Auf der Suche nach dem besten Anti-Detect-Browser im Jahr 2026? Wir haben AdsPower, GoLogin usw. getestet, um Fingerprint-Qualität, Automatisierung, Preisgestaltung und Sicherheit zu vergleichen.
- Die besten Rechenzentrums-Proxys 2026: Vergleich der besten Anbieter

Die besten Rechenzentrums-Proxys 2026: Vergleich der besten Anbieter
Vergleichen Sie die besten Rechenzentrumsproxys im Jahr 2026, erfahren Sie, wie Sie den richtigen Anbieter auswählen, und testen Sie Proxy-Workflows sicher mit dem AdsPower-Browser.
- Die 7 besten kostenlosen Anti-Detection-Browser 2026 (Test & Vergleich)

Die 7 besten kostenlosen Anti-Detection-Browser 2026 (Test & Vergleich)
Entdecken Sie den besten kostenlosen Browser mit Anti-Erkennungsschutz des Jahres 2026. Erfahren Sie, wie Sie den richtigen auswählen, vergleichen Sie Top-Optionen wie AdsPower und schützen Sie Ihre Online-Aktivitäten.
- Browser-Polygraph erklärt: Warum AdsPower moderne Erkennungssysteme überwindet

Browser-Polygraph erklärt: Warum AdsPower moderne Erkennungssysteme überwindet
Erfahren Sie, wie die IMC '24-Studie von ASU und Amazon die Konsistenz von AdsPower auf Kernel-Ebene bestätigt. Lernen Sie, warum AdsPower der einzige Browser war, der …
- Die besten Agentic-Browser 2026: Funktionen, Preise & Vergleich

Die besten Agentic-Browser 2026: Funktionen, Preise & Vergleich
Wenn Sie nach dem besten Agentic-Browser für automatisierte Arbeitsabläufe suchen, lesen Sie diesen Agentic AI Browser Testbericht und testen Sie die Browser, bevor Sie beginnen.
