
Amazon Scraper の使用方法に関する詳細ガイド
Amazonのウェブスクレイピングは、賢く行えば企業にとって非常に収益性の高いものになり得ます。信じられないですか?では、 Amazonのレビューを毎日スクレイピングするだけで、わずか2ヶ月で80万ドルもの驚異的な収益を上げたウェブサイトの事例を考えてみてください。すごいでしょう?
一夜にして大金持ちになれるとは約束できませんが、Amazonからデータをスクレイピングして、その目標に近づく方法をお教えすることはできます。
そこで、このブログを読んで、Amazonからデータをスクレイピングする2つの方法を学びましょう。1つはノーコードでAmazonスクレイパーを作成する方法、もう1つはコードを使ってPythonでAmazonスクレイパーを構築する方法です。
しかしその前に、Amazonからデータをスクレイピングしても問題ないかどうかを確認しましょう。
Amazonのデータをスクレイピングすることは合法ですか?
Amazonのウェブサイトをスクレイピングする場合、ルールはやや曖昧です。Amazonのrobots.txtファイルには、スクレイピング可能な項目と厳しく禁止されている項目を詳細にリストアップした、許可されているスクレイピングパラメータが記載されています。
しかし、robots.txtファイルはあくまで倫理的なガイドラインであり、法的拘束力はありません。そのため、Amazonスクレイパーは必ずしも問題なく、アクセス制限のある領域にアクセスできる可能性があります。
しかし、アマゾンはそれだけにとどまらない。さらに一歩進んで、ボットによるサーバーへの過負荷を防ぐための技術的な障壁を導入している。
例えば、CAPTCHAテストやレート制限などのスクレイピング対策を採用しています。これらの障害を克服するには、Amazonスクレイパーは ユーザーエージェントのなりすまし、 CAPTCHAの回避、リクエストの遅延といった高度なテクニックを用いなければ、Amazonスクレイピングの試みは夢のままで終わってしまうでしょう。
したがって、 「Amazonはウェブスクレイピングを許可していますか?」という質問に簡潔に答えると、Amazonデータのウェブスクレイピングの合法性は明確ではなく、以下のようなさまざまな要因に依存します。
-
スクレイピングされたデータの種類
-
スクレイピングに使用される方法
-
そして、スクレイピングしたデータの目的
スクレイピングが、ログインが必要なデータへの不正アクセスや、サイトのインフラへの過負荷を伴わない限り、通常は安全なカテゴリーに分類されます。最高裁判所はまた、不正なウェブスクレイピングを理由にLinkedInからCFAA(コンピュータ詐欺および濫用防止法)に基づいて訴えられたデータ分析会社を擁護しました。
さらに、スクレイピングしたデータの使用が合法であることを確認する必要があります。つまり、データを再販したり複製したりしてはいけません。そうすると、深刻な法的影響が生じる可能性があります。
さて、ここで重要な問題が浮かび上がります。アマゾンからデータをスクレイピングするにはどうすればいいのでしょうか?
Amazonのデータをスクレイピングする方法は?
技術的な課題はあるものの、Amazonからのデータスクレイピングは比較的容易です。Amazonのボット対策に対応したコードベースおよびノーコードベースのスクレイピングツールが多数存在し、これらのツールを使えば、Amazonのレビュー、商品、価格などのデータを簡単に取得できます。
それではまず、ノーコードで使えるAmazonスクレイパーから始めましょう。
ノーコードAmazonスクレイパー:
正直に言って、この記事を読んでいる読者のほとんどはプログラミングスキルを持っていない可能性が高いでしょう。しかし、それは問題ありません。ノーコードのAmazonスクレイパーが利用できるので、プログラミングの知識は必要ありません。
これらのツールを使えば、商品ページまたはカテゴリページのURLを入力するだけで、スクレイパーがそのページからAmazonの商品データをすべて取得してくれます。Amazonのウェブスクレイピングが完了すると、複数のファイル保存オプションも提供されます。
今回のデモでは、ApifyのAmazonスクレイパーを選択しました。Apifyには、Amazonのさまざまな領域をスクレイピングするためのツールがそれぞれ用意されており、Amazon商品スクレイパー、Amazonレビュースクレイパー、Amazonベストセラースクレイパーなどがあります。
このガイドでは、ApifyのAmazon Product Scraperを使用します。Amazon Product Scraperには、CAPTCHAを解決したり、プロキシを設定してボット対策を回避する機能が備わっています。
それではデモを始めましょう。
ステップ1:Amazonの商品スクレイパーページにアクセスする
ApifyストアでAmazonプロダクトスクレイパーにアクセスし、「無料で試す」ボタンをクリックしてください。このツールを使えば、価格、レビュー、商品説明、画像など、Amazonの商品データをスクレイピングできます。 
ステップ2:Apifyアカウントを作成する
初めての方は、Apifyアカウントを無料で作成してください。登録方法は、メールアドレス、Googleアカウント、GitHubアカウントから選択できます。 
ステップ3:対象コンテンツのAmazon URLを貼り付ける
Apifyコンソールで、スクレイピングしたいAmazonの商品またはカテゴリのURLを入力します。この例では、 「ビデオゲーム機・周辺機器」と「 家具」カテゴリを使用しています。
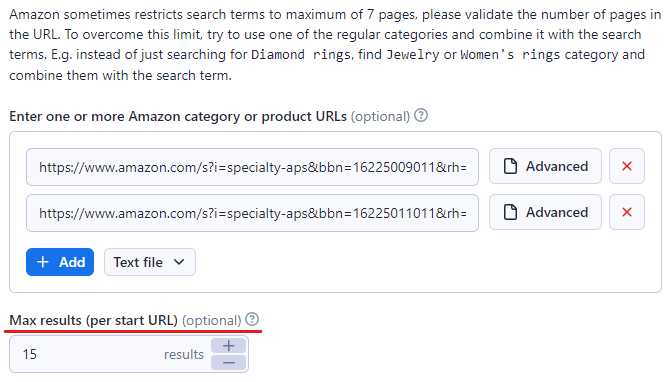
「+追加」ボタンを押すと、さらにリンクを追加できます。リンクがたくさんある場合は、すべてをテキストファイルにまとめてAmazonスクレイパーにアップロードすることもできます。
また、「最大アイテム数」欄で制限値を設定して、スクレイピングするアイテムの最大数を決めましょう。ここでは15に設定していますが、お好きなだけ高く設定できます。
ステップ4:CAPTCHAソルバーを有効にする
CAPTCHAソルバーなしではAmazonからデータをスクレイピングすることはできません。Amazonはボットの検出に非常に優れていることで知られています。ボットの活動を疑うとすぐに、ボットに対してCAPTCHA認証を要求します。
Amazonスクレイパーが問題なく動作するように、CAPTCHA認証を有効にしてください。 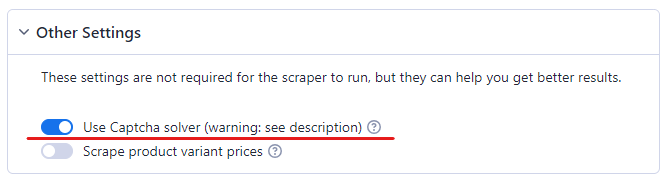
ステップ5:プロキシの設定
プロキシを使用することは、スクレイピング対策を回避するために不可欠です。Amazonスクレイパーは、スクレイピング活動を隠蔽し、制限を回避するために、レジデンシャルプロキシ、データセンタープロキシ、または独自のプロキシなど、さまざまなプロキシオプションを提供しています。 レジデンシャルプロキシとデータセンタープロキシの違いについては、別のブログ記事をご覧ください。
住宅用プロキシオプションは、スクレイピング対策システムにとって最適であるため、デフォルトで選択されています。 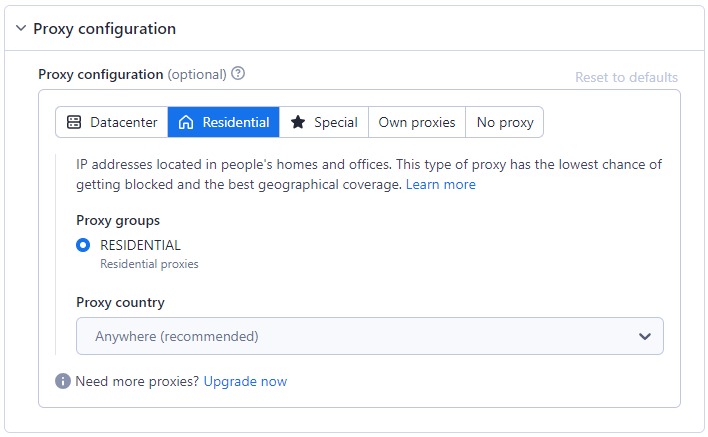
ステップ6:スクレイパーを起動する
パラメータを設定したら、ページ下部の「開始」ボタンを押してAmazon商品スクレイパーを起動してください。
完了すると、ステータスが「実行中」から「成功」に変わります。
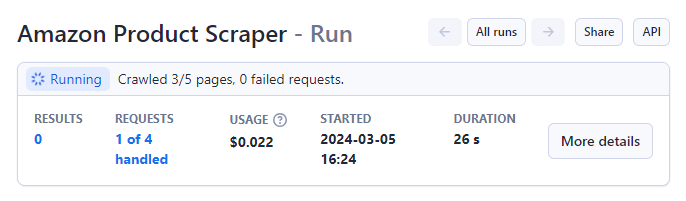
処理が完了すると、画面にデータのプレビューが表示されます。
ステップ7:ファイルをエクスポートする
収集したデータをダウンロードするには、「結果をエクスポート」ボタンを押してください。このプラットフォームは、CSV、JSON、Excelなど、複数のフォーマットに対応しています。 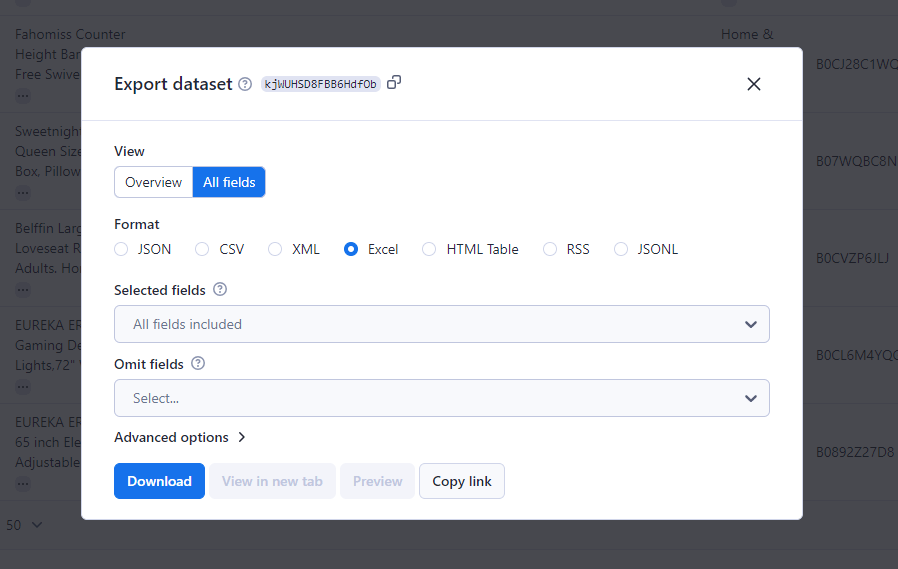
Pythonを使ったAmazonスクレイピング
上記で使用したノーコードのAmazonスクレイパーでは、前述のステップ6をよく見ると、173件のリクエストのうち69件が失敗しています。これは、Amazonがこれらのリクエストをブロックしているためです。
この問題を回避するには、独自のスクレイピングスクリプトを作成する必要があります。このガイドでは、Pythonを使用してAmazonの商品情報を取得するスクレイパーを作成します。
それでは始めましょう。
ステップ1:Pythonをインストールする
PythonでAmazonスクレイパーをコーディングするには、コンピュータにPythonがインストールされている必要があります。必要なライブラリとの互換性を確保するため、 最新バージョンまたは最近リリースされたバージョンをダウンロードすることをお勧めします。
ステップ2:必要なライブラリのインポート
Amazonスクレイパーの核心は、ウェブコンテンツの取得と解析にあります。そのためには、複数のPythonライブラリを組み合わせて使用します。
-
リクエスト: AmazonのウェブサイトにHTTPリクエストを行うためのリクエスト
-
BeautifulSoup:返されたHTMLコンテンツをナビゲートおよび解析する
-
lxml:解析用
-
Pandas:データの整理とエクスポートに
インポートする前に、以下のコマンドを使用してインストールする必要があります。
それでは、それらをAmazonスクレイピング用のPythonスクリプトにインポートします。
ステップ3:HTTPヘッダーの設定
Amazonのウェブスクレイピングにおける一般的な障害は、Amazonの自動アクセスに対する防御策です。これを回避するため、当社のAmazonスクレイパーPythonスクリプトは、次のようなカスタムHTTPヘッダーを含めることで、ウェブブラウザのリクエストを模倣します。 「User-Agent」と「Accept-Language」。
ヘッダーをもっと追加する方が良いでしょう。
お使いのブラウザでこれらのヘッダーを取得するには、
-
AmazonのページでF12キーを押して開発者ツールを開きます。
-
ネットワークタブを開き、ヘッダーを選択します。
-
ページを再読み込みしてください。
-
最初のリクエストを選択してください
-
ヘッダータブで、リクエストヘッダーセクションまでスクロールダウンし、上記で説明したヘッダーの値をコピーします。
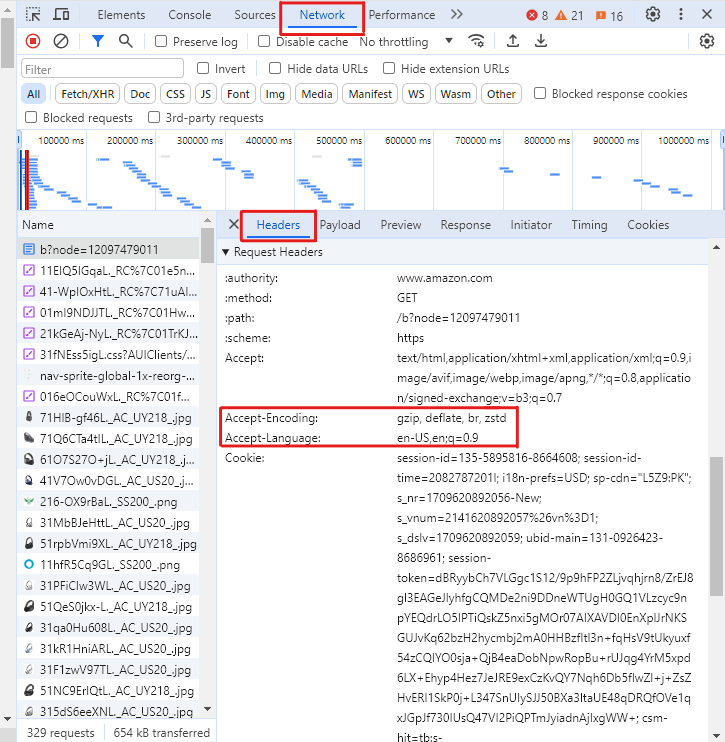
これらのヘッダーがない場合、Amazon が GET リクエストをブロックし、ステータスコード 200 (成功) の代わりに 503 (エラー) のようなレスポンスを返す可能性が高くなります。
ステップ4:製品情報の抽出
当社のAmazon商品スクレイパーには、商品詳細を抽出するという重要なタスクを実行する関数scrape_amazon_productが含まれています。この関数は、AmazonのカテゴリページのURLを入力として受け取り、商品の情報を含む辞書を返します。
このメソッドは、上記で作成したURLとカスタムヘッダー変数を使用して、Amazonにリクエストを送信します。
その後、BeautifulSoupのCSSセレクターを使用して、個々の商品ページから商品のタイトル、価格、画像URL、および説明を取得します。
ステップ5:商品リストとページネーションの処理
Amazonのスクレイピング用Pythonスクリプトは、カテゴリページを移動し、ページネーションを処理することで大量のデータを収集するため、Amazonの商品一覧ページをナビゲートします。
CSSセレクタを使用して商品リンクを識別し、「次へ」ページリンクを検出することでページネーションに対応します。
ステップ6:スクレイピングしたデータの保存
最後に、スクレイピングされたデータは辞書のリストに集約され、それがPandas DataFrameに変換されます。そして、このDataFrameはCSVファイルとしてエクスポートされます。
Amazonスクレイパーをステルスで使用する
Amazonのスクレイピングは通常は簡単です。しかし、CAPTCHA認証、リクエストブロック、レート制限など、複数の課題に直面する可能性があります。
こうした問題に遭遇しないようにするには、 AdsPowerのような検出回避ブラウザを使用することをお勧めします。AdsPowerは、フィンガープリントの偽装やプロキシのローテーションといった機能を提供することで、Amazonスクレイパーが検出されないようにします。
それで サインアップ 今すぐ無料で登録して、Amazonからのデータスクレイピングをスムーズに始めましょう。

他にも読む記事
- 学校でブロックされない人気ゲーム12選(+簡単な解決策)
")
学校でブロックされない人気ゲーム12選(+簡単な解決策)
学校でプレイできる人気のブロック解除済みゲーム12選を発見し、ブロックされたゲームサイトにアクセスする実用的な方法を学び、AdsPowerがゲームブラウザの安全性をどのように確保するかをご覧ください。
- 2026年に複数のAppleアカウントを安全に管理する方法

2026年に複数のAppleアカウントを安全に管理する方法
実践的なヒントを通して、複数のAppleアカウントを安全に管理する方法を学びましょう。
- Substackで収益を上げる方法 2026年版:クリエイターのための収益戦略

Substackで収益を上げる方法 2026年版:クリエイターのための収益戦略
Substackで収益を上げたいですか?このガイドでは、実績のある収益化方法、成長のためのヒント、そしてクリエイターがコンテンツを収入に変える方法を詳しく解説します。
- Claudeがダウンしている、またはClaudeに連絡が取れない?よくある問題の診断と解決方法

Claudeがダウンしている、またはClaudeに連絡が取れない?よくある問題の診断と解決方法
Claudeがダウンしている、または「Claudeに接続できません」というエラーが表示されていますか?ログインループ、認証エラー、ネットワークの問題などを解決する方法を学びましょう。
- Instagramアカウントがロックされて、その後BANされてしまった?どうすれば元に戻せる?

Instagramアカウントがロックされて、その後BANされてしまった?どうすれば元に戻せる?
Instagramでアカウントがロックされ、その後停止されてしまった?このガイドでは、一時的にロックまたは無効化されたアカウントの対処法と復旧方法について解説します。
