
Instagramのスクレイピング方法とは?スクレイピングの効果を最大限に引き出す3つの方法
13億のユーザーを抱えるInstagramは、企業にとって貴重なデータの宝庫です。市場調査、リードジェネレーション、パフォーマンスモニタリングに活用できます。しかし、Instagram からこのデータを取得するのは難しい部分です。
この手順は簡単ではなく、Instagram のポリシーや技術的な曖昧さにより、多くの複雑な点があります。
このガイドでは、低コーディング、高コーディング、そしてノーコーディングの3つの方法を紹介することで、Instagramをスクレイピングする方法について説明します。
Instagram のスクレイピングは合法ですか?
「Instagram のスクレイピングは合法ですか?」という質問に対する答えは、状況に応じて「はい」と「いいえ」が同時に存在します。スクレイピングするデータの種類によって異なります。Instagram から公開されているデータをスクレイピングしたい場合は、答えは「はい」です。
ただし、Instagramにログインする必要があるプライベートデータを取得するためにInstagramをスクレイピングする場合は、明示的に禁止されており、違反するとアカウントが停止され、最悪の場合、法的措置が取られる場合があります。ただし、公開データの場合でも、スクレイピングは合法的な方法で行う必要があります。
Instagram から合法的なデータを取得するには、Instagram が提供する API を使用できます。これらには、Instagram Graph API と Instagram Basic Display API が含まれます。
Graph API を使用すると、ビジネス アカウントとクリエイター アカウントに関するデータを管理および抽出できます。一方、Basic Display API では読み取り専用となります。基本的なユーザー情報へのアクセス。これらの API はどちらも Instagram のスクレイピングに関するポリシーに準拠しているため、これらを使用して Instagram をスクレイピングすることは完全に合法です。
ただし、非公開APIを使用したり、事前の許可なくプラットフォームにアクセスしたり、多くの場合は偽装したりする不正な手段を使用したりすると、スクレイパーを一般ユーザーとして見せかけると、不正スクレイピングに該当し、Instagram の利用規約。
Instagram のスクレイピングを始める前に、一歩引いて「Instagram はスクレイピングを許可しているのか」を考え、慎重に行うようにしてください。
簡単にスクレイピングできるInstagramデータはどれですか?
Instagram からデータをスクレイピングする方法を説明する前に、まずはプラットフォームから合法的にスクレイピングできるデータについて確認しましょう。Instagram の合法的なウェブ スクレイピングでは、次の 3 つのカテゴリのデータにアクセスできます。
-
ハッシュタグ: キャプションに特定のハッシュタグが付けられた、最もパフォーマンスの高い、または最近の写真や動画を取得できます。
-
プロフィール: 投稿数、メディア数、フォロワー数/フォロー中数などのプロフィールデータを取得できます。
-
投稿: コメント数、いいね数、プロフィールID、公開日、URLなどの指標を取得できます。
Instagram をスクレイピングする 3 つの方法
Instagram をスクレイピングする方法は 3 つあります。ニーズとリソースに合った方法を選んでください。
Instagram API を使用した Instagram のスクレイピング
Instagram をスクレイピングする方法について、ステップバイステップで解説します。ただし、まず以下の要件を満たしていることを確認してください。
-
Instagram ビジネス/クリエイターアカウント
-
Instagram ビジネス/クリエイターアカウントにリンクされた Facebook ページ
-
Instagram Graph API を使用するための Facebook Developer アカウント
-
最低限の設定で登録済みの Facebook アプリの設定
これらの前提条件が完了したら、次の段階は次のようになります。
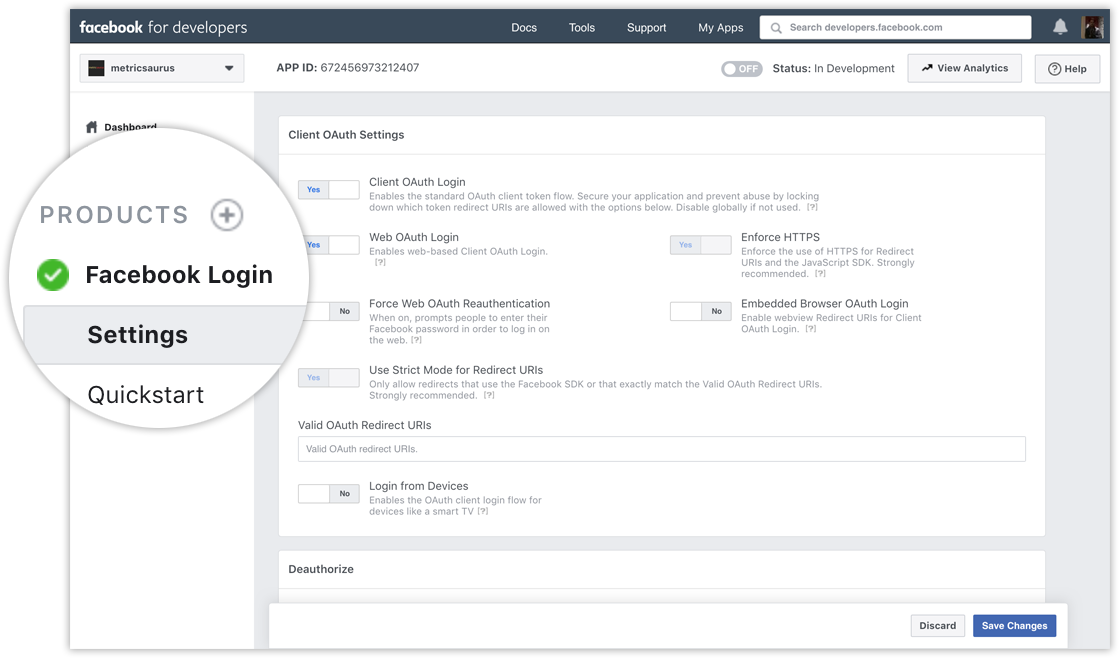
Facebook ログイン機能の追加:
Facebook アプリのダッシュボードに移動し、画面左側のパネルにある「商品 +」ボタンをクリックします。 ;ウィンドウに表示されます。そこから Facebook ログイン製品を追加します。今のところ、この製品の設定を変更せず、デフォルトのままにしておきます。
次に、Facebookログインドキュメントを確認し、ログイン手順で以下の2つの基本的な権限を要求していることを確認してください。
アクセストークンの生成:
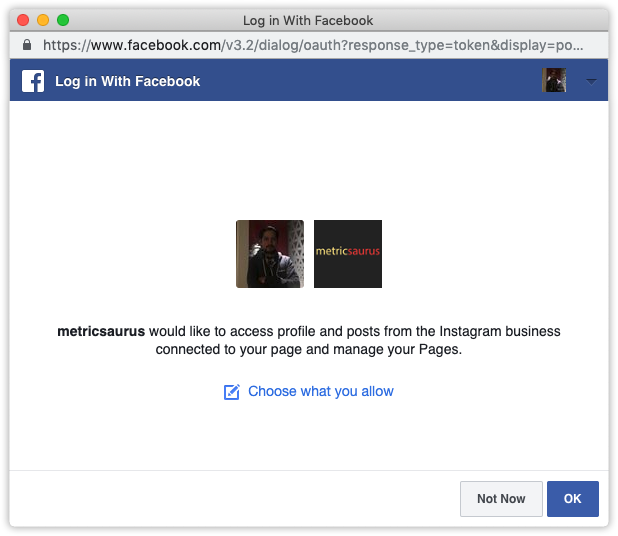
Instagram アカウントのアプリダッシュボードから操作を実行するには、ユーザーアクセストークンが必要です。ダッシュボードページの右側で、ユーザーまたはページドロップダウンから「ユーザーアクセストークンを取得」を選択します。
ポップアップ ウィンドウが表示され、アプリ (この場合はあなたのアプリ) が上記の権限を求めていることが通知されます。 「続行」または「OK」ボタンを押すだけで、ダッシュボードの「アクセストークン」フィールドにユーザーアクセストークンが表示されます。
ユーザーアクセストークンを使用して、Instagram アカウントでいくつかの基本的なクエリを実行します。
1. Facebook ページ ID を取得します:
まず、Instagram ビジネスアカウントに紐づけられている Facebook ページの ID が必要です。そのためには、ダッシュボードで以下の Get クエリを実行します。
|
"https://graph.facebook.com/v19.0/me/accounts?access_token={access-token}" |
これは、Facebookユーザーに属するFacebookページの名前とIDを返します。出力は次のようになります。
Instagram ビジネスアカウントにリンクされているページの ID をコピーします。
2. InstagramビジネスアカウントIDを取得します:
Facebook IDを使用する場合は、コマンドバーに以下のスクリプトを入力し、「送信」を押します。
以下の出力が得られます。
3. Instagram アカウントのメディアオブジェクトを取得する:
出力からInstagram IDをコピーし、以下のスクリプトを実行して、Instagramビジネスアカウントに現在投稿されているすべてのストーリーのIDを取得します。
出力には各ストーリーのIDが含まれます。
これはほんの一例です。Instagram Graph API を使用すると、Instagram ユーザーのメタデータなどの他の情報を取得したり、ハッシュタグ検索を実行したりすることもできます。
では、Instagram からデータをスクレイピングする別の方法に移りましょう。
コード不要のクラウド スクレイパーを使った Instagram のスクレイピング
コーディングの経験がない人にとって、上記の方法は理解するどころか実行するのさえ難しいかもしれません。しかし、心配しないでください。コードを必要とせずに作業を完了する Instagram スクレーパーが存在します。
ここでは、Apify。
Apify Instagram Scraper ページに移動します:
Apify Instagram Scraper ページを開き、無料トライアルボタンをクリック

メールアドレス、Google アカウント、または GitHub アカウントを使用して Apify にサインアップしてください。サインアップすると、実際の Instagram スクレイピングが行われる Apify コンソールに移動します。
対象のInstagram URLを収集:
Instagram アプリまたはウェブサイトを使用して、スクレイピングする Instagram アカウントのすべてのプロフィール URL を収集します。Apify コンソールで、これらの URL をすべて、指定された入力欄に 1 つずつ貼り付けてください。一度にすべて入力するには、「一括編集」ボタンをクリックします。
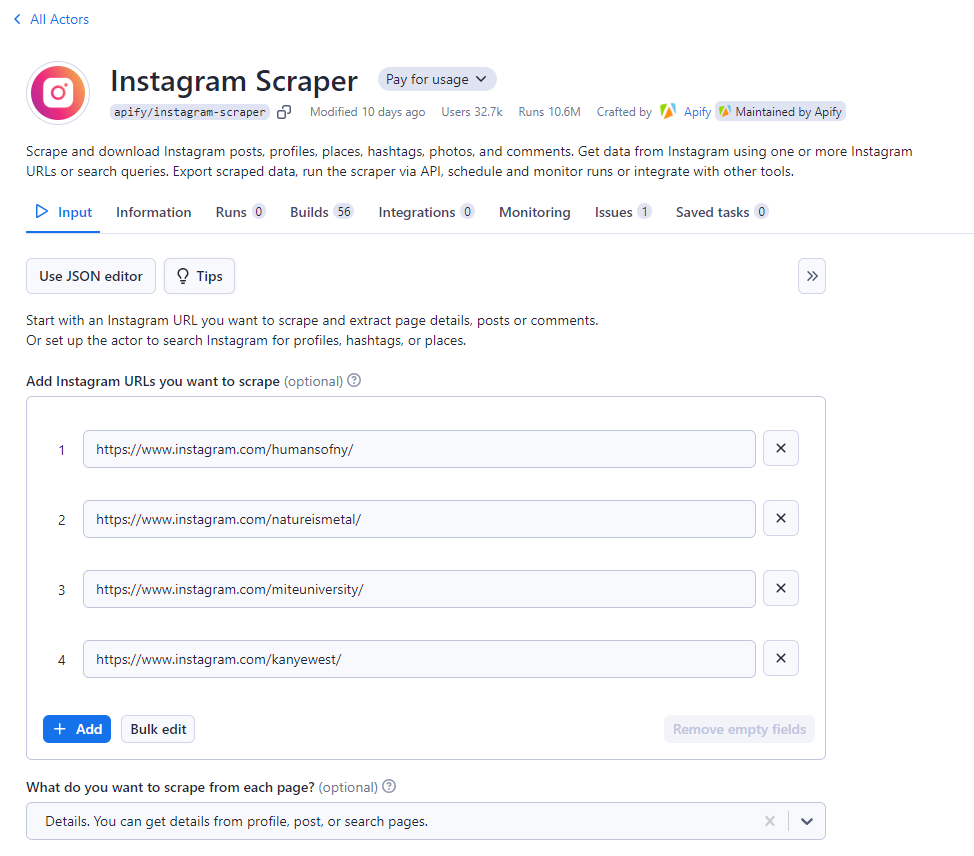
Apify は、提供された URL に対して 3 つのスクレイピング オプションを提供しており、投稿やコメントをスクレイピングしたり、プロフィールからさまざまな詳細情報を取得したりできます。
「保存して開始」をクリックします:
残りの設定はそのままにして、[保存して開始] をクリックしてスクレーパーを実行します。結果は、指定した数と同じ行を含む表の形式になります。経歴、フォロワー数、投稿数、リール数、アカウント ID、認証ステータスなどのプロフィール メタデータを含む複数の列を含むプロフィール URL を、いくつか挙げてください。

結果の保存:
「結果をエクスポート」ボタンを押し、ポップアップウィンドウから必要なファイル形式を選択します。また、以下を選択してデータをクリーンアップすることもできます。必要のないフィールドは省略します。その後、結果をダウンロードして新しいタブで表示したり、リンクを通じて共有したりすることができます。

プログラミング言語を使ったInstagramのスクレイピング
要件が非典型的で、しっかりとしたプログラミング言語を持っている場合、独自のInstagramスクレイパーを構築することが最も効率的なソリューションになる可能性があります。高度な知識、またはチーム内に開発者がいれば、Web スクレイピング フレームワークと組み合わせた任意のプログラミング言語を使用してこれを実行できます。
このガイドでは、Python とブラウザ自動化フレームワークである Selenium を使用して Instagram をスクレイピングする方法を説明します。
必須ライブラリのインポート:
まず、Selenium、そのWebドライバー、そして検出を防ぐためのSelenium-Stealthなどの基本ライブラリをインポートします。
pprintライブラリは、出力をきれいに印刷して読みやすさを向上させるのに役立ちます。
Instagramユーザー名を収集:
ターゲットとするInstagramプロフィールのリストを作成し、ユーザー名を追加します。
出力変数は、結果を保存するために使用する辞書です。
メイン関数を定義します。
メイン関数は、ユーザー名リストを一度に1つずつスキャンし、ユーザー名ごとにスクレイピング関数を呼び出します。
ブラウザ設定を管理する関数を定義します:
この機能は、スクレイピングリクエストの前にブラウザ設定を調整し、匿名性を高めてInstagramによる検出を回避します。これらの変更には、プロキシのローテーション、Selenium-Stealth設定の構成、人工ユーザーエージェントの作成が含まれます。
スクレイピング用の関数を定義します:
メイン関数で呼び出されるscrape()関数は、単一のInstagramユーザー名を引数として受け取り、 Chrome ブラウザを使用して、prepare_browser() 関数を通じて作成されたリクエストを送信するために使用するプロファイル エンドポイントです。
リクエストのステータスも確認します。リクエストがログインページにリダイレクトされた場合は、リクエストが失敗したことを意味します。一方、ログイン文字列がなかった場合、リクエストは成功し、結果は JSON として解析され、ユーザー名とともに parse_data() 関数に送信されます。
parse_data() 関数を定義します:
この関数は、user_data 引数の JSON データを解析して、必要なデータ フィールドを取得します。この例では、ユーザーのフルネーム、アカウント カテゴリ、フォロワー数、投稿のキャプションをスクレイピングしています。
ドライバーコードを記述します:
ドライバーコードはスクレイピングプロセスを開始し、データを出力変数に抽出し、pprint()関数を呼び出して、それを見やすい形式で表示します。
AdsPower Antidetect ブラウザで検出を回避
Instagramはスクレイピングに関しては厳格であり、プラットフォーム上の公開データへのアクセスを非常に制限しています。これには、プロフィールID、フォロワー数、いいね数、コメント数など。それ以上深く調べるにはログインが必要で、Instagramのポリシーに違反し、アカウントが停止される可能性があります。
Instagram からデータをスクレイピングする際に、Instagram のポリシーに違反する可能性のある低プロファイルを維持するのに役立つ AdsPower が役立ちます。AdsPowerは、IPローテーションやレート制限などのアンチスクレイピング技術を使用してアンチスクレイピング対策を回避します。
次にノーコードツールや非公式の Instagram API を使用して Instagram をスクレイピングするときは、必ずAdsPower antidetect ブラウザを使用して、検出を回避してください。
結論
Instagram は、プラットフォーム上で公開されているデータのみのスクレイピングを許可しており、そのために 2 つの API を提供しています。しかし、これらの API は、Instagram から実際に関連性の高いデータを取得することなく、非常に基本的なレベルのスクレイピングを提供します。
これにより、サードパーティのウェブスクレーパーを使用するか、プログラミング言語を使用して独自のスクレーパーを作成することになります。ただし、Instagramをスクレーピングすることはこれらの非公式な方法は検出される可能性があるため、保護を強化するためにAdsPower AntiDetectブラウザを必ず使用してください。

他にも読む記事
- 【Webスクレイピングにおすすめ】最強ヘッドレスブラウザ10選|メリット・デメリットも比較

【Webスクレイピングにおすすめ】最強ヘッドレスブラウザ10選|メリット・デメリットも比較
Webスクレイピングに最適なヘッドレスブラウザを見つけましょう。通常のブラウザとの違いや、効率的なデータ収集のための軽量な選択肢も解説します。
- パブリッシャー向けおすすめネイティブ広告プラットフォーム|収益化を加速させる8選

パブリッシャー向けおすすめネイティブ広告プラットフォーム|収益化を加速させる8選
パブリッシャー(媒体社)に最適なネイティブ広告プラットフォームを紹介します。ネイティブアドの最適化手法や、AdsPowerを活用してトラフィックと収益を最大化する方法も解説します。
- 学校や職場でも利用できる、ブロック解除済みの最高の音楽ウェブサイト(2026年版)

学校や職場でも利用できる、ブロック解除済みの最高の音楽ウェブサイト(2026年版)
学校や職場でもブロックされずに利用できる、最高の音楽ウェブサイトを見つけよう。
- 初心者向けRedditで見つける最高の不労所得アイデア(2026年版ガイド)

初心者向けRedditで見つける最高の不労所得アイデア(2026年版ガイド)
不労所得のアイデアをお探しですか?Redditユーザーが2026年に稼ぐ5つの実証済みの方法をご紹介します。
- Instagramストーリーズを匿名で閲覧することは可能ですか?2026年版完全ガイド

Instagramストーリーズを匿名で閲覧することは可能ですか?2026年版完全ガイド
2026年にInstagramストーリーズを匿名で閲覧する方法を学び、プライバシーと閲覧ニーズに最適な方法を見つけましょう。
