
Cele mai bune instrumente de scraping web pentru 2026: Un ghid pentru extragerea de date de volum mare
Aruncă o privire rapidă
Scalarea extragerii datelor web introduce blocaje, CAPTCHA-uri și instabilitate. Succesul necesită gestionarea amprentelor digitale, a sesiunilor și a infrastructurii folosind combinația potrivită de instrumente pentru extragerea datelor fiabilă și nedetectată. Urmăriți-ne pentru a încerca!
Dacă ai parcurs doar câteva pagini până acum, poate părea surprinzător de ușor. Un script simplu, poate un proxy implementat, iar datele ajung fără prea multă rezistență. Pentru sarcini mici, lucrurile tind să funcționeze suficient de lin încât aproape că par fără efort. Dar acest sentiment de control nu durează mult odată ce începi să insisti asupra unui volum mai mare.
De îndată ce treci la scraping la scară largă, totul devine mai puțin previzibil. Cererile încep să fie blocate, sesiunile nu se mențin, iar modul de a evita CAPTCHA în scraping-ul web devine rapid o problemă reală, mai degrabă decât un caz limită. Ceea ce a funcționat bine pe un lot mic începe să încetinească sau să se defecteze complet. În acel moment, scraping-ul nu mai înseamnă doar extragerea de HTML, ci și gestionarea identităților, gestionarea paginilor dinamice și menținerea stabilității sistemului sub presiune constantă. Acest ghid se concentrează asupra a ceea ce rezistă de fapt în aceste condiții și de ce atât de multe configurații eșuează înainte de a ajunge la acel nivel.
De ce majoritatea instrumentelor de scraping web eșuează la scară largă
Cea mai mare concepție greșită în ceea ce privește extragerea de date web este ideea că succesul la scară mică se traduce prin fiabilitate la scară largă. Nu este așa.
Iată unde se strică de obicei lucrurile:

- Blocarea IP-urilor escaladează rapid
Câteva solicitări pe minut? Bine. Mii pe oră? Vei fi semnalat rapid.
- Detectarea amprentelor digitale depășește IP-urile
Site-urile web moderne nu doar urmăresc adresa IP, ci analizează amprentele browserului, modelele de comportament și consecvența sesiunilor.
- Conținutul dinamic complică totul
Site-urile web cu conținut ridicat de JavaScript necesită randare completă în browser. Cererile HTTP simple nu mai sunt suficiente.
- CAPTCHA-urile perturbă fluxurile de lucru
La scară largă, provocările CAPTCHA nu sunt ocazionale, ci constante.
- Întreținerea devine un job cu normă întreagă
Modificările de aspect, actualizările anti-boți și limitele de viteză obligă la ajustări continue.
Pe scurt, scraping-ul la scară largă nu este doar o problemă de codare. Este o problemă de infrastructură și de stealth.
Tipuri de instrumente de scraping web
Alegerea instrumentului potrivit depinde de abilitățile tehnice, cerințele de volum și toleranța la întreținere. Să analizăm principalele categorii.
1. Cadre de lucru bazate pe cod
Practic, aceasta este calea DIY. Dacă ați construit vreodată un scraper de la zero, probabil că de aici ați început. Vă oferă control deplin, dar înseamnă și că sunteți responsabil pentru tot.
Cel mai potrivit pentru:
- Dezvoltatori care vor să controleze fiecare detaliu
- Proiecte care nu se încadrează în instrumente prefabricate
- Logică de scraping mai complexă
Avantaje:
- Poți personaliza aproape orice
- Ușor de conectat la propriile sisteme
- Control deplin asupra modului în care datele sunt colectate și procesate
Contra:
- Necesită codare (evident)
- Întreținerea poate deveni murdară în timp
- Probabil veți avea nevoie de instrumente suplimentare pentru proxy-uri, CAPTCHA etc.
2. Scrapere fără cod / vizuale (cele mai bune pentru începători)
Aceste instrumente se concentrează mai mult pe viteză și simplitate. Nu scrii cod, ci doar dai clic și definești ce vrei să extragi.
Cel mai potrivit pentru:
- Persoane fără cunoștințe tehnice
- Sarcini mici sau rapide de răzuire
- Testarea rapidă a ideilor
Avantaje:
- Ușor de ridicat
- Rapid în a pune ceva în funcțiune
- Nu este nevoie de codare
Contra:
- Nu foarte flexibil
- Se întrerupe ușor pe site-uri complexe sau dinamice
- Nu se scalează bine
3. API-uri de scraping (cele mai bune pentru scalare fără întreținere)
API-urile de scraping se ocupă de cea mai mare parte a muncii grele. Trimiți o cerere, iar acestea se ocupă de proxy-uri, reîncercări și uneori chiar de randare în culise. Dacă vrei să înțelegi cum funcționează acest lucru în practică, mai ales la scară largă, merită să analizezi utilizarea proxy-urilor pentru scraping web fără a fi blocat.
Cel mai potrivit pentru:
- Echipe care nu doresc să gestioneze infrastructura
- Răzuire de volum mare
- Implementare mai rapidă
Avantaje:
- Rotația IP-urilor este gestionată automat
- Logică de reîncercare încorporată
- Adesea acceptă browsere headless
Contra:
- Costurile se pot acumula
- Mai puțin control asupra procesului
- Ești conectat la un serviciu terț
4. Instrumente de extragere a datelor web bazate pe inteligență artificială (tendință emergentă)
Aceasta este o abordare mai nouă. În loc să scrieți selectori, pur și simplu descrieți datele de care aveți nevoie, iar instrumentul încearcă să le identifice.
Cel mai potrivit pentru:
- Experimente rapide
- Machete dezordonate sau care se schimbă frecvent
- Economisirea timpului la configurare
Avantaje:
- Se poate adapta atunci când structurile paginilor se schimbă
- Mai puține ajustări manuale
- Mai rapid pentru a începe
Contra:
- Nu întotdeauna precis
- Încă în evoluție
- Poate avea probleme cu sistemele anti-boți
5. Extragerea datelor din browsere
Aici lucrurile încep să pară mai „reale”. În loc să trimită doar solicitări, aceste instrumente încearcă să se comporte ca niște utilizatori reali.
Acestea gestionează amprente digitale, cookie-uri, sesiuni, practic tot ce ar face un browser normal.
Cel mai potrivit pentru:
- Evitarea detectării
- Gestionarea mai multor conturi
- Rasarea platformelor protejate
Avantaje:
- Se comportă mai mult ca un utilizator real
- Menține consecvența sesiunilor
- Ajută la reducerea blocajelor și interdicțiilor
Contra:
- Necesită timp pentru configurarea corectă
- De obicei, se utilizează împreună cu alte unelte
Cele mai bune instrumente pentru extragerea de informații web pe care ar trebui să le utilizați
Nu toate instrumentele de scraping funcționează bine odată ce începi să generezi un volum semnificativ. Unele arată bine pe hârtie, dar se dărâmă sub presiune. Cele de mai jos sunt instrumente pe care oamenii se bazează efectiv atunci când lucrurile trebuie să funcționeze continuu și la scară largă.
1. AdsPower
Când folosești scraping de platforme cu sisteme anti-boți puternice, instrumente precum AdsPower devin aproape necesare.
Nu este doar un browser în sensul obișnuit; este construit pentru a simula medii reale de utilizare, ceea ce face o mare diferență atunci când încerci să rămâi discret.
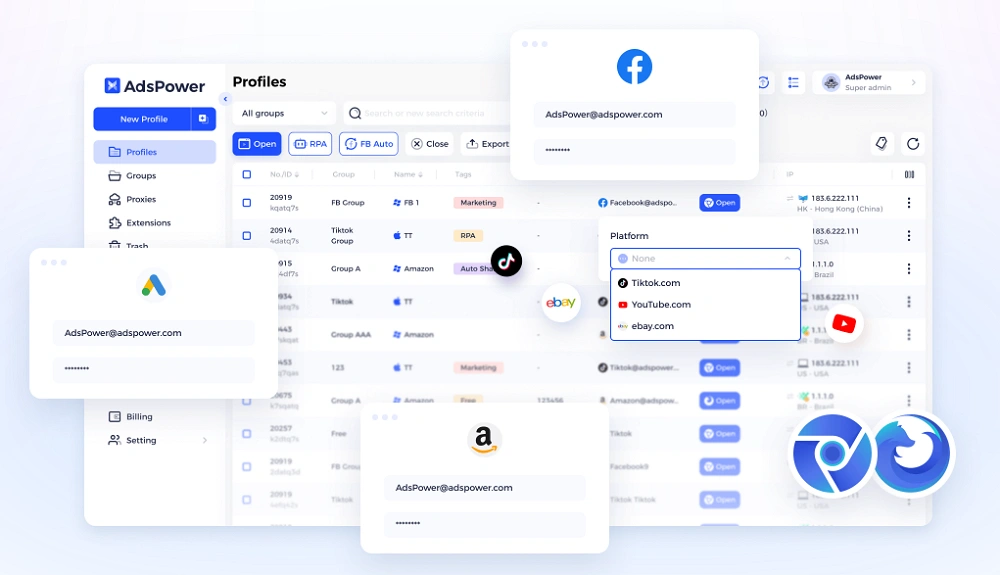
Lucruri cheie de știut:
- Fiecare profil are propria amprentă izolată
- Profilurile se comportă ca dispozitive fizice separate
- Suportă RPA pentru automatizarea fluxurilor de lucru
- Poate integra rezolvitori CAPTCHA
- Menține sesiunile stabile cu cookie-uri și stocare locală
La volume mai mari, această abordare tinde să funcționeze mai bine decât simpla creștere a vitezei solicitărilor. Nu forțezi trecerea prin forță; te integrezi în flux. Pentru comerțul electronic, rețelele sociale sau extragerea de informații de pe marketplace, asta înseamnă adesea mai puține interdicții și mai puțin timp de nefuncționare.
2. Câine răzuitor
Scrapingdog păstrează lucrurile simple, motiv pentru care unele echipe îl preferă.

Ce face bine:
- Gestionează proxy-urile și randarea în culise
- Funcționează fiabil pentru extragerea datelor structurate
- API curat și simplu
Dacă nu vrei să te ocupi de configurarea infrastructurii și ai nevoie doar de ceva funcțional, aceasta este o opțiune rezonabilă.
3. API-ul Scraper
ScraperAPI se concentrează mai mult pe stabilitate decât pe orice altceva.

Caracteristici principale:
- Rotație automată IP
- Gestionare CAPTCHA încorporată
- Conceput pentru rate de succes ridicate la scară largă
Este o alegere bună pentru lucrările de scraping continue, unde consecvența contează mai mult decât personalizarea.
4. Date luminoase
Bright Data se află la capătul mai avansat al spectrului.
Ce primești:
- Rețea proxy extinsă (rezidențială, mobilă, centru de date)
- Opțiuni de direcționare detaliate
- Servicii suplimentare de colectare a datelor
Nu este cel mai simplu instrument de configurat, iar prețul reflectă acest lucru. Dar pentru operațiuni mari, oferă un nivel de acoperire greu de egalat.
5. Apify
Apify este genul de instrument la care oamenii apelează adesea după ce încearcă opțiuni mai simple. Economisește timp, dar îți permite în continuare să modifici lucruri atunci când este nevoie.
- Are „actori” gata de utilizare pentru sarcini comune de scraping
- Rulează totul în cloud, astfel încât nu trebuie să gestionezi servere
- Ușor de scalat atunci când volumul de muncă crește
- Ecosistem decent cu instrumente și șabloane partajate
Nu este excesiv de complex, dar nici complet plug-and-play, undeva la mijloc, ceea ce funcționează bine pentru multe echipe.
6. Dramaturg
Playwright este mai mult un instrument pentru dezvoltatori, iar acest lucru se vede. Este utilizat pe scară largă pentru că funcționează fiabil cu site-urile web moderne.
- Acceptă Chromium, Firefox și WebKit
- Gestionează destul de bine paginile dinamice și JavaScript complex
- Suficient de stabil pentru automatizare pe termen lung
- Flexibil dacă trebuie să personalizezi comportamentul
Majoritatea setărilor personalizate de scraping ajung să folosească ceva de genul acesta în interior.
7. Octoparse
Octoparse este de obicei ceea ce oamenii încearcă atunci când nu vor să se ocupe deloc de cod.
- Interfață vizuală, în mare parte de tip point-and-click
- Începeți rapid cu sarcini de bază de scraping
- Bun pentru proiecte mici sau lucrări unice
- Include șabloane pentru site-uri comune
Este convenabil la început, dar odată ce lucrurile devin mai complexe sau devin mai solicitate, poate părea o limitare.
Tabel comparativ rapid
În această etapă, este destul de clar că nu există un singur instrument care să facă totul perfect. Unele sunt mai ușor de utilizat, altele îți oferă mai mult control, iar altele sunt construite special pentru scalare.
În loc să te gândești prea mult la asta, este util să le analizezi alăturat, mai ales atunci când compari instrumente precum cel mai bun browser anti-detecție pentru extragerea de date web . Tabelul de mai jos oferă o idee rapidă despre locul în care se încadrează fiecare și la ce este folosit de obicei.
Instrument | Tip | Cel mai bun pentru | Rezistenţă |
AdsPower | Browser de extragere a informațiilor | Anti-detecție și scalare | Izolarea amprentelor digitale |
Câine răzuitor | API-ul | Sarcini simple de scraping | Ușurință în utilizare |
ScraperAPI | API-ul | Conducte la scară largă | Fiabilitate |
Date luminoase | Rețea API / Proxy | Scraping-ul întreprinderii | Acoperire |
Apify | Platformă | Automatizare + scraping | Flexibilitate |
Dramaturg | Cadru | Soluții personalizate | Controla |
Octoparse | Fără cod | Începători | Simplitate |
Gânduri finale
Până acum, este destul de clar că scraping-ul web în 2026 nu înseamnă găsirea unui instrument perfect și încheierea acestuia. Ceea ce funcționează de fapt în practică este o combinație de instrumente, fiecare gestionând o parte diferită a procesului. Un nivel s-ar putea ocupa de automatizare, altul de proxy-uri și cereri, iar altul de gestionarea sesiunilor și a identităților. O configurație comună include de obicei ceva de genul Playwright pentru a controla browserul, o API de scraping, cum ar fi ScraperAPI sau Bright Data, pentru a gestiona infrastructura și un instrument precum AdsPower pentru a gestiona amprentele digitale și a menține consecvența sesiunilor. Niciunul dintre acestea nu le înlocuiește pe celelalte; ele funcționează împreună.
Dacă există un lucru care merită ținut minte, este că a rămâne nedetectat contează mai mult decât viteza. Trimiterea mai multor solicitări nu ajută dacă ești blocat la jumătatea drumului. Un sistem mai lent, dar mai stabil, va depăși aproape întotdeauna unul agresiv. Concentrează-te pe consecvență, iar scalarea devine mult mai ușoară în timp.
Întrebări frecvente
Cum se gestionează CAPTCHA în fluxurile de lucru de scraping?
La scară largă, CAPTCHA-urile sunt inevitabile, așa că scopul este de a le gestiona, mai degrabă decât de a le elimina. Majoritatea configurărilor reduc declanșatoarele prin încetinirea ratelor de solicitare, reutilizarea sesiunilor și imitarea comportamentului real al utilizatorilor. În plus, multe echipe integrează servicii de rezolvare CAPTCHA pentru a menține fluxurile de lucru în funcțiune fără intervenție manuală. În practică, este vorba despre un amestec de tehnici, proxy-uri, sincronizare și comportament care ajută la menținerea stabilității, în loc să se bazeze pe o singură soluție.
De ce apare CAPTCHA mai des la scară largă?
Când volumul de scraping crește, tiparele devin mai ușor de detectat pentru site-urile web. Acțiunile repetate, solicitările identice sau sincronizarea nefirească pot declanșa rapid semnale de alarmă. CAPTCHA-urile sunt folosite pentru a verifica dacă traficul este uman, așa că, cu cât comportamentul tău arată mai „asemănător unui bot”, cu atât apare mai des. De aceea, scalarea nu înseamnă doar trimiterea mai multor solicitări, ci face ca aceste solicitări să pară mai puțin previzibile și mai asemănătoare cu cele ale utilizatorilor reali.
De ce are nevoie stiva ta de scraping de protecție împotriva amprentelor?
Proxy-urile singure nu mai sunt suficiente. Site-urile web analizează acum amprentele browserului , setările dispozitivului și modelele de comportament pentru a detecta boții. Fără protecție împotriva amprentelor, chiar și IP-urile rotative pot fi semnalate. Prin crearea de medii de browser izolate, instrumentele de amprentă fac ca fiecare sesiune să pară mai realistă și mai consistentă. Acest lucru ajută la reducerea blocajelor și menține fluxurile de lucru de scraping mai fluide, în special la volume mai mari.

Oamenii citesc și
- Cele mai bune browsere Antidetect din 2026: Evaluate și cotate

Cele mai bune browsere Antidetect din 2026: Evaluate și cotate
Cauți cel mai bun browser antidetecție din 2026? Am testat AdsPower, GoLogin etc. pentru a compara calitatea amprentelor, automatizarea, prețurile și securitatea.
- Cele mai bune proxy-uri pentru centre de date în 2026: Cei mai buni furnizori comparați

Cele mai bune proxy-uri pentru centre de date în 2026: Cei mai buni furnizori comparați
Compară cele mai bune proxy-uri pentru centre de date din 2026, învață cum să alegi furnizorul potrivit și testează fluxurile de lucru proxy în siguranță cu browserul AdsPower.
- Top 7 browsere Antidetect gratuite din 2026 (recenzie și comparație)

Top 7 browsere Antidetect gratuite din 2026 (recenzie și comparație)
Descoperă cel mai bun browser antidetect gratuit din 2026. Află cum să îl alegi pe cel potrivit, compară opțiunile de top precum AdsPower și monitorizează-ți activitatea online.
- Explicația poligrafului în browser: De ce AdsPower trece de sistemele moderne de detectare

Explicația poligrafului în browser: De ce AdsPower trece de sistemele moderne de detectare
Descoperiți cum studiul de cercetare IMC '24 realizat de ASU și Amazon validează consecvența la nivel de kernel a AdsPower. Aflați de ce AdsPower a fost singurul browser care a plătit
- Cele mai bune browsere Agentic în 2026: Caracteristici, prețuri și comparație

Cele mai bune browsere Agentic în 2026: Caracteristici, prețuri și comparație
Când cauți cel mai bun browser agentic pentru automatizarea fluxului de lucru, răsfoiește această recenzie a browserului agentic AI și testează-l înainte de a începe.
