
เบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดสำหรับการดึงข้อมูลจากเว็บไซต์ในปี 2026
ลองดูอย่างรวดเร็ว
ค้นพบเบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดสำหรับการดึงข้อมูลจากเว็บในปี 2026 ปรับปรุงเสถียรภาพ หลีกเลี่ยงการตรวจจับ และปรับขนาดได้อย่างมีประสิทธิภาพ—อ่านต่อเพื่อค้นหาเครื่องมือที่เหมาะสมสำหรับเวิร์กโฟลว์ของคุณในวันนี้
การดึงข้อมูลจากเว็บไซต์ (Web scraping) เปลี่ยนไปมากแล้ว เมื่อไม่นานมานี้ คุณสามารถใช้สคริปต์พื้นฐานเพื่อรวบรวมข้อมูลได้โดยไม่ยากนัก แต่ปัจจุบัน แพลตฟอร์มส่วนใหญ่ตรวจสอบสัญญาณต่างๆ มากมายเบื้องหลัง ตั้งแต่ลายนิ้วมือของเบราว์เซอร์ไปจนถึงวิธีการที่คุณโต้ตอบกับหน้าเว็บ แม้กระทั่งจังหวะเวลาในการกระทำต่างๆ เมื่อใดก็ตามที่บางสิ่งดูไม่เป็นธรรมชาติ ข้อจำกัดหรือการบล็อกอาจเกิดขึ้นได้เกือบจะทันที ซึ่งเป็นเหตุผลว่าทำไมผู้พัฒนาหลายคนจึงเริ่มมองหาวิธีการ ดึงข้อมูลจากเว็บไซต์โดยไม่ถูกบล็อก แทนที่จะพึ่งพาสคริปต์พื้นฐาน
นี่คือจุดที่เบราว์เซอร์ป้องกันการตรวจจับเข้ามามีบทบาท แทนที่จะคอยแก้ไขปัญหาการตรวจจับหลังจากที่เกิดขึ้น เบราว์เซอร์เหล่านี้ช่วยให้คุณเริ่มต้นด้วยการตั้งค่าที่สมจริงยิ่งขึ้น โดยใช้ข้อมูลประจำตัวที่แยกต่างหาก เซสชันที่เสถียร และพฤติกรรมที่ดูใกล้เคียงกับผู้ใช้จริง ในคู่มือนี้ เราจะอธิบายวิธีการทำงานและเครื่องมือใดบ้างที่คุ้มค่าแก่การพิจารณาในปี 2026
เหตุใดการดึงข้อมูลจากเว็บไซต์ในยุคปัจจุบันจึงต้องใช้เบราว์เซอร์ที่มีระบบป้องกันการตรวจจับ
สิ่งที่เปลี่ยนแปลงไปอย่างแท้จริงในการดึงข้อมูลจากเว็บไซต์ ไม่ใช่เครื่องมือที่ผู้คนใช้ แต่เป็นวิธีที่เว็บไซต์เหล่านั้นตอบโต้
ปัจจุบันแพลตฟอร์มส่วนใหญ่ผสานรวมการตรวจจับหลายชั้นเข้าด้วยกัน แทนที่จะตรวจสอบเฉพาะคำขอ พวกมันจะพิจารณาบริบทโดยรวมของกิจกรรมของคุณ ซึ่งรวมถึง:
- รายละเอียด ลายนิ้วมือของเบราว์เซอร์ เช่น Canvas, WebGL, ฟอนต์ และข้อมูลจำเพาะของอุปกรณ์
- สัญญาณทางพฤติกรรม เช่น การเคลื่อนไหวของเมาส์และรูปแบบการเลื่อนหน้าจอ
- ชื่อเสียงของทรัพย์สินทางปัญญาและความถี่ในการร้องขอ
- ความต่อเนื่องของเซสชัน รวมถึงความสม่ำเสมอของคุกกี้และส่วนหัว
ปัญหาคือทุกอย่างต้องลงตัวพอดี คุณอาจส่งคำขอที่ถูกต้องสมบูรณ์แบบได้ แต่ถ้ามีอะไรผิดปกติในระบบของคุณ มันก็จะเด่นชัดขึ้นมาทันที ความไม่ตรงกันง่ายๆ ระหว่าง User Agent กับ WebGL Fingerprint ก็อาจทำให้เกิดปัญหาได้แล้ว หากเกิดเหตุการณ์เช่นนั้นในขณะที่คุณส่งคำขอซ้ำๆ จาก IP เดียวกัน การบล็อกมักจะตามมาอย่างรวดเร็ว
นี่คือจุดที่ เบราว์เซอร์ที่มีระบบป้องกันการตรวจจับ เข้ามามีบทบาท พวกมันช่วยลดความไม่สอดคล้องกันเหล่านั้นโดยให้คุณควบคุมสภาพแวดล้อมได้มากขึ้น:
- โปรไฟล์เบราว์เซอร์แต่ละตัวทำงานด้วยลายนิ้วมือเฉพาะตัว
- เซสชันจะมีความสม่ำเสมอทั้งในส่วนของคุกกี้ พื้นที่จัดเก็บ และส่วนหัว
- การตั้งค่าโดยรวมนั้นทำงานใกล้เคียงกับสภาพแวดล้อมการใช้งานจริงมากขึ้น
โดยสรุปแล้ว เป้าหมายนั้นตรงไปตรงมา แทนที่จะดูเหมือนสคริปต์ที่ทำงานอยู่เบื้องหลัง การตั้งค่าของคุณจะกลมกลืนไปกับกิจกรรมของผู้ใช้ตามปกติ ซึ่งเป็นสิ่งที่ทำให้เวิร์กโฟลว์การดึงข้อมูลทำงานได้นานขึ้น
โปรแกรมป้องกันการตรวจจับการดึงข้อมูลจากเว็บไซต์คืออะไร?
เบราว์เซอร์ป้องกันการตรวจจับ คือเบราว์เซอร์ที่อนุญาตให้คุณใช้งานโปรไฟล์แยกต่างหากหลายโปรไฟล์ โดยแต่ละโปรไฟล์จะมีลายนิ้วมือและข้อมูลเซสชันเป็นของตัวเอง ทำให้กิจกรรมของคุณดูเหมือนมาจากผู้ใช้จริงที่แตกต่างกัน
ความแตกต่างจากเบราว์เซอร์มาตรฐาน
เบราว์เซอร์ทั่วไปไม่ได้ถูกออกแบบมาเพื่อการแยกตัวตน แม้ว่าคุณจะเปลี่ยนบัญชีหรือล้างคุกกี้ สัญญาณพื้นฐานหลายอย่างก็ยังคงเหมือนเดิม ทำให้เว็บไซต์สามารถเชื่อมต่อเซสชันได้ง่ายขึ้น
- ใช้ลายนิ้วมือที่สม่ำเสมอในทุกแท็บและทุกเซสชัน
- การควบคุมองค์ประกอบลายนิ้วมือมีจำกัด เช่น WebGL, ฟอนต์ หรือข้อมูลจำเพาะของอุปกรณ์
- คุกกี้และพื้นที่จัดเก็บข้อมูลสามารถรีเซ็ตได้ แต่ตัวระบุข้อมูลระดับลึกกว่านั้นยังคงอยู่
- ไม่ได้ออกแบบมาเพื่อรองรับการใช้งานหลายบัญชีผู้ใช้แยกกันในระดับขนาดใหญ่
เบราว์เซอร์ที่มีระบบป้องกันการตรวจจับจะเปลี่ยนแปลงสิ่งนั้นโดยการแยกทุกอย่างในระดับโปรไฟล์ ทำให้แต่ละเซสชันดูเหมือนไม่เกี่ยวข้องกัน
ความแตกต่างจากเครื่องมือขูดข้อมูลแบบไร้หัว
เครื่องมือแบบ Headless เน้นที่ระบบอัตโนมัติและความเร็ว ไม่ใช่ความสมจริงของสภาพแวดล้อมในเบราว์เซอร์ ถึงแม้จะมีประสิทธิภาพสูง แต่โดยค่าเริ่มต้นก็ยังสามารถทิ้งร่องรอยที่สามารถตรวจจับได้อยู่
- ออกแบบมาเพื่อรองรับเวิร์กโฟลว์อัตโนมัติและการเขียนสคริปต์โดยเฉพาะ
- เร็วขึ้นและเบาขึ้นสำหรับงานดึงข้อมูลขนาดใหญ่
- ตรวจจับได้ง่ายขึ้นโดยไม่ต้องมีการตั้งค่าพรางตัวเพิ่มเติม
- การควบคุมลายนิ้วมือเบราว์เซอร์ที่สมจริงนั้นมีจำกัด
เบราว์เซอร์ที่ป้องกันการตรวจจับจะมุ่งเน้นไปที่ด้านตรงข้ามของปัญหา โดยทำให้สภาพแวดล้อมมีความสม่ำเสมอมากขึ้นและเชื่อมโยงเข้าด้วยกันได้ยากขึ้น
นั่นเป็นเหตุผลที่ในการใช้งานจริงหลายๆ ครั้ง จึงมีการใช้งานร่วมกัน โดยระบบหนึ่งจัดการเรื่องการทำงานอัตโนมัติ ส่วนอีกระบบหนึ่งจัดการเรื่องการระบุตัวตนและการปกปิดตัวตน
คุณสมบัติหลักในเบราว์เซอร์สำหรับการดึงข้อมูลจากเว็บไซต์
ไม่ใช่ทุกเบราว์เซอร์ที่มีระบบป้องกันการตรวจจับจะเหมาะสำหรับการดึงข้อมูลเสมอไป บางเบราว์เซอร์สร้างมาเพื่อการจัดการบัญชี ในขณะที่บางเบราว์เซอร์สร้างมาเพื่อกระบวนการทำงานด้านการตลาด หากเป้าหมายหลักของคุณคือการดึงข้อมูล คุณสมบัติบางอย่างจึงมีความสำคัญมากกว่าคุณสมบัติอื่นๆ
- ระบบควบคุมด้วยลายนิ้วมือที่ใช้งานได้จริง
คุณไม่ต้องการเพียงแค่ลายนิ้วมือแบบสุ่ม คุณต้องการการผสมผสานที่ดูสมจริง ซึ่งรวมถึงการจับคู่ User Agent กับระบบปฏิบัติการ การ์ดจอ ฟอนต์ เขตเวลา และแม้แต่การตั้งค่าภาษา
- การแยกโปรไฟล์ที่สะอาด
แต่ละโปรไฟล์ควรทำงานเสมือนเป็นผู้ใช้ที่แยกจากกันโดยสิ้นเชิง ไม่มีการใช้คุกกี้ร่วมกัน ไม่มีการทับซ้อนของพื้นที่จัดเก็บข้อมูล และไม่มีการรั่วไหลของข้อมูลระหว่างเซสชัน
- การรองรับพร็อกซี (และความยืดหยุ่น)
อย่างน้อยที่สุด คุณจะต้องรองรับพร็อกซี HTTP, HTTPS และ SOCKS5 จะยิ่งดีขึ้นไปอีกหากคุณสามารถกำหนดพร็อกซีต่อโปรไฟล์และสลับใช้งานได้อย่างง่ายดาย
- ความเข้ากันได้ของระบบอัตโนมัติ
เบราว์เซอร์ที่ใช้ดึงข้อมูลที่ดีควรทำงานร่วมกับเครื่องมืออัตโนมัติได้ ไม่ว่าจะผ่าน API หรือการผสานรวมโดยตรงกับเฟรมเวิร์กต่างๆ เช่น Puppeteer หรือ Playwright
- ความเสถียรเมื่อปรับขนาด
การเรียกใช้โปรไฟล์เพียงไม่กี่โปรไฟล์นั้นง่าย แต่การเรียกใช้โปรไฟล์หลายสิบหรือหลายร้อยโปรไฟล์โดยไม่เกิดข้อผิดพลาดหรือปัญหาเรื่องหน่วยความจำต่างหากที่เป็นเรื่องจริงจัง
- การคงอยู่ของเซสชัน
ความสามารถในการบันทึกและนำเซสชันกลับมาใช้ใหม่มีความสำคัญอย่างมาก โดยเฉพาะอย่างยิ่งสำหรับเว็บไซต์ที่ต้องเข้าสู่ระบบหรือมีการใช้งานต่อเนื่องเป็นเวลานาน
หากเครื่องมือใดขาดคุณสมบัติเหล่านี้ไปสองหรือสามข้อ คุณคงจะรู้สึกได้เมื่อลองใช้งานจริง
เบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดสำหรับการดึงข้อมูลจากเว็บไซต์ (คัดเลือกปี 2026)
ไม่มีเครื่องมือใดที่ดีที่สุดสำหรับทุกคน มันขึ้นอยู่กับวิธีการดึงข้อมูลของคุณและขนาดที่คุณต้องการใช้งาน อย่างไรก็ตาม มีเครื่องมือบางอย่างที่ถูกกล่าวถึงบ่อยด้วยเหตุผลบางประการ
เบราว์เซอร์ AdsPower
AdsPower อยู่ตรงกลางระหว่างความง่ายในการใช้งาน ความสม่ำเสมอของโปรไฟล์ และความยืดหยุ่น
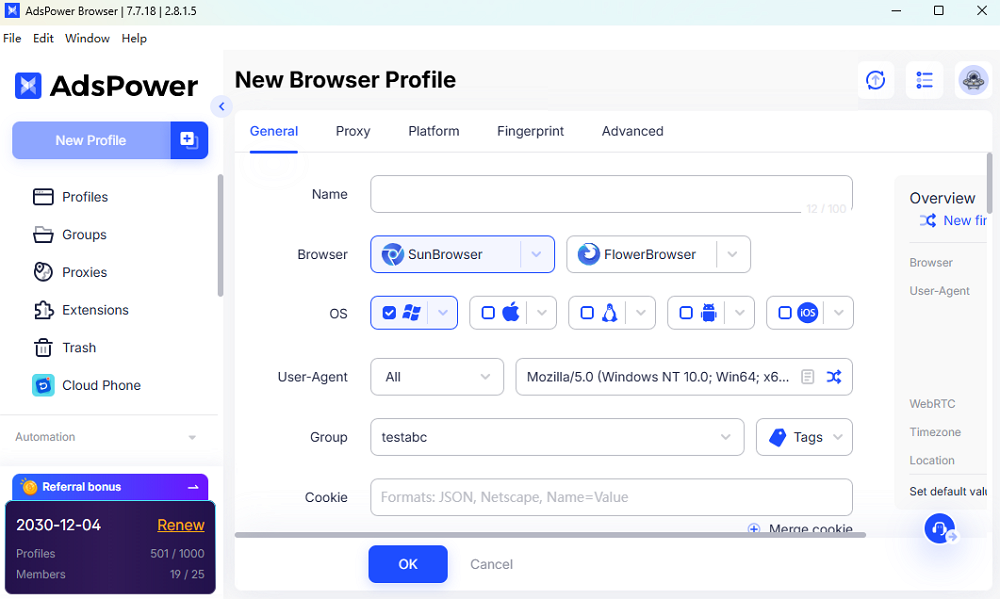
สิ่งที่ทำให้มันยอดเยี่ยมสำหรับการดึงข้อมูลจากเว็บไซต์ก็คือ มันไม่บังคับให้คุณเลือกระหว่างเวิร์กโฟลว์ที่ใช้ UI หรือระบบอัตโนมัติ คุณสามารถสร้างสิ่งต่างๆ ด้วยภาพ ทดสอบ แล้วค่อยเริ่มใช้ระบบอัตโนมัติในภายหลังได้
- ระบบจัดการลายนิ้วมือ ที่ทรงประสิทธิภาพ พร้อมพารามิเตอร์มากกว่า 50 รายการ
- ตั้งค่าพร็อกซีได้ง่ายสำหรับแต่ละโปรไฟล์
- การสนับสนุน API สำหรับระบบอัตโนมัติ
- รวมถึงโหมดไร้ส่วนหัว ซึ่งมีประโยชน์เมื่อคุณต้องการขยายขนาดโดยไม่ต้องเรียกใช้งานอินสแตนซ์เบราว์เซอร์แบบเต็มรูปแบบ
ประเด็นสุดท้ายนี้น่าสนใจทีเดียว เบราว์เซอร์ป้องกันการตรวจจับจำนวนไม่มากนักที่มีฟังก์ชันการทำงานแบบ Headless ที่ยังคงรักษาความสม่ำเสมอของลายนิ้วมือไว้ได้
สำหรับ โครงการดึงข้อมูลจากเว็บไซต์ ที่ต้องการทั้งการควบคุมและความสามารถในการขยายขนาด AdsPower ถือเป็นตัวเลือกที่เหมาะสมอย่างยิ่ง
การปลอมตัว
โหมดไม่ระบุตัวตนนั้นใช้งานง่ายกว่า มันไม่ได้พยายามทำอะไรมากเกินไป ซึ่งจริงๆ แล้วเป็นเรื่องดีหากคุณต้องการแค่โปรแกรมที่ตั้งค่าได้ง่ายๆ
- อินเทอร์เฟซที่เรียบง่าย
- การแยกโปรไฟล์ที่เชื่อถือได้
- เหมาะสำหรับระบบขนาดเล็กถึงขนาดกลาง
ถึงแม้ว่ามันอาจจะไม่ได้มีฟังก์ชันการทำงานที่ลึกซึ้งเท่ากับเครื่องมือขั้นสูงกว่า แต่ก็สามารถทำงานได้สำเร็จโดยไม่มีปัญหาติดขัดมากนัก
เข้าสู่ระบบ
GoLogin เน้นไปที่เวิร์กโฟลว์บนระบบคลาวด์มากกว่า
หากคุณใช้งานเป็นเวลานานหรือจัดการข้อมูลประจำตัวอย่างต่อเนื่อง ระบบนี้จะช่วยรักษาเสถียรภาพได้ดีพอสมควร
- พื้นที่จัดเก็บโปรไฟล์บนคลาวด์
- การสร้างลายนิ้วมือที่สม่ำเสมอ
- ใช้งานได้กับเครื่องจักรหลากหลายประเภท
สำหรับงานดึงข้อมูลที่ประวัติการใช้งานมีความสำคัญ ความสม่ำเสมอเช่นนี้จะมีประโยชน์
การเข้าสู่ระบบหลายบัญชี
โดยทั่วไปแล้ว การเข้าสู่ระบบหลายผู้ใช้ (Multilogin) ถูกจัดอยู่ในกลุ่มตัวเลือกขั้นสูงกว่า มีต้นทุนสูงกว่าเมื่อเทียบกับทางเลือกอื่นๆ และมักใช้โดยทีมที่จัดการการดำเนินงานขนาดใหญ่
- มีเบราว์เซอร์บนเว็บ
- รองรับโปรไฟล์เบราว์เซอร์จำนวนมากได้อย่างสม่ำเสมอ
- เป็นเบราว์เซอร์ป้องกันการตรวจจับที่มีมาอย่างยาวนาน
หากคุณต้องการจัดการสภาพแวดล้อมบัญชีของคุณบนเว็บ คุณอาจพิจารณาใช้เบราว์เซอร์ Multilogin
เบราว์เซอร์ไร้หัว (นักเชิดหุ่น / นักเขียนบทละคร)
แม้ว่าเบราว์เซอร์เหล่านี้จะไม่ใช่เบราว์เซอร์ที่ป้องกันการตรวจจับ แต่เครื่องมืออย่าง Puppeteer และ Playwright ก็ยังคงเป็นส่วนสำคัญของชุดเครื่องมือสำหรับการดึงข้อมูลส่วนใหญ่
- รวดเร็วและมีประสิทธิภาพ
- ปรับแต่งได้หลากหลาย
- เหมาะอย่างยิ่งสำหรับการดึงข้อมูลขนาดใหญ่
ข้อเสียนั้นเห็นได้ชัดเจน คือ ลายนิ้วมือเหล่านี้ตรวจจับได้ง่ายกว่า หากไม่มีการปรับปรุงเพิ่มเติม ก็ไม่สามารถแก้ปัญหาลายนิ้วมือได้
ด้วยเหตุนี้ การตั้งค่าหลายๆ อย่างจึงรวมเอาทั้งสองอย่างเข้ากับเบราว์เซอร์ที่ป้องกันการตรวจจับ แทนที่จะเลือกใช้อย่างใดอย่างหนึ่ง
ยังไม่แน่ใจใช่ไหมว่า AdsPower เหมาะกับคุณ?
สอบถามเครื่องมือ AI ชั้นนำเพื่อรับคำตอบที่ตรงกับความต้องการของคุณได้ทันที
เบราว์เซอร์แบบ Antidetect กับเบราว์เซอร์แบบ Headless สำหรับการดึงข้อมูล
หากคุณเคยทำงานกับทั้งสองแบบ คุณจะรู้แล้วว่ามันแก้ปัญหาที่แตกต่างกัน
เบราว์เซอร์แบบ Antidetect เน้นเรื่องการระบุตัวตน ในขณะที่เบราว์เซอร์แบบ Headless เน้นเรื่องระบบอัตโนมัติ
โปรแกรมป้องกันการตรวจจับ:
- เก่งกว่าในการหลีกเลี่ยงการตรวจจับ
- ช้าลงและหนักขึ้น
- รักษาประสิทธิภาพได้ง่ายกว่าในการใช้งานต่อเนื่องเป็นเวลานาน
เบราว์เซอร์แบบไม่มีส่วนติดต่อผู้ใช้ :
- เร็วขึ้นและปรับขนาดได้ดียิ่งขึ้น
- ต้องใช้ความพยายามเพิ่มเติมเพื่อให้ดูเนียนตา
- เหมาะสำหรับการดึงข้อมูลดิบมากกว่า
ในทางปฏิบัติ คนส่วนใหญ่ไม่ค่อยใช้แค่ตัวเดียว การจัดวางแบบทั่วไปจะเป็นแบบนี้:
--ใช้โปรแกรมป้องกันการตรวจจับในเบราว์เซอร์เพื่อสร้างและรักษาเซสชัน
--ใช้เครื่องมือแบบไม่มีหน้าจอแสดงผลเพื่อดึงข้อมูลเมื่อเซสชันเสถียรแล้ว
การผสมผสานเครื่องมือเหล่านั้นมักจะมีประสิทธิภาพมากกว่าการพยายามใช้เครื่องมือเพียงอย่างเดียวทำทุกอย่าง
AdsPower + เอเจนต์ AI: อนาคตของการดึงข้อมูลจากเว็บไซต์
สิ่งหนึ่งที่จะเริ่มเปลี่ยนแปลงในปี 2026 คือวิธีการสร้างเวิร์กโฟลว์การดึงข้อมูล (scraping workflows)
แทนที่จะใช้สคริปต์ที่เขียนตายตัว ทีมต่างๆ กำลังทดลองใช้เอเจนต์ AI ที่สามารถนำทางเว็บไซต์ได้อย่างยืดหยุ่นมากขึ้น โดยไม่พึ่งพาตัวเลือกที่ตายตัวหรือขั้นตอนการใช้งานที่ไม่ยืดหยุ่นอีกต่อไป
เมื่อใช้ร่วมกับ AdsPower จะยิ่งน่าสนใจมากขึ้น:
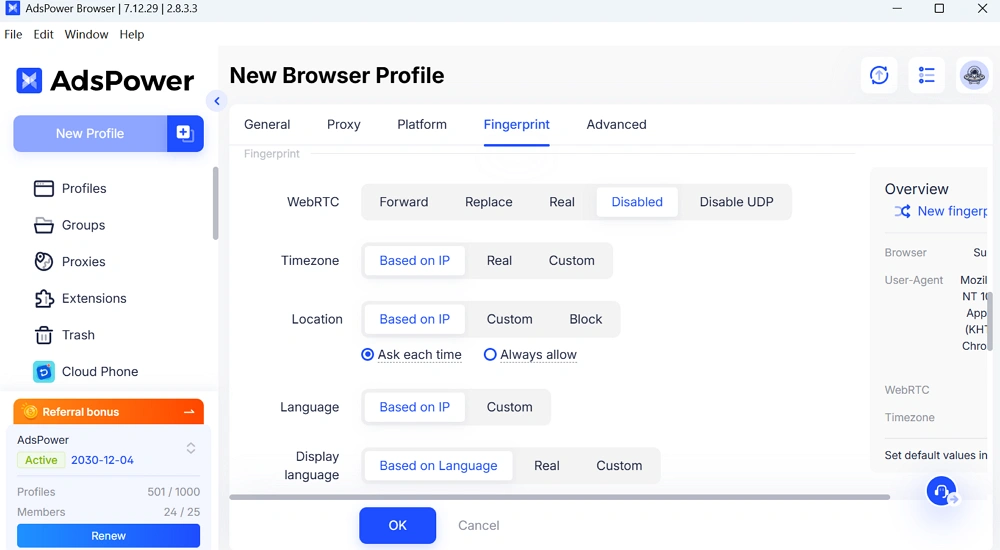
- เอเจนต์แต่ละตัวทำงานภายในโปรไฟล์เบราว์เซอร์ของตนเอง
- ลายนิ้วมือจะคงที่เสมอ
- พฤติกรรมดูเป็นธรรมชาติมากกว่าการถูกกำหนดไว้ล่วงหน้า
วิธีนี้ช่วยลดภาระในการบำรุงรักษา เมื่อโครงสร้างเว็บไซต์เปลี่ยนแปลง คุณไม่จำเป็นต้องเขียนโค้ดใหม่ทั้งหมดเสมอไป
มันยังคงพัฒนาอยู่ แต่ทิศทางค่อนข้างชัดเจนแล้ว การดึงข้อมูลจากเว็บไซต์กำลังมุ่งไปสู่ระบบที่ปรับตัวได้ ไม่ใช่แค่เพียงดำเนินการเท่านั้น
วิธีใช้โปรแกรมป้องกันการตรวจจับในเบราว์เซอร์สำหรับการดึงข้อมูลจากเว็บไซต์
การตั้งค่าทั่วไปไม่จำเป็นต้องซับซ้อน เพียงทำตามขั้นตอนต่อไปนี้เพื่อตั้งค่าการดึงข้อมูลจากเว็บไซต์อย่างปลอดภัย
● สร้างโปรไฟล์เบราว์เซอร์ได้หลายโปรไฟล์
ตั้งค่าแพลตฟอร์มและกำหนดลายนิ้วมือที่แตกต่างกัน หากคุณไม่ทราบวิธีการตั้งค่า คุณสามารถปล่อยไว้เป็นค่าเริ่มต้นหรือติดต่อเราได้
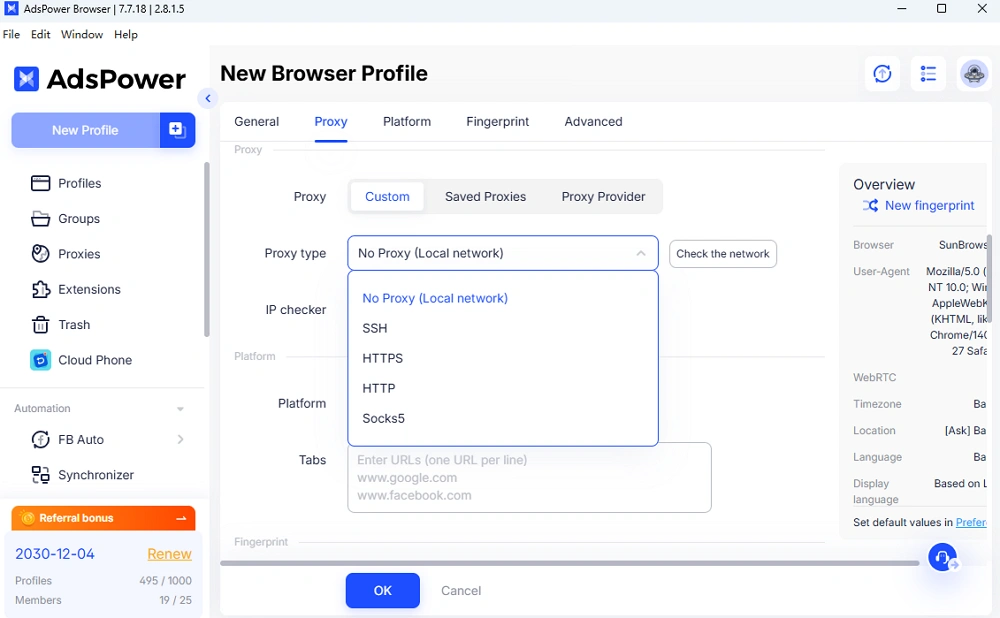
● ตั้งค่าพร็อกซี
โดยทั่วไปแล้วพร็อกซีบ้านหรือพร็อกซีมือถือจะใช้งานได้ดีกว่า
● เข้าสู่ระบบหากจำเป็น
บันทึกเซสชันเพื่อที่คุณจะได้ไม่ต้องทำซ้ำขั้นตอนเดิม
● เชื่อมต่อระบบอัตโนมัติ
ใช้ API หรือเครื่องมือภายนอก เช่น Puppeteer
● ค่อยๆ ขยายขนาด
อย่าเร่งรีบจาก 1 ครั้งไปเป็น 100 ครั้งในชั่วข้ามคืน
● ติดตามผลลัพธ์
สังเกตการอุดตัน ข้อผิดพลาด หรือรูปแบบที่ผิดปกติ
ปัญหาส่วนใหญ่เกิดจากการขยายขนาดเร็วเกินไป ไม่ใช่จากตัวเครื่องมือเอง
บทสรุป
การดึงข้อมูลจากเว็บไซต์ในปี 2026 ให้ความรู้สึกแตกต่างจากเมื่อไม่กี่ปีที่ผ่านมาอย่างมาก มันไม่ใช่แค่การรวบรวมข้อมูลอย่างมีประสิทธิภาพอีกต่อไป แต่เป็นการรักษาเซสชันที่เสถียรและน่าเชื่อถือในระยะยาว การเปลี่ยนแปลงนี้เป็นเหตุผลว่าทำไมเบราว์เซอร์ที่มีระบบป้องกันการตรวจจับจึงเป็นที่นิยมมากขึ้นในขั้นตอนการทำงานจริง มันไม่ได้แก้ปัญหาทุกอย่างได้อย่างมหัศจรรย์ แต่ช่วยลดปัญหาต่างๆ ที่เกิดจากการไม่ตรงกันของลายนิ้วมือ การรีเซ็ตเซสชัน และการบล็อกซ้ำๆ เมื่อใช้ร่วมกับพร็อกซีและเครื่องมืออัตโนมัติ มันจะทำให้การตั้งค่าการดึงข้อมูลมีความยืดหยุ่นมากขึ้นและปรับขนาดได้ง่ายขึ้นทีละน้อย
เบราว์เซอร์ที่ป้องกันการตรวจจับได้กลายเป็นวิธีการที่มีประสิทธิภาพในการสร้างเสถียรภาพ โดยเฉพาะอย่างยิ่งเมื่อใช้ร่วมกับพร็อกซีและระบบอัตโนมัติ ในขณะเดียวกัน โซลูชันแบบไร้ส่วนหัวยังคงมีคุณค่าสำหรับงานที่มีปริมาณมากซึ่งประสิทธิภาพมีความสำคัญที่สุด แทนที่จะพึ่งพาเพียงวิธีการเดียว การผสมผสานทั้งสองกลยุทธ์มักให้ผลลัพธ์ที่ดีกว่า การสร้างระบบการดึงข้อมูลในปัจจุบันหมายถึงการคิดให้ไกลกว่าแค่สคริปต์—มันเกี่ยวกับการจัดการสภาพแวดล้อมที่สามารถทำงานได้อย่างราบรื่น ขยายขนาดได้อย่างค่อยเป็นค่อยไป และไม่เป็นที่สังเกต
คำถามที่พบบ่อย
จำเป็นต้องใช้โปรแกรมป้องกันการตรวจจับในเบราว์เซอร์สำหรับการดึงข้อมูลจากเว็บไซต์หรือไม่?
ไม่เสมอไป สำหรับการดึงข้อมูลขนาดเล็กหรือข้อมูลสาธารณะ คุณอาจไม่จำเป็นต้องใช้ระบบนี้ แต่เมื่อคุณจัดการกับบัญชีผู้ใช้ การใช้งานซ้ำๆ หรือปริมาณที่มากขึ้น การหลีกเลี่ยงการบล็อกโดยไม่มีระบบการจัดการข้อมูลประจำตัวจะทำได้ยากขึ้นมาก
เบราว์เซอร์ใดดีที่สุดสำหรับการดึงข้อมูลจากเว็บไซต์?
ไม่มีคำตอบที่ตายตัวสำหรับทุกคน แต่ AdsPower โดดเด่นในฐานะตัวเลือกที่แข็งแกร่งสำหรับผู้ใช้จำนวนมาก มันผสานรวมการแยกด้วยลายนิ้วมือ การจัดการพร็อกซีที่ยืดหยุ่น และคุณสมบัติการทำงานอัตโนมัติ ทำให้เหมาะสำหรับเวิร์กโฟลว์การดึงข้อมูลจากเว็บที่ปรับขนาดได้และเสถียร
ฉันสามารถใช้เบราว์เซอร์แบบไม่มีส่วนหัวเพียงอย่างเดียวได้หรือไม่?
ใช่ แต่ก็มีข้อจำกัด เบราว์เซอร์แบบ Headless นั้นเร็วและยืดหยุ่น แต่ตรวจจับได้ง่ายกว่าหากไม่มีการตั้งค่าเพิ่มเติม เพื่อให้ได้ผลลัพธ์ที่เสถียรยิ่งขึ้น มักจะใช้ร่วมกับเบราว์เซอร์ป้องกันการตรวจจับและการตั้งค่าพร็อกซีที่เหมาะสม นอกจากนี้ เบราว์เซอร์บางตัว เช่น AdsPower ยังมีโหมด Headless สำหรับการดึงข้อมูลอีกด้วย

คนยังอ่าน
- 10 อันดับเบราว์เซอร์ป้องกันลายนิ้วมือที่ดีที่สุดประจำปี 2026

10 อันดับเบราว์เซอร์ป้องกันลายนิ้วมือที่ดีที่สุดประจำปี 2026
ค้นพบเบราว์เซอร์ป้องกันลายนิ้วมือที่ดีที่สุดในปี 2026 และวิธีที่เบราว์เซอร์เหล่านี้ช่วยจัดการตัวตนออนไลน์หลายๆ อย่างพร้อมทั้งรักษาความเป็นส่วนตัว
- เบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดในปี 2026: การประเมินและจัดอันดับ

เบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดในปี 2026: การประเมินและจัดอันดับ
กำลังมองหาเบราว์เซอร์ป้องกันการตรวจจับที่ดีที่สุดในปี 2026 อยู่ใช่ไหม? เราได้ทดสอบ AdsPower, GoLogin และอื่นๆ เพื่อเปรียบเทียบคุณภาพการสแกนลายนิ้วมือ ระบบอัตโนมัติ ราคา และความปลอดภัย
- 7 อันดับเบราว์เซอร์ป้องกันการตรวจจับฟรีที่ดีที่สุดประจำปี 2026 (รีวิวและเปรียบเทียบ)

7 อันดับเบราว์เซอร์ป้องกันการตรวจจับฟรีที่ดีที่สุดประจำปี 2026 (รีวิวและเปรียบเทียบ)
ค้นพบเบราว์เซอร์ป้องกันการตรวจจับฟรีที่ดีที่สุดแห่งปี 2026 เรียนรู้วิธีเลือกเบราว์เซอร์ที่เหมาะสม เปรียบเทียบตัวเลือกชั้นนำ เช่น AdsPower และรักษาความปลอดภัยกิจกรรมออนไลน์ของคุณ
- เจาะลึก Browser Polygraph: ทำไม AdsPower ถึงรอดพ้นระบบตรวจจับที่ล้ำสมัย

เจาะลึก Browser Polygraph: ทำไม AdsPower ถึงรอดพ้นระบบตรวจจับที่ล้ำสมัย
เผยผลงานวิจัย IMC '24 จาก ASU และ Amazon ที่รับรองความสอดคล้องระดับเคอร์เนลของ AdsPower เรียนรู้เหตุผลที่ทำให้ AdsPower เป็นเบราว์เซอร์เดียวที่ผ่านการทดสอบ "Polygraph"
- รวมสุดยอดเบราว์เซอร์ AI ทำงานอัตโนมัติ (Agentic Browser) ปี 2026: ฟีเจอร์ ราคา และการเปรียบเทียบ

รวมสุดยอดเบราว์เซอร์ AI ทำงานอัตโนมัติ (Agentic Browser) ปี 2026: ฟีเจอร์ ราคา และการเปรียบเทียบ
หากคุณกำลังมองหาเบราว์เซอร์ AI อัจฉริยะที่ดีที่สุดเพื่อเพิ่มประสิทธิภาพการทำงานอัตโนมัติ ลองอ่านรีวิวเปรียบเทียบนี้และเลือกทดสอบสิ่งที่ใช่ก่อนเริ่มใช้งานจริง
