
Die 10 besten Headless-Browser für Web Scraping: Vor- und Nachteile
Werfen Sie einen kurzen Blick
Möchten Sie Ihr Web-Scraping optimieren? Headless-Browser sind Ihre Geheimwaffe. Erfahren Sie, wie sie funktionieren, warum sie so effektiv sind und welche Ihr Scraping auf die nächste Stufe heben.
Mussten Sie schon einmal große Mengen an Online-Daten effizient extrahieren und mussten feststellen, dass herkömmliche Browser Sie ausbremsen? Von der Preisverfolgung bis zur Wettbewerbsanalyse ist Web Scraping unerlässlich für die automatisierte Datenerfassung. Die Verwendung eines regulären Browsers zum Scrapen kann jedoch langsam und ineffizient sein. Wenn Geschwindigkeit und Automatisierung wichtig sind, welche Lösung ist die beste?
In diesem Leitfaden stellen wir Ihnen die 10 besten Headless-Browser für Web Scraping vor und analysieren ihre Stärken und Schwächen, damit Sie das richtige Tool für Ihre Bedürfnisse auswählen können.
Was ist ein Headless-Browser?
Einfach ausgedrückt ist ein Headless-Browser ein Webbrowser ohne grafische Benutzeroberfläche (GUI). Er arbeitet im Hintergrund und ruft Webseiten wie ein normaler Browser ab und rendert sie, ohne sie jedoch auf Ihrem Bildschirm anzuzeigen. Dadurch eignen sich Headless-Browser perfekt für Aufgaben wie Web Scraping, automatisierte Tests und Leistungsüberwachung.
Übrigens bietet der Headless-Modus eines Antidetect-Browsers wie AdsPower ähnliche Funktionen wie herkömmliche Headless-Browser, jedoch mit verbesserter Tarnung. Während herkömmliche Headless-Browser oft aufgrund fehlender Fingerabdrücke markiert werden, hilft der Headless-Modus von AdsPower dabei, die Erkennung zu umgehen, indem digitale Fingerabdrücke maskiert und modifiziert werden, sodass Ihre Anfragen so aussehen, als kämen sie von eindeutigen, legitimen Benutzern.
| Anwendungsfall | AdsPower Headless-Modus | Herkömmliche Headless-Browser |
| Verwaltung mehrerer Konten | ✅ Ja | ❌ Nein |
| Umgehung der Bot-Erkennung | ✅ Ja | ❌ Nein |
Wie starte ich AdsPower im Headless-Modus?
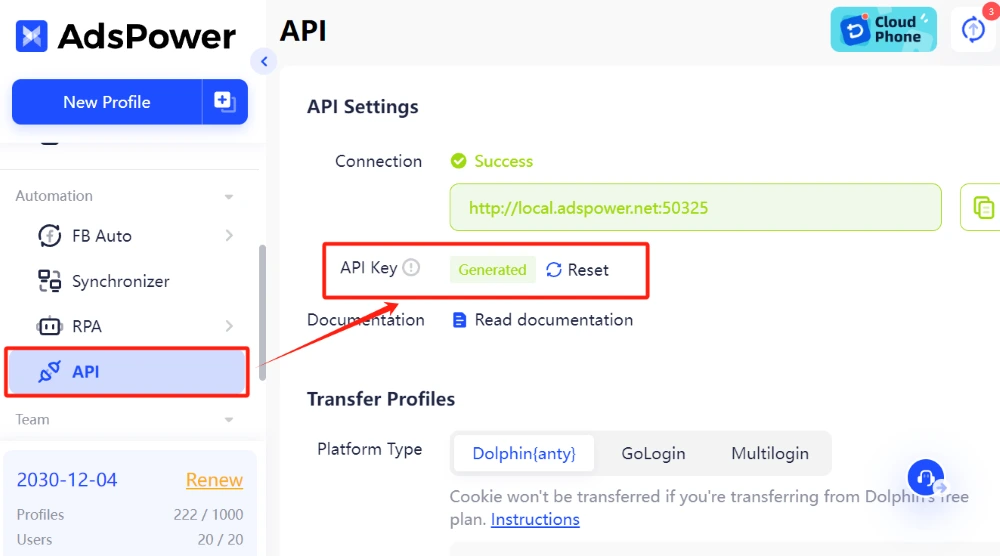
1. Gehen Sie in AdsPower zu API-Einstellungen und klicken Sie auf Generieren oder Zurücksetzen , um Ihren API-Schlüssel zu erhalten.
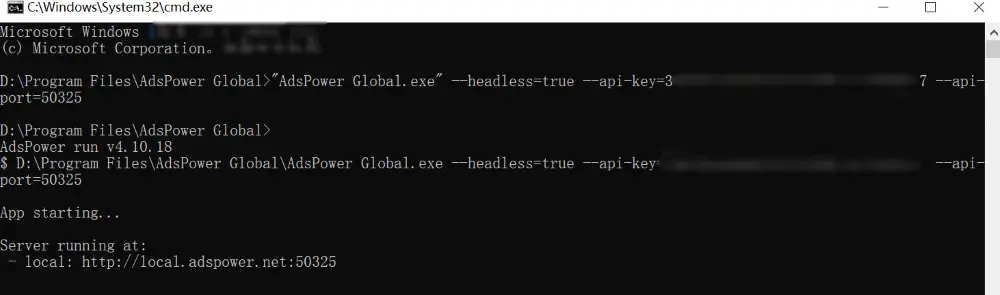
2. Starten Sie AdsPower im Headless-Modus (Öffnen Sie CMD oder Terminal im AdsPower-Stammverzeichnis)
- Windows: "AdsPower Global.exe" --headless=true --api-key=XXXX --api-port=50325
- macOS: "/Applications/AdsPower Global.app/Contents/MacOS/AdsPower Global" --args --headless=true --api-key=XXXX --api-port=50325
- Linux: adspower_global --headless=true --api-key=XXX --api-port=50325
3. Überprüfen Sie die Rücksprungadresse in der Befehlszeile, um den erfolgreichen Start zu bestätigen.
Vollständige Anleitung: AdsPower API-Dokumente – Headless-Modus
Wie unterscheiden sich Headless-Browser von normalen Browsern?
Stellen Sie es sich so vor: Normale Browser sind für die menschliche Interaktion konzipiert – mit Schaltflächen zum Anklicken, Seiten zum Scrollen und Bildern zum Bewundern –, während Headless-Browser die visuellen Elemente entfernen. Sie konzentrieren sich ausschließlich auf die Funktionalität und ermöglichen die programmgesteuerte Interaktion mit Websites. Es gibt wichtige Unterschiede, die Headless-Browser besonders für Automatisierungsaufgaben geeignet machen:
- Keine grafische Benutzeroberfläche: Headless-Browser arbeiten ohne visuelle Anzeige der Webseite, was für Serverumgebungen von Vorteil ist, da es den Rechenaufwand und den Ressourcenverbrauch reduziert. Das Fehlen visueller Rückmeldungen kann die Fehlersuche jedoch tatsächlich erschweren, da keine visuellen Hinweise zur Diagnose von Problemen vorhanden sind.
- Geschwindigkeit und Effizienz: Da keine visuellen Komponenten gerendert werden müssen, können Headless-Browser Seiten schneller laden und verarbeiten. Dadurch eignen sie sich ideal zum Scrapen großer Datenmengen oder zum Ausführen automatisierter Tests im großen Maßstab.
- Automatisierungsbereit: Headless-Browser werden mit Blick auf die Automatisierung entwickelt. Viele bieten APIs oder Frameworks, mit denen Entwickler Benutzeraktionen wie das Klicken auf Schaltflächen, das Ausfüllen von Formularen oder das Navigieren durch Seiten simulieren können.
- Skalierbarkeit: Da sie leichtgewichtig sind, können Sie mehrere Instanzen von Headless-Browsern gleichzeitig ausführen. Dadurch eignen sie sich perfekt für Aufgaben, die Skalierbarkeit erfordern, wie z. B. das Scraping von Tausenden von Seiten.
Die 10 besten Headless-Browser für Web Scraping
Wenn es um Web Scrapinggeht, sind nicht alle Headless-Browser gleich. Hier sind die wichtigsten Optionen, die Sie für eine effiziente und skalierbare Datenerfassung in Betracht ziehen sollten:
1. Puppeteer
Puppeteer ist eine JavaScript-Bibliothek, die eine High-Level-API zur Steuerung von Chrome oder Firefox über das DevTools-Protokoll oder WebDriver BiDi. Es ist ideal für die Handhabung JavaScript-lastiger Websites oder die Ausführung komplexer Browser-Automatisierungsaufgaben.
-
Unterstützte Sprachen: JavaScript, TypeScript, Python,.NET, Java
| Vorteile | Nachteile |
| Hochrangige API für Chrome-Automatisierung | Beschränkt auf Chromium-basierte Browser |
| Unterstützt erweiterte Interaktionen wie das Klicken auf Schaltflächen, das Aufnehmen von Screenshots und das Ausführen von JavaScript. | Erfordert Node.js-Umgebung |
| Aktive Community und regelmäßige Updates | Keine integrierte Unterstützung für mehrere Browser |
2. Playwright

Playwright, entwickelt von Microsoft, ist eine leistungsstarke Alternative zu Puppeteer. Es unterstützt mehrere Browser, darunter Chromium, Firefox und WebKit, und ist somit ein vielseitiges Tool für Web Scraping.
- Unterstützte Sprachen: JavaScript, TypeScript, Python,.NET, Java.
| Vorteile | Nachteile |
| Integrierte Netzwerk-Abfangfunktionen | Anspruchsvollerer Lernprozess für Neulinge |
| Integrierte mobile Emulation | Erfordert mehr Einrichtung im Vergleich zu Puppeteer |
| Leistungsstarker Auto-Wartemechanismus | Weniger Drittanbieterintegrationen als Selenium |
3. Selenium
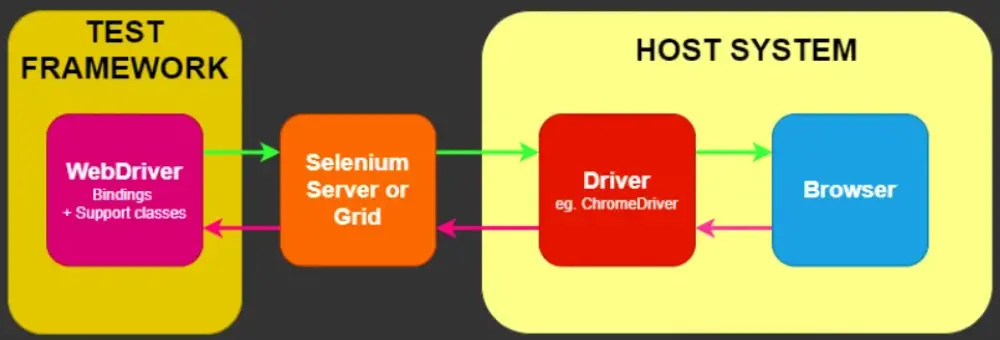
Selenium ist ein leistungsstarkes Browser-Automatisierungsframework, das verschiedene Tools und Bibliotheken für die Webautomatisierung integriert. Es wurde zur Einhaltung der W3C-WebDriver-Spezifikation entwickelt und bietet eine sprachübergreifende API, die mit allen gängigen Webbrowsern kompatibel ist. Obwohl es in erster Linie für automatisierte Tests bekannt ist, ist es aufgrund seines Headless-Modus eine gute Wahl für Web Scraping, insbesondere für Aufgaben mit Formularübermittlungen und komplexen Benutzerinteraktionen.
- Unterstützte Sprachen: Python, Java, C#, Ruby, JavaScript.
| Vorteile | Nachteile |
| Unterstützt mehrere Browser (Chrome, Firefox, Safari, Edge) | Langsamer als Puppeteer oder Playwright |
| Große Community und umfangreiche Dokumentation | Höherer Ressourcenverbrauch |
| In der Branche weithin anerkannt | Erfordert externe Treiber (z. B. GeckoDriver, ChromeDriver) |
4. Bright Data Scraping Browser
Bright Data Scraping Browser ist ein leistungsstarker Headless-Browser der Unternehmensklasse, der für groß angelegtes Web Scraping entwickelt wurde. Es bietet integriertes Proxy-Management, erweiterte Umgehung der Anti-Bot-Erkennung und Automatisierungstools zur Optimierung der Datenerfassung. Dies macht es zu einer ausgezeichneten Wahl für Unternehmen, die zuverlässige und effiziente Web-Scraping-Lösungen benötigen.
- Unterstützte Sprachen: Python, Node.js (JavaScript) und Java/C#
| Vorteile | Nachteile |
| Erweiterte Umgehung von Anti-Bot-Programmen | Kostenpflichtiger Dienst |
| Integrierte Proxy-Unterstützung | Erfordert Einrichtung und Konfiguration |
| Optimiert für Scraping im großen Maßstab | Nicht Open Source |
5. Headless Chrome
Headless Chrome ist kein eigenständiger Browser, sondern ein Modus von Google Chrome, der ohne grafische Oberfläche läuft. Als Teil von Google Chrome ist es eines der beliebtesten Tools für Web Scraping. Es ist zuverlässig, schnell und einfach einzurichten.
- Unterstützte Sprachen: JavaScript, Python (über Puppeteer oder Selenium), Java, C#, Ruby, Go und . NET.
| Vorteile | Nachteile |
| Schnell und zuverlässig | Beschränkt auf Chrome-basiertes Scraping |
| Direkte Unterstützung von Google | Erfordert manuelle Konfiguration für erweiterte Funktionen |
| Unterstützt zahlreiche Sprachen durch Bibliotheken von Drittanbietern | Kann bei umfangreichen Vorgängen ressourcenintensiv sein |
6. Headless Firefox
Headless Firefox ist ein Modus von Mozilla Firefox, der ohne grafische Benutzeroberfläche arbeitet und automatisierte Interaktionen mit Webseiten über Skripte ermöglicht. Wie Headless Chrome wird er häufig für Web Scraping, automatisierte Tests und Browserautomatisierung verwendet. Er kann über Selenium, SlimmerJS und W3C WebDriver gesteuert werden. Es ist ein leistungsstarkes Tool für Entwickler, die an Webprojekten arbeiten.
- Unterstützte Sprachen: JavaScript, Python (über Selenium).
| Vorteile | Nachteile |
| Funktioniert mit der Gecko-Engine von Firefox | Langsamer als Chrome-basierte Headless-Browser |
| Unterstützt die Ausführung von JavaScript | Erfordert zusätzliche Einrichtung |
| Ähnliche Funktionalität wie Headless Chrome | Weniger beliebt als andere Tools |
7. chromedp
Chromedp ist eine schnellere und einfachere Möglichkeit, Browser zu betreiben, die das Chrome DevTools Protocol in Go unterstützen, ohne externe Abhängigkeiten. Es ist eine großartige Wahl für einfache Scraping- und Automatisierungsaufgaben. Die fehlende Unterstützung mehrerer Browser schränkt jedoch die Flexibilität für einige Benutzer ein.
- Unterstützte Sprachen: Go.
| Vorteile | Nachteile |
| Native Go-Implementierung | Beschränkt auf Chrome-basiertes Scraping |
| Leichtgewichtig und effizient | Erfordert Kenntnisse in der Go-Entwicklung |
| Minimale Abhängigkeiten | Keine Unterstützung für mehrere Browser |
8. Cypress
Cypress ist in erster Linie ein Test-Framework, kann aber in bestimmten Szenarien auch für Web Scraping verwendet werden. Es bietet integrierte Automatisierung, Echtzeit-Debugging und eine leistungsstarke API für die Interaktion mit Webseiten. Es ist jedoch nicht für groß angelegtes Scraping optimiert wie einige andere Headless-Browser.
- Unterstützte Sprachen: JavaScript.
| Vorteile | Nachteile |
| Benutzerfreundliches Test-Framework | Nicht für Scraping im großen Maßstab konzipiert |
| Integrierte Warte- und Wiederholungsmechanismen | Eingeschränkte Browserunterstützung (Chrome-basiert) |
| Umfangreiche Debugging-Funktionen | Erfordert GUI für einige Interaktionen |
9. Zombie.js
Zombie.js ist ein leichtes, Node.js-kompatibles Framework für automatisierte clientseitige JavaScript-Tests. Es ist ideal für einfaches Web Scraping und verfügt über eine umfassende API mit integrierter Unterstützung für Cookies, Tabs, Authentifizierung und Assertionen, wodurch effiziente und robuste Testszenarien gewährleistet werden.
- Unterstützte Sprachen: JavaScript.
| Vorteile | Nachteile |
| Eine API mit vollem Funktionsumfang | Veraltet und in den letzten Jahren weniger aktive Entwicklung |
| Leichtgewichtig und schnell | Eingeschränkte Browserfunktionen |
| Integration mit Node.js-Projekten | Nicht geeignet für Szenarien, die echtes Browser-Rendering erfordern |
10. HtmlUnit
HtmlUnit ist ein Java-basierter Headless-Browser, der Erweiterte Interaktion mit Websites über Java-Anwendungen. Es ermöglicht Aufgaben wie das Absenden von Formularen, die Navigation über Hyperlinks und den detaillierten Zugriff auf Inhalt und Struktur von Webseiten, wodurch eine umfassende Bearbeitung und Analyse von Webseiten möglich wird.
- Unterstützte Sprachen: Java.
| Vorteile | Nachteile |
| Leicht und schnell | Eingeschränkte JavaScript-Unterstützung |
| Kontinuierliche Verbesserung | Weniger aktive Community |
| Unterstützt komplexe AJAX-Bibliotheken; simuliert Chrome, Firefox oder Edge basierend auf der Konfiguration | Kann Schwierigkeiten bei der Handhabung moderner Websites mit umfangreicher JavaScript-Ausführung haben |
FAQ
1. Wie steuert man einen Headless-Browser zum Testen und Web Scraping?
Die Steuerung eines Headless-Browsers beinhaltet normalerweise die Verwendung von APIs oder Frameworks. Zum Beispiel:
- Puppeteer: Verwenden Sie die Node.js-Bibliothek, um Interaktionen wie das Navigieren durch Seiten und das Extrahieren von Daten zu skripten.
- Selenium: Schreiben Sie Skripte in Ihrer bevorzugten Programmiersprache, um Browseraktionen zu automatisieren.
- Playwright: Nutzen Sie die Multi-Browser-Unterstützung, um komplexe Szenarien zu bewältigen.
2. Welcher ist der beste leichte Headless-Browser?
Wenn Geschwindigkeit und Ressourceneffizienz für Sie Priorität haben, sollten Sie Headless Chromeoder PhantomJSverwenden. Während Headless Chrome aktiv gepflegt wird und moderne Webstandards unterstützt, ist PhantomJS für grundlegende Aufgaben immer noch nützlich.
3. Kann ein Fingerprint-Browser (Headless-Modus) als echter Headless-Browser verwendet werden?
Ein Fingerprint-Browser im Headless-Modus bietet ähnliche Funktionen wie ein herkömmlicher Headless-Browser, ist aber nicht ganz dasselbe. Es ermöglicht zwar automatisiertes Browsen ohne sichtbare Benutzeroberfläche, speichert und modifiziert aber auch Fingerabdrücke, um das Erkennungsrisiko zu verringern. Einige erweiterte Automatisierungsfunktionen herkömmlicher Headless-Browser werden jedoch möglicherweise nicht vollständig unterstützt.
Zusammenfassung
Headless-Browser sind unverzichtbare Tools für das Web Scraping, da sie Geschwindigkeit, Effizienz und Skalierbarkeit bieten. Egal, ob Sie Anfänger oder erfahrener Entwickler sind, die Wahl des richtigen Headless-Browsers kann bei Ihren Scraping-Projekten einen großen Unterschied machen. Bei groß angelegtem Web Scraping kann die Kombination eines Headless-Browsers mit AdsPower Ihnen helfen, eine Erkennung zu vermeiden, indem digitale Fingerabdrücke maskiert werden, was eine reibungslosere Automatisierung gewährleistet. Testen Sie AdsPower noch heute kostenlos und bringen Sie Ihre Scraping-Effizienz auf die nächste Stufe!

Leute lesen auch
- Die 12 besten Spiele, die von der Schule nicht gesperrt werden (+ einfache Lösungen)

Die 12 besten Spiele, die von der Schule nicht gesperrt werden (+ einfache Lösungen)
Entdecke 12 kostenlose, nicht blockierte Spiele für die Schule und lerne praktische Wege kennen, um auf gesperrte Spiele-Websites zuzugreifen.
- Wie man im Jahr 2026 mehrere Apple-Konten sicher verwaltet

Wie man im Jahr 2026 mehrere Apple-Konten sicher verwaltet
Erfahren Sie mit praktischen Tipps, wie Sie mehrere Apple-Konten sicher verwalten.
- Wie man 2026 mit Substack Geld verdient: Umsatzstrategien für Content-Ersteller

Wie man 2026 mit Substack Geld verdient: Umsatzstrategien für Content-Ersteller
Möchtest du mit Substack Geld verdienen? Dieser Leitfaden erklärt bewährte Monetarisierungsmethoden, gibt Wachstumstipps und zeigt, wie Content-Ersteller ihre Inhalte in Einnahmen verwandeln.
- Claude nicht erreichbar oder ausgefallen? So diagnostizieren und beheben Sie häufige Probleme

Claude nicht erreichbar oder ausgefallen? So diagnostizieren und beheben Sie häufige Probleme
Ist Claude nicht erreichbar oder erhalten Sie Fehlermeldungen wie „Claude nicht erreichbar“? Erfahren Sie, wie Sie Anmeldeschleifen, Authentifizierungsfehler, Netzwerkprobleme und mehr beheben.
- Instagram gesperrt und dann verbannt? So erhalten Sie Ihr Konto zurück

Instagram gesperrt und dann verbannt? So erhalten Sie Ihr Konto zurück
Wurde Ihr Instagram-Konto gesperrt und anschließend deaktiviert? Dieser Leitfaden erklärt, was zu tun ist und wie Sie ein vorübergehend gesperrtes oder deaktiviertes Konto wiederherstellen können.
