
Como evitar CAPTCHA no web scraping em 2026
Dê uma olhada rápida
Os bloqueios de CAPTCHA muitas vezes são decorrentes de IPs fracos, fingerprints repetidos ou comportamentos semelhantes a bots. Para evitar CAPTCHA no web scraping, foque em proxies limpos, ambientes de navegação consistentes e padrões de interação realistas. Ferramentas como o AdsPower ajudam você a gerenciar fingerprints e sessões de forma mais confiável, o que reduz as detecções e mantém o seu fluxo de scraping funcionando por mais tempo.
As verificações de CAPTCHA tornaram-se mais rigorosas, especialmente para o scraping em grande escala. O que funcionava há alguns anos não se sustenta mais. Atualmente, muitos scrapers enfrentam interrupções frequentes, falhas em requisições ou bloqueios de sessão.
Não perca estas formas práticas de evitar CAPTCHA no web scraping. Em vez de truques rápidos, o foco é construir uma infraestrutura que permaneça estável ao longo do tempo.
Por que os sites acionam CAPTCHA para scrapers?
Os sites não exibem CAPTCHA de forma aleatória. Geralmente, ele aparece quando algo parece suspeito.
A maioria dos acionamentos se enquadra em algumas categorias:
|
Tipo de acionamento |
O que acontece na prática |
|
Reputação do IP |
IPs compartilhados ou sinalizados são bloqueados rapidamente |
|
Comportamento da requisição |
Muitas ações em um curto período |
|
Reutilização de fingerprint |
Várias sessões parecem idênticas |
|
Dados de sessão ausentes |
Sem cookies ou histórico de navegação |
|
Padrões de interação |
Nenhum movimento de mouse ou cliques instantâneos |
Plataformas como o reCAPTCHA dependem de uma combinação desses sinais. Se vários parecerem suspeitos ao mesmo tempo, um desafio é acionado.
Você pode conferir como o Google avalia os sinais de tráfego aqui: https://developers.google.com/recaptcha
Como funciona a detecção de CAPTCHA em 2026
Para reduzir a frequência do CAPTCHA, é fundamental entender o que está sendo medido nos bastidores.
Avaliação de IP e tráfego
Toda requisição está vinculada a um endereço IP. Os sites analisam:
-
Se o IP pertence a um usuário real ou a um data center
-
A frequência com que ele envia requisições
-
Se a localização muda com muita frequência
Um IP residencial limpo com tráfego moderado tem muito menos probabilidade de acionar um CAPTCHA.
Browser Fingerprinting
É aqui que muitas configurações falham. Os sites coletam detalhes como:
-
Versão do navegador
-
Sistema operacional
-
Tamanho da tela
-
Renderização gráfica
-
Fontes instaladas
Se dez sessões compartilham o mesmo fingerprint, elas não parecem ser de dez usuários reais. Parecem ser de um único script.
Análise de comportamento
A automação costuma se comportar de maneira previsível. Por exemplo:
-
Clicar sem rolar a página
-
Carregar páginas muito rápido
-
Repetir o mesmo padrão de tempo
Esses sinais são fáceis de detectar quando se repetem.
Confiança de sessão e cookies
Alguns sistemas atribuem pontuações de confiança com base no histórico da sessão. Por exemplo:
-
Usuários recorrentes com cookies válidos enfrentam menos desafios
-
Sessões novas são testadas com mais frequência
O Google reCAPTCHA v3 se baseia fortemente nesse modelo de pontuação.
Tipos de CAPTCHA que você vai encontrar
Nem todos os sistemas de CAPTCHA funcionam da mesma forma. Existem sites diferentes que usam níveis variados de proteção.
|
Tipo de CAPTCHA |
Dificuldade |
Observações |
|
Baseado em texto |
Baixa |
Sistemas mais antigos, mais fáceis de resolver |
|
Seleção de imagens |
Média |
Comum no reCAPTCHA |
|
Caixa de seleção (v2) |
Média |
Geralmente apoiado por verificações mais profundas |
|
Invisível (v3) |
Alta |
Baseado em pontuação de comportamento |
|
Quebra-cabeças interativos |
Alta |
Sliders (deslizadores), ações de arrastar, etc. |
Conhecer o tipo de CAPTCHA ajuda a decidir se você deve evitá-lo ou resolvê-lo.
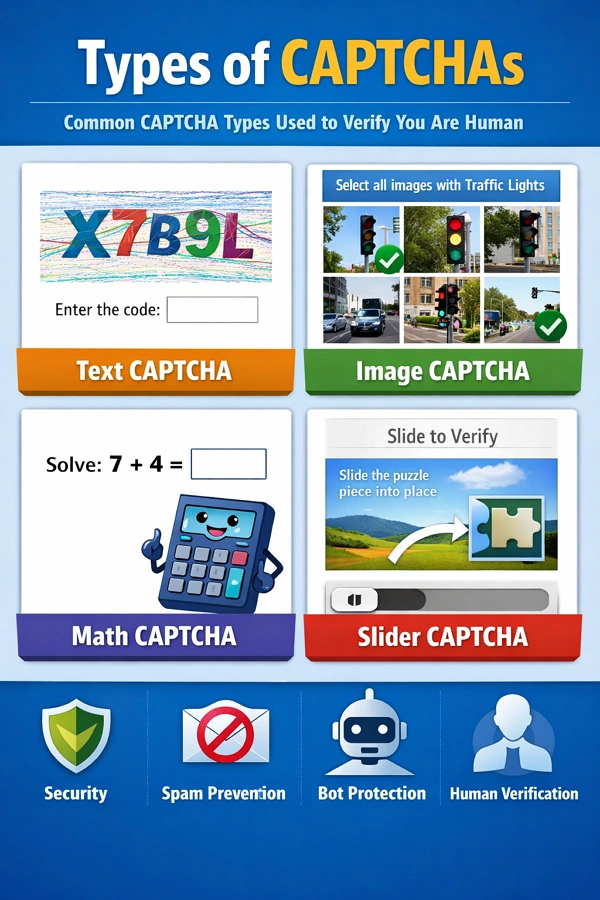
CAPTCHA baseado em texto
Letras ou números distorcidos. Menos comum hoje em dia, mas ainda usado em sites menores.
CAPTCHA de reconhecimento de imagem
Selecionar imagens com semáforos, carros ou faixas de pedestres. Muito usado no reCAPTCHA.
CAPTCHA de caixa de seleção (reCAPTCHA v2)
Simples caixa de seleção "Não sou um robô". Frequentemente acompanhado por verificações ocultas mais profundas.
CAPTCHA invisível (reCAPTCHA v3)
Nenhum desafio visível. Os usuários recebem uma pontuação silenciosamente com base no comportamento.
CAPTCHA interativo
Inclui sliders, quebra-cabeças ou tarefas de arrastar e soltar. Comum em provedores antibot como o hCaptcha.
É possível evitar CAPTCHA no web scraping completamente?
Em resumo, não.
Mesmo sistemas bem configurados ainda encontram CAPTCHA ocasionalmente. O objetivo é reduzir a frequência com que ele aparece e manter as sessões ativas por mais tempo.
Uma configuração estável faz três coisas muito bem:
- Mantém identidades consistentes
- Evita picos suspeitos de atividade
- Constrói a confiança da sessão ao longo do tempo
Formas de evitar CAPTCHA no web scraping
Evitar CAPTCHA não se resume a um único truque. Trata-se de reduzir os sinais de risco em toda a sua infraestrutura. Os métodos abaixo focam em mudanças práticas que fazem o seu tráfego parecer mais com o de usuários reais.
1. Construa uma identidade consistente (Proxy + Fingerprint + Ambiente de Navegação)
Essa é a base de tudo.
Uma sessão de scraping deve se comportar como um único usuário real. Isso significa:
- Um endereço IP por sessão
- Um único browser fingerprint
- Um perfil de navegador isolado
Se esses elementos não baterem, os sites poderão detectar inconsistências facilmente.
O uso de um navegador antidetect ajuda a gerenciar isso em grande escala. Em vez de ajustar as configurações manualmente, cada perfil já possui uma identidade consistente.
2. Use proxies residenciais ou móveis de alta qualidade
O seu endereço IP desempenha um papel importante na exibição de CAPTCHAs.
Aqui está uma comparação rápida dos diferentes tipos de proxies:
|
Tipo de proxy |
Risco de CAPTCHA |
Observações |
|
Datacenter |
Alto |
Rápido, mas frequentemente sinalizado |
|
Baixo |
Parece com usuários reais |
|
|
Móvel |
Muito baixo |
Maior confiança, custo mais alto |
Evite proxies gratuitos desconhecidos. Eles geralmente são reutilizados e já estão bloqueados.
3. Alterne os IPs por sessão, não por requisição
A rotação aleatória pode criar padrões não naturais.
Uma abordagem melhor:
-
Mantenha o mesmo IP durante uma sessão
-
Alterne apenas ao iniciar uma nova sessão
-
Alinhe a localização do IP com as configurações do navegador
Isso mantém o comportamento consistente e reduz suspeitas.
4. Mantenha sessões persistentes (Cookies e Armazenamento)
Novas sessões são tratadas com cautela.
Para construir confiança ao longo do tempo:
-
Salve os cookies após cada sessão
-
Reutilize-os ao retornar
-
Evite limpar o armazenamento com muita frequência
Uma sessão com histórico tem menos probabilidade de enfrentar desafios repetidos.
5. Controle a frequência e o tempo das requisições
A velocidade é um indício comum para ser detectado. Em vez de enviar requisições rápidas:
-
Adicione atrasos (delays) entre as ações
-
Distribua as tarefas ao longo do tempo
-
Evite picos repentinos de atividade
Pense em como uma pessoa real navega. O padrão raramente é uniforme.
No processo do AdsPower RPA, você consegue configurar a posição, a ordem ou o tempo das ações dos elementos.
6. Simule o comportamento de um usuário real
O comportamento importa tanto quanto a configuração técnica. Pequenos ajustes ajudam:
-
Faça a rolagem antes de clicar
-
Mova-se entre as páginas com naturalidade
-
Evite padrões de tempo idênticos
Até mesmo uma simulação básica de interação pode reduzir as taxas de detecção.
7. Evite detecções fracas de navegadores headless
Os navegadores headless (sem interface gráfica) são úteis, mas fáceis de identificar se não forem modificados.
Se for usá-los, certifique-se de que:
-
Os recursos do navegador estão totalmente ativados
-
As flags de automação estão ocultas
-
O comportamento de renderização parece normal
Se você depende de scraping via headless, use configurações stealth (furtivas) ou mude para ambientes de navegador completos quando possível.
8. Lide com os CAPTCHAs de forma estratégica (não tente apenas evitá-los)
Evitar funciona na maioria das vezes, mas não sempre.
Em alguns casos, resolver o CAPTCHA é mais eficiente:
-
Use serviços de resolução baseados em humanos para obter precisão
-
Use solucionadores baseados em IA para obter velocidade
-
Combine ambos para obter um equilíbrio
Isso garante que seu fluxo de trabalho não pare quando um CAPTCHA aparecer.
9. Evite armadilhas ocultas para bots
Muitos sites incluem armadilhas invisíveis criadas para bots.
Alguns exemplos:
-
Campos de formulário ocultos (honeypots)
-
Elementos invisíveis para os usuários
-
Verificações de detecção baseadas em JavaScript
Para reduzir o risco:
-
Sempre renderize as páginas totalmente
-
Interaja apenas com os elementos visíveis
-
Valide a estrutura da página antes das ações
10. Alinhe sua configuração ao contexto de um usuário real
Um erro comum é a incompatibilidade de sinais.
Por exemplo:
-
IP dos EUA com fuso horário asiático
-
IP móvel com fingerprint de desktop
-
Configurações de idioma que não correspondem à localização
Essas inconsistências acionam os alertas rapidamente.
Certifique-se de que:
-
A localização do IP
-
O fuso horário
-
O idioma
-
O tipo de dispositivo
tudo esteja perfeitamente alinhado de forma natural.
Resumo rápido
Uma configuração de scraping estável geralmente combina:
|
Camada |
No que focar |
|
Rede |
IPs limpos e confiáveis |
|
Ambiente |
Fingerprints únicos |
|
Comportamento |
Interação semelhante à humana |
|
Sessão |
Cookies persistentes |
Quando essas camadas trabalham juntas, o CAPTCHA aparece com muito menos frequência.
Como o AdsPower atua para resolver CAPTCHA no web scraping
Quando você gerencia várias sessões de scraping, o controle do ambiente se torna o principal desafio. O AdsPower foi projetado exatamente para lidar com isso.
Fingerprints independentes para cada perfil
Cada perfil de navegador no AdsPower possui seu próprio fingerprint exclusivo.
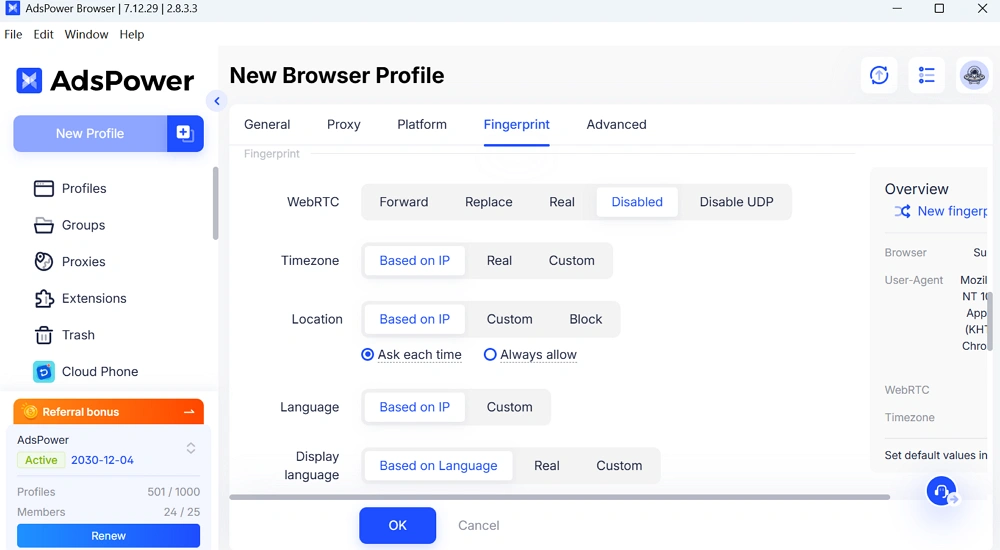
Com essas configurações no seu perfil, isso significa que:
- As sessões não se sobrepõem
- As contas permanecem separadas
- O risco de detecção é reduzido
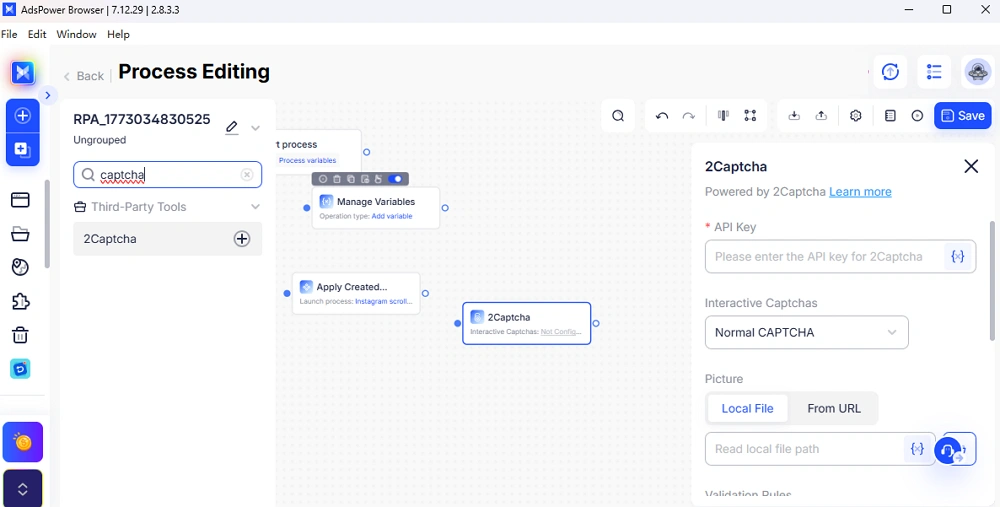
Automação RPA com integração de CAPTCHA
O AdsPower inclui recursos de automação RPA que ajudam a automatizar fluxos de trabalho.
Você pode:
- Executar tarefas repetitivas
- Integrar solucionadores de CAPTCHA de terceiros
- Manter um comportamento consistente em todas as sessões
Suporte a extensões para solucionar CAPTCHA
O AdsPower oferece suporte direto a extensões de navegador.
Você pode instalar extensões populares de solução de CAPTCHA do Google para automatizar seus processos.
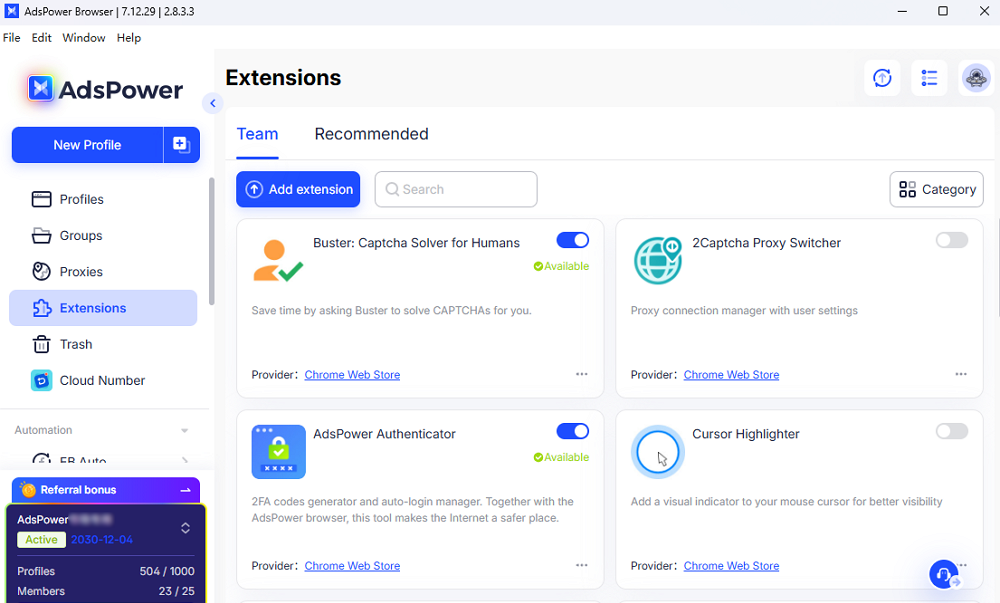
Isso facilita a combinação de estratégias para evitar e solucionar CAPTCHAs.
👉 Você pode explorar o AdsPower e testar como os perfis de navegador isolados melhoram a estabilidade do scraping.
Perguntas Frequentes (FAQs):
Qual é o melhor tipo de proxy para evitar CAPTCHA?
Os proxies residenciais são a escolha mais prática para a maioria dos casos de uso. Eles oferecem maior confiabilidade em comparação aos IPs de datacenter. Os proxies móveis têm um desempenho ainda melhor, mas são mais caros.
O web scraping headless sempre aciona CAPTCHA?
Nem sempre, mas as configurações padrão geralmente sim.
Navegadores headless podem expor sinais que navegadores normais não expõem. Sem os ajustes adequados, a detecção acontece rapidamente.
O AdsPower pode ajudar a reduzir a frequência dos CAPTCHAs?
Sim. O AdsPower melhora a consistência do ambiente.
Com fingerprints isolados e sessões estáveis, suas requisições parecem muito mais com as de usuários reais. Isso reduz a frequência com que os CAPTCHAs aparecem, especialmente em configurações de múltiplas contas.
Considerações Finais
Para evitar CAPTCHA no web scraping, concentre-se na consistência em vez de tentar atalhos.
Uma configuração confiável combina:
- IPs limpos
- Ambientes de navegador únicos
- Padrões de interação realistas
Se você gerencia várias contas ou executa tarefas de scraping diariamente, usar um ambiente de navegador controlado, como o AdsPower, pode tornar seu fluxo de trabalho mais estável ao longo do tempo.
👉 Registre-se no AdsPower para criar seu primeiro perfil e testar uma configuração de scraping mais segura.

As pessoas também leem
- Como fazer dropshipping do AliExpress para a Amazon em 2026 (Guia passo a passo)

Como fazer dropshipping do AliExpress para a Amazon em 2026 (Guia passo a passo)
Aprenda como fazer dropshipping do AliExpress para a Amazon em 2026, desde a pesquisa de produtos e verificação de fornecedores até as regras da Amazon, gerenciamento de pedidos e segurança para vendedores.
- O Que É um Proxy no Telegram? Como Usar Proxy SOCKS5 no Telegram

O Que É um Proxy no Telegram? Como Usar Proxy SOCKS5 no Telegram
Quer usar o Telegram com um proxy SOCKS5? Aqui está um guia simples sobre proxies para Telegram, passos de configuração para celular e PC, dicas de privacidade e segurança do proxy.
- Diagnóstico de Rede AdsPower: Corrija Falhas na Conexão de Proxy Rapidamente

Diagnóstico de Rede AdsPower: Corrija Falhas na Conexão de Proxy Rapidamente
Resolva falhas de conexão de proxy, erros de rede e problemas de IP com o Diagnóstico de Rede AdsPower. Identifique e corrija problemas rapidamente.
- Não consegue iniciar sessão na Vestiaire Collective ou criar uma nova conta? Veja o que fazer.

Não consegue iniciar sessão na Vestiaire Collective ou criar uma nova conta? Veja o que fazer.
Está com problemas para acessar sua conta Vestiaire Collective, seja para fazer login ou se cadastrar? Este guia explica os problemas mais comuns de acesso à conta, por que eles acontecem e como compradores e vendedores podem resolvê-los.
- Como gerenciar proxies de forma eficiente e resolver problemas de falha de proxy

Como gerenciar proxies de forma eficiente e resolver problemas de falha de proxy
Aprenda como gerenciar proxies e resolver problemas de falha de proxy no AdsPower.
