
5 cách hiệu quả để quét web mà không bị chặn

Bạn có biết rằng khoảng 47% tổng lưu lượng truy cập internet được tạo ra bởi các bot, bao gồm cả các trình thu thập dữ liệu web? Trong thế giới kỹ thuật số nơi dữ liệu là tất cả, việc trích xuất thông tin từ web đã trở nên quan trọng đối với nhiều doanh nghiệp.
Tuy nhiên, mặc dù rất cần thiết nhưng quá trình này phải đối mặt với những thách thức, từ CAPTCHA chặn quyền truy cập tự động vào các honeypot thu hút và phát hiện bot.
Nhưng trọng tâm của chúng tôi không phải là những trở ngại này. Chúng tôi ở đây để khám phá các giải pháp hiệu quả nhằm khắc phục chúng và cho phép quét web dễ dàng mà không bị chặn.
Bài viết này mô tả năm cách để quét web thành công mà không bị chặn. Chúng tôi đề cập đến nhiều kỹ thuật khác nhau, từ việc sử dụng trình duyệt chống phát hiện phức tạp đến lên lịch cho các tác vụ thu thập dữ liệu của bạn trong thời gian ít bận rộn hơn.
Bằng cách triển khai các phương pháp này, bạn sẽ không chỉ giảm nguy cơ bị chặn mà còn tăng hiệu quả và quy mô hoạt động quét web của mình.
Hãy đi sâu vào và giúp bạn thu thập dữ liệu quan trọng mà không gặp trở ngại.
Những thách thức trong việc quét web
Những rủi ro và thách thức đối với việc thu thập dữ liệu bao gồm từ các rào cản kỹ thuật cho đến việc các trang web cố tình đặt bẫy. Hiểu những thách thức này là một bước quan trọng trong việc đưa ra chiến lược quét web mạnh mẽ.
Dưới đây, chúng tôi nêu bật một số thách thức phổ biến nhất mà những người quét web phải đối mặt.
5 cách để thực hiện quét web mà không bị chặn

Trong khi những thách thức đối với việc quét web là rất nhiều. Mỗi người trong số họ đều có giải pháp để vượt qua chúng. Hãy khám phá những kỹ thuật này và hiểu cách chúng có thể tạo điều kiện thuận lợi cho việc quét web mà không bị chặn.
Trình duyệt “không đầu” (chương trình giả lập một trình duyệt nhưng không có giao diện người dùng )
Một cách để quét web mà không bị chặn là kỹ thuật được gọi là quét web không đầu. Cách tiếp cận này liên quan đến việc sử dụng trình duyệt không đầu - một loại trình duyệt không có Giao diện người dùng đồ họa (GUI). Trình duyệt không có giao diện người dùng có thể mô phỏng hoạt động duyệt web của người dùng thông thường, giúp bạn không bị phát hiện bởi các trang web sử dụng Javascript để theo dõi và chặn những kẻ quét web.
Các trình duyệt này đặc biệt hữu ích khi trang web mục tiêu được tải bằng các phần tử Javascript vì trình quét HTML truyền thống thiếu khả năng hiển thị các trang web đó giống như người dùng thực.
Các trình duyệt phổ biến như Chrome và Firefox có chế độ không có giao diện người dùng, nhưng bạn vẫn cần phải điều chỉnh hành vi của chúng để có vẻ chân thực. Hơn nữa, bạn có thể thêm một lớp bảo vệ khác bằng cách kết hợp các trình duyệt không có đầu với proxy để che giấu IP của bạn và ngăn chặn các lệnh cấm.
Bạn có thể điều khiển Chrome không đầu theo chương trình thông qua Puppeteer, cung cấp API cấp cao để duyệt các trang web và thực hiện hầu hết mọi thứ trên đó.
Ví dụ: đây là tập lệnh Puppeteer đơn giản để tạo một phiên bản trình duyệt, chụp ảnh màn hình của một trang web rồi đóng phiên bản đó.
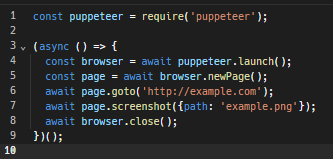
Đây là hướng dẫn chi tiết về cách thực hiện duyệt không đầu bằng Puppeteer.
Quét trong giờ thấp điểm
Quét liên quan đến việc duyệt các trang web với tốc độ rất nhanh, một hành vi không phổ biến ở những người dùng thông thường. Điều này có thể dẫn đến tải máy chủ cao và làm chậm dịch vụ đối với người khác. Do đó, quản trị viên trang web có thể nhận thấy trình quét và loại bỏ nó khỏi máy chủ.
Vì vậy, một bước đi thông minh để quét web mà không bị chặn là thực hiện việc đó trong giờ cao điểm của trang web. Đây là lúc các trang web thường ít cảnh giác hơn. Và ngay cả khi các hoạt động thu thập thông tin của bạn tiêu tốn nhiều tài nguyên máy chủ, điều đó có thể không đủ để khiến máy chủ cạn kiệt và thu hút sự chú ý của quản trị viên.
Tuy nhiên, vẫn có khả năng bị bắt. Một số trang web có thể áp dụng các biện pháp phức tạp để giám sát hoạt động của người dùng ngay cả trong thời gian yên tĩnh hơn. Ngoài ra, việc xác định giờ thấp điểm của một trang web có thể khó khăn nếu thông tin có sẵn không cập nhật.
Sử dụng trình duyệt chống phát hiện
Trình duyệt chống phát hiện là một công cụ toàn diện được thiết kế để giữ cho người dùng ẩn danh và ẩn các hoạt động trực tuyến của họ khỏi các trang web họ truy cập. Nó hoạt động bằng cách che giấu hoặc thay đổi dấu vân tay kỹ thuật số của trình duyệt của người dùng, thường bao gồm các chi tiết như loại trình duyệt, plugin, độ phân giải màn hình và múi giờ, tất cả đều được các trang web sử dụng để theo dõi hoạt động của người dùng.
Điều này làm cho trình duyệt chống phát hiện trở nên lý tưởng để quét web mà không bị chặn. Tuy nhiên, điều quan trọng cần lưu ý là những trình duyệt này chỉ giảm thiểu rủi ro bị phát hiện; chúng không hoàn toàn không thể sai lầm đối với tất cả các trang web. Do đó, việc chọn trình duyệt chống phát hiện tốt nhất để quét web là chìa khóa để giảm thiểu nguy cơ bị phát hiện.
Một trình duyệt chống phát hiện tốt để quét web là AdsPower . Nó sử dụng các kỹ thuật cụ thể để trốn tránh các biện pháp chống cào, chẳng hạn như:
Bên cạnh những tính năng này, AdsPower còn cung cấp các lợi ích bổ sung như tự động thu thập dữ liệu và nhiều cấu hình trình duyệt để tăng tốc quá trình thu thập dữ liệu.
Tự động giải CAPTCHA hoặc sử dụng dịch vụ trả phí
Để bỏ qua CAPTCHA trong khi quét web mà không bị chặn, bạn có một số tùy chọn. Trước tiên, hãy xem xét liệu bạn có thể lấy được thông tin cần thiết mà không cần truy cập vào các phần được bảo vệ bằng CAPTCHA hay không, vì việc viết mã một giải pháp trực tiếp là một thách thức.
Tuy nhiên, nếu việc truy cập những phần này là quan trọng, bạn có thể sử dụng dịch vụ giải CAPTCHA. Các dịch vụ này, chẳng hạn như 2Captcha và Anti Captcha, sử dụng người thật để giải CAPTCHA cho bài kiểm tra tính phí cho mỗi lần giải. Nhưng hãy nhớ rằng việc chỉ phụ thuộc vào những dịch vụ này có thể khiến ví của bạn bị hao hụt.
Ngoài ra, các công cụ quét web chuyên dụng như công cụ thu thập dữ liệu của ZenRows' D và Oxylabs có thể tự động vượt qua CAPTCHA. Những công cụ này sử dụng thuật toán học máy tiên tiến để giải CAPTCHA nhằm đảm bảo hoạt động thu thập dữ liệu của bạn tiếp tục suôn sẻ.
Bẫy mật ong (Honeypot)
Để xử lý hiệu quả các bẫy honeypot trong khi quét web mà không bị chặn, điều quan trọng là phải nhận biết và tránh chúng. Bẫy Honeypot là các cơ chế được thiết kế để thu hút và xác định các bot, thường hiển thị dưới dạng các liên kết vô hình trong mã HTML của trang web, ẩn với mọi người nhưng những người quét web có thể phát hiện được.
Một chiến lược là lập trình trình thu thập thông tin hoặc trình quét của bạn để xác định các liên kết được ẩn đối với người dùng thông qua các thuộc tính CSS. Ví dụ: tránh đi theo các liên kết văn bản hòa vào màu nền, vì đây là một chiến thuật nhằm cố tình che giấu các liên kết khỏi mắt người.
Đây là một hàm JavaScript cơ bản để phát hiện các liên kết vô hình như vậy.
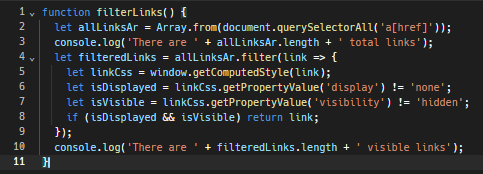
Ngoài ra, việc tôn trọng tệp robots.txt của trang web là rất quan trọng. Tệp này dành cho bot và đưa ra những điều nên làm và không nên làm khi thu thập dữ liệu. Nó cung cấp thông tin về các khu vực của trang web bị giới hạn và các phần được phép cạo. Tuân theo những quy tắc này là một cách làm tốt và có thể giúp bạn tránh xa bẫy honeypot.
Kết thúc!
Chắc chắn, có những biện pháp chống thu thập ngăn chúng tôi truy cập dữ liệu có giá trị trên các trang web mục tiêu và đôi khi khiến chúng tôi bị cấm vĩnh viễn. Nhưng không có thách thức nào trong số này là không thể vượt qua.
Bạn có thể sử dụng các công cụ như trình duyệt không có giao diện người dùng để bắt chước hoạt động duyệt thực, quét trong những giờ ít bận rộn hơn để tránh bị phát hiện và sử dụng các trình duyệt chống phát hiện như AdsPower để ẩn dấu vân tay của bạn. Hơn nữa, cũng có nhiều cách để vượt qua CAPTCHA và né bẫy honeypot.
Với những chiến thuật này, bạn có thể dễ dàng quét web thành công mà không bị chặn. Vì vậy, hãy vượt ra ngoài cách tiếp cận trúng hoặc trượt và bắt đầu tìm kiếm theo cách thông minh.

Mọi người cũng đọc
- Instagram bị khóa rồi cấm? Làm thế nào để lấy lại?

Instagram bị khóa rồi cấm? Làm thế nào để lấy lại?
Instagram đã khóa tài khoản của bạn rồi cấm sử dụng? Hướng dẫn này sẽ chỉ cho bạn những việc cần làm và cách khôi phục tài khoản bị khóa hoặc vô hiệu hóa tạm thời.
- Làm Thế Nào Để Kiếm Tiền Trên Kwai Năm 2026?

Làm Thế Nào Để Kiếm Tiền Trên Kwai Năm 2026?
Tìm hiểu cách kiếm tiền trên Kwai vào năm 2026 thông qua các chương trình nhà sáng tạo, livestream, tiếp thị liên kết (affiliate), tài trợ thương hiệu và các mẹo mở rộng quy mô với AdsPower.
- Tài khoản Avakin Life của bạn bị tạm khóa? Đây là những việc cần làm.

Tài khoản Avakin Life của bạn bị tạm khóa? Đây là những việc cần làm.
Bạn đang thắc mắc tại sao tài khoản Avakin Life của mình bị tạm ngưng vào năm 2026? Hãy tìm hiểu các nguyên nhân có thể xảy ra, từ các vấn đề đăng nhập và khôi phục đến vi phạm quy tắc, cùng với những thông tin khác.
- Trình duyệt chống phát hiện AdsPower và thương mại điện tử

Trình duyệt chống phát hiện AdsPower và thương mại điện tử
AdsPower có thể giúp bạn phát triển doanh nghiệp thương mại điện tử như thế nào?
- AdsPower và cá cược - chênh lệch tỷ lệ cược trong cá cược là gì và cách sử dụng nhiều tài khoản trong trường hợp này?
AdsPower và cá cược - chênh lệch tỷ lệ cược trong cá cược là gì và cách sử dụng nhiều tài khoản trong trường hợp này?
Trong bài viết hôm nay, chúng ta sẽ giải thích về cá cược chênh lệch tỷ lệ và lý do tại sao cần có nhiều tài khoản.
